题目: Uniform convergence may be unable to explain generalization in deep learning
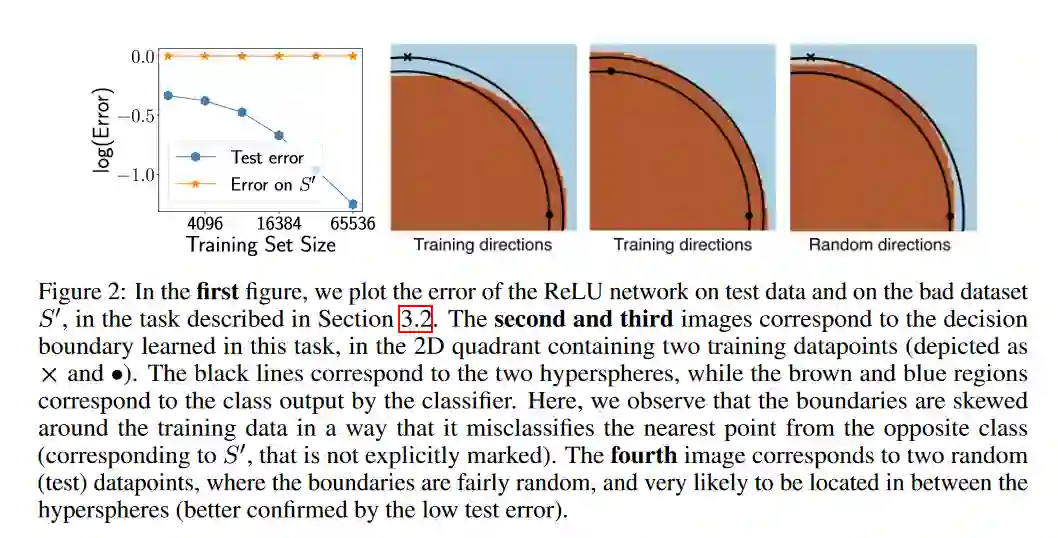
摘要: 为了解释过参数化深度网络的泛化行为,最近的工作发展了各种各样的深度学习泛化界,所有这些都基于一致收敛的基本学习理论技术。虽然众所周知,许多现有的边界是数值大的,通过大量的实验,我们揭示了这些边界的一个更关注的方面:在实践中,这些界限可以{EM EM增加与训练数据集的大小。在我们的观察结果的指导下,我们给出了超参数线性分类器和梯度下降(GD)训练的神经网络的例子,其中一致收敛证明不能解释泛化“”——即使我们尽可能充分考虑GD{尽可能的\em}的隐式偏差。更准确地说,即使我们只考虑GD输出的一组分类器,它们的测试误差在我们的设置中小于一些小的值,我们也表明,对这组分类器应用(双边)一致收敛只会产生大于的空泛化保证。通过这些发现,我们对基于一致收敛的泛化界的能力提出了质疑,以提供一个完整的图片说明为什么过度参数化的深层网络泛化良好。
作者简介: Vaishnavh Nagarajan,卡内基梅隆大学(CMU)计算机科学系五年级的博士生。他的兴趣在于机器学习和人工智能的算法和基础方面。目前,他正在研究如何在有监督和无监督的学习环境中从理论上理解深度学习中的泛化。在过去,他从事过更传统的学习理论、多智能体系统和强化学习。个人主页:http://www.cs.cmu.edu/~vaishnan/home/index.html
J. Zico Kolter,卡内基梅隆大学计算机科学系助理教授,研究集中在可持续性和能源领域的计算方法上,集中在这些领域机器学习、优化和控制中出现的核心挑战上。个人主页:https://www.csd.cs.cmu.edu/people/faculty/zico-kolter