
【导读】作为计算机视觉领域的三大国际顶会之一,IEEE国际计算机视觉与模式识别会议CVPR(IEEE Conference on Computer Vision and Pattern Recognition) 每年都会吸引全球领域众多专业人士参与。由于受COVID-19疫情影响,原定于6月16日至20日在华盛顿州西雅图举行的CVPR 2020将全部改为线上举行。今年的CVPR有6656篇有效投稿,最终有1470篇论文被接收,接收率为22%左右。为此,专知小编提前为大家整理了五篇CVPR 2020场景图神经网络(SGNN)相关论文,让大家先睹为快——3D语义分割、指代表达式推理、图像描述生成、图像处理、时空图。
WWW2020GNN_Part1、AAAI2020GNN、ACMMM2019GNN、CIKM2019GNN、ICLR2020GNN、EMNLP2019GNN、ICCV2019GNN_Part2、ICCV2019GNN_Part1、NIPS2019GNN、IJCAI2019GNN_Part1、IJCAI2019GNN_Part2、KDD2019GNN、ACL2019GNN、CVPR2019GNN、ICML2019GNN
1. Learning 3D Semantic Scene Graphs from 3D Indoor Reconstructions
作者:Johanna Wald, Helisa Dhamo, Nassir Navab, Federico Tombari
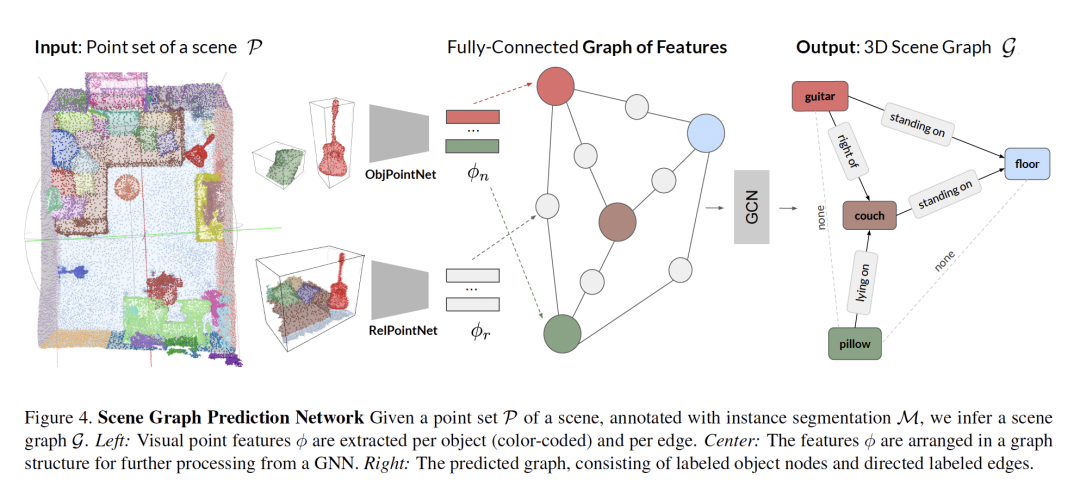
摘要:场景理解(scene understanding)一直是计算机视觉领域的研究热点。它不仅包括识别场景中的对象,还包括识别它们在给定上下文中的关系。基于这一目标,最近的一系列工作解决了3D语义分割和场景布局预测问题。在我们的工作中,我们关注场景图,这是一种在图中组织场景实体的数据结构,其中对象是节点,它们的关系建模为边。我们利用场景图上的推理作为实现3D场景理解、映射对象及其关系的一种方式。特别地,我们提出了一种从场景的点云回归场景图的学习方法。我们的新体系结构是基于PointNet和图卷积网络(GCN)的。此外,我们还介绍了一个半自动生成的数据集3DSSG,它包含了语义丰富的三维场景图。我们展示了我们的方法在一个领域无关的检索任务中的应用,其中图作为3D-3D和2D-3D匹配的中间表示。
网址:
https://arxiv.org/pdf/2004.03967.pdf
2. Graph-Structured Referring Expression Reasoning in The Wild
作者:Sibei Yang, Guanbin Li, Yizhou Yu
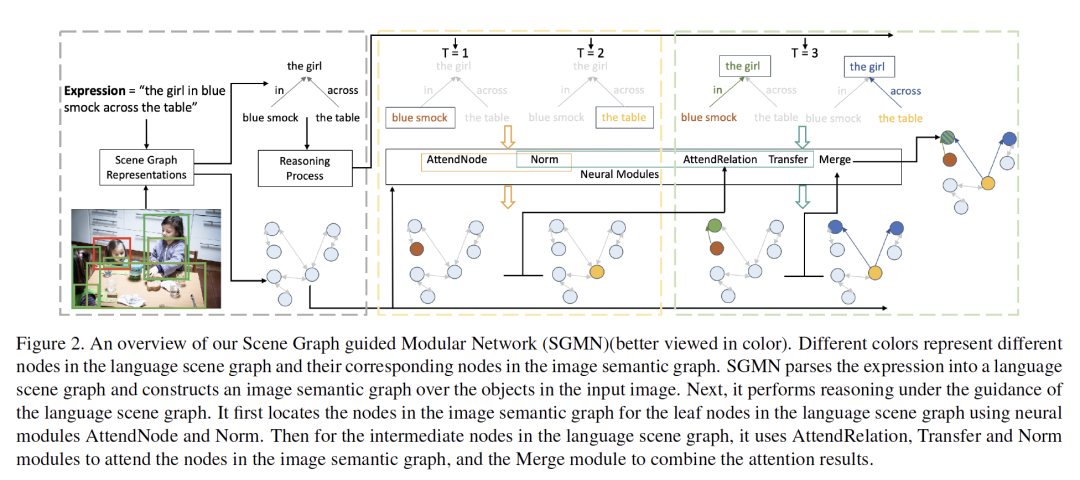
摘要:Grounding referring expressions的目标是参照自然语言表达式在图像中定位一个目标。指代表达式(referring expression)的语言结构为视觉内容提供了推理的布局,并且该结构对于校准和共同理解图像与指代表达式是十分重要的。本文提出了一种场景图引导的模块化网络(SGMN),它在表达式的语言结构指导下,用神经模块对语义图和场景图进行推理。特别地,我们将图像(image)建模为结构化语义图,并将表达式解析为语言场景图。语言场景图不仅对表达式的语言结构进行解码,而且与图像语义图具有一致的表示。除了探索指代表达式基础的结构化解决方案外,我们还提出了Ref-Reasning,一个用于结构化指代表达式推理的大规模真实数据集。我们使用不同的表达式模板和函数式程序自动生成图像场景图上的指代表达式。该数据集配备了真实世界的可视化内容以及具有不同推理布局的语义丰富的表达式。实验结果表明,SGMN不仅在新的Ref-Reasning数据集上的性能明显优于现有的算法,而且在常用的基准数据集上也超过了最先进的结构化方法。它还可以为推理提供可解释的可视化证据。
网址:
https://arxiv.org/pdf/2004.08814.pdf
代码链接:
https://github.com/sibeiyang/sgmn
3. Say As Y ou Wish: Fine-grained Control of Image Caption Generation with Abstract Scene Graphs
作者:Shizhe Chen, Qin Jin, Peng Wang, Qi Wu
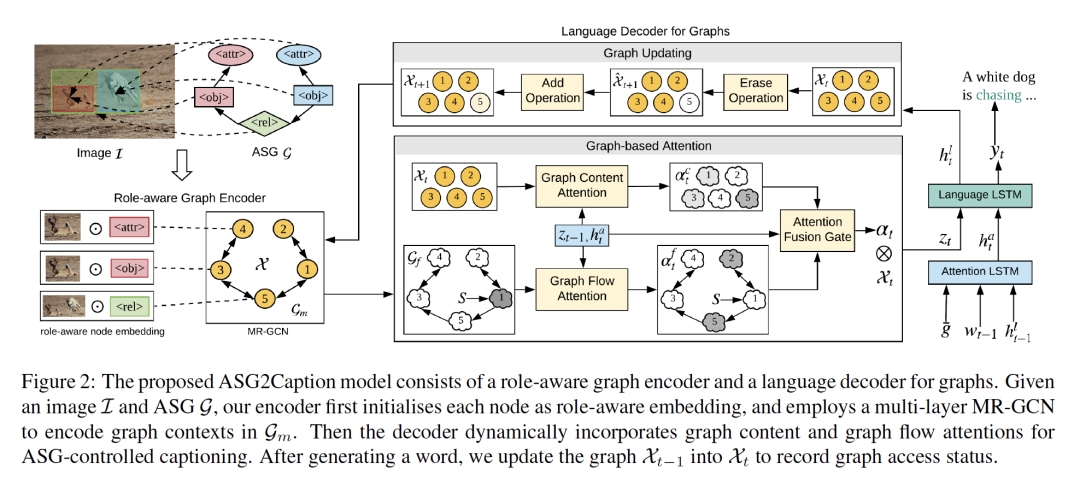
摘要:人类能够随心所欲地用粗到细的细节来描述图像内容。然而,大多数图像字幕模型是意图不可知的(intention-agnostic),不能主动根据不同的用户意图生成各种描述。在这项工作中,我们提出了抽象场景图(ASG)结构来在细粒度层次上表示用户意图,并控制生成的描述应该是什么和有多详细。ASG是一个由三种类型的抽象节点(对象、属性、关系)组成的有向图,它们以图像为基础,没有任何具体的语义标签。因此,这些节点可以很容易通过手动或自动获得。与在VisualGenome和MSCOCO数据集上精心设计的基线相比,我们的模型在ASG上实现了更好的可控性条件。它还通过自动采样不同的ASG作为控制信号,显著提高了字幕多样性。
网址:
https://arxiv.org/pdf/2003.00387.pdf
4. Semantic Image Manipulation Using Scene Graphs
作者:Helisa Dhamo, Azade Farshad, Iro Laina, Nassir Navab, Gregory D. Hager, Federico Tombari, Christian Rupprecht
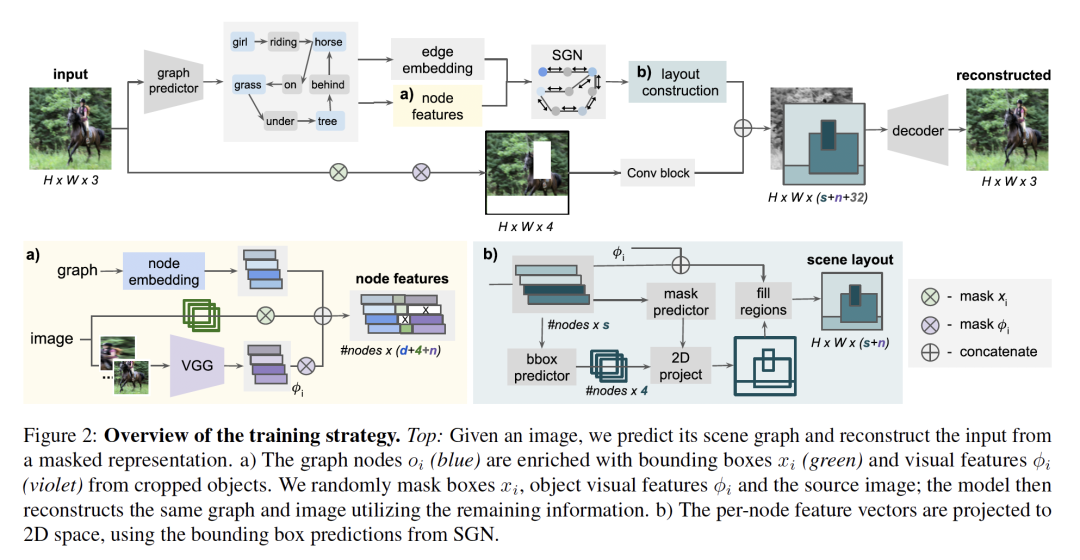
摘要:图像处理可以被认为是图像生成的特例,其中要生成的图像是对现有图像的修改。在很大程度上,图像生成和处理都是对原始像素进行操作的任务。然而,在学习丰富的图像和对象表示方面的显著进展已经为主要由语义驱动的诸如文本到图像或布局到图像生成之类的任务开辟了道路。在我们的工作中,我们解决了从场景图进行图像处理的新问题,在该问题中,用户可以仅通过对从图像生成的语义图的节点或边进行修改来编辑图像。我们的目标是对给定constellation中的图像信息进行编码,然后在此基础上生成新的constellation,例如替换对象,甚至改变对象之间的关系,同时尊重原始图像的语义和样式。我们引入了空间语义场景图网络,该网络不需要直接监督constellation变化或图像编辑。这使得从现有的现实世界数据集中训练系统成为可能,而无需额外的注释工作。
网址:
https://www.researchgate.net/publication/340523427_Semantic_Image_Manipulation_Using_Scene_Graphs
代码链接:
https://he-dhamo.github.io/SIMSG/
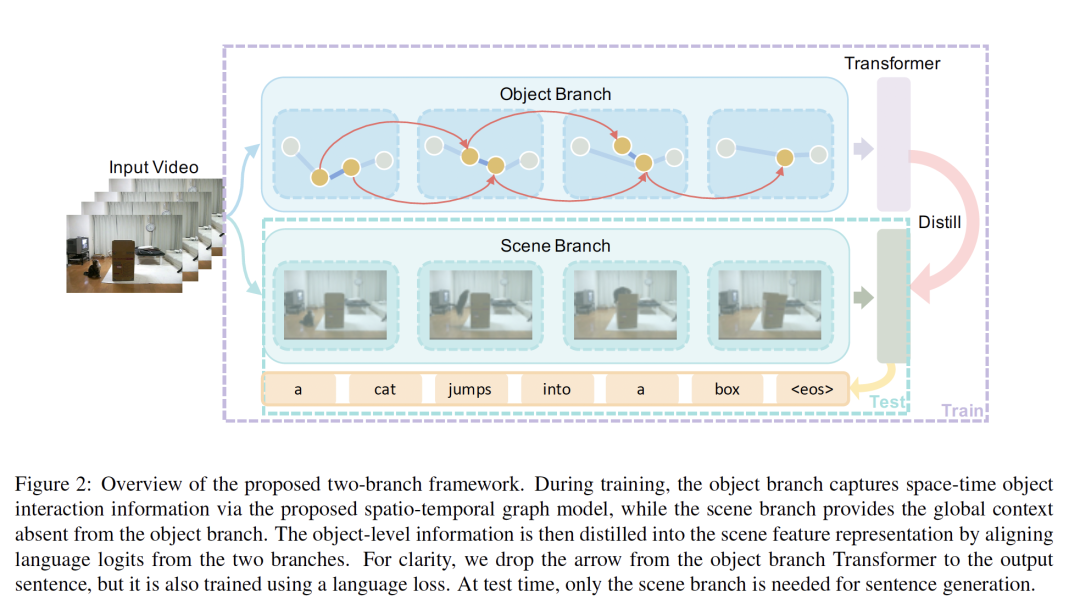
5. Spatio-Temporal Graph for Video Captioning with Knowledge Distillation
作者:Boxiao Pan, Haoye Cai, De-An Huang, Kuan-Hui Lee, Adrien Gaidon, Ehsan Adeli, Juan Carlos Niebles
摘要:视频描述生成是一项具有挑战性的任务,需要对视觉场景有深刻的理解。最先进的方法使用场景级或对象级信息生成字幕,但没有显式建模对象交互。因此,它们通常无法做出基于视觉的预测,并且对虚假相关性敏感。在本文中,我们为视频字幕提出了一种新颖的时空图模型,该模型利用了时空中的对象交互作用。我们的模型建立了可解释的连接,并且能够提供明确的视觉基础。为了避免对象数量变化带来的性能不稳定,我们进一步提出了一种对象感知的知识提炼机制,该机制利用局部对象信息对全局场景特征进行正则化。通过在两个基准上的广泛实验证明了我们的方法的有效性,表明我们的方法在可解释的预测上产生了具有竞争力的性能。
网址:

