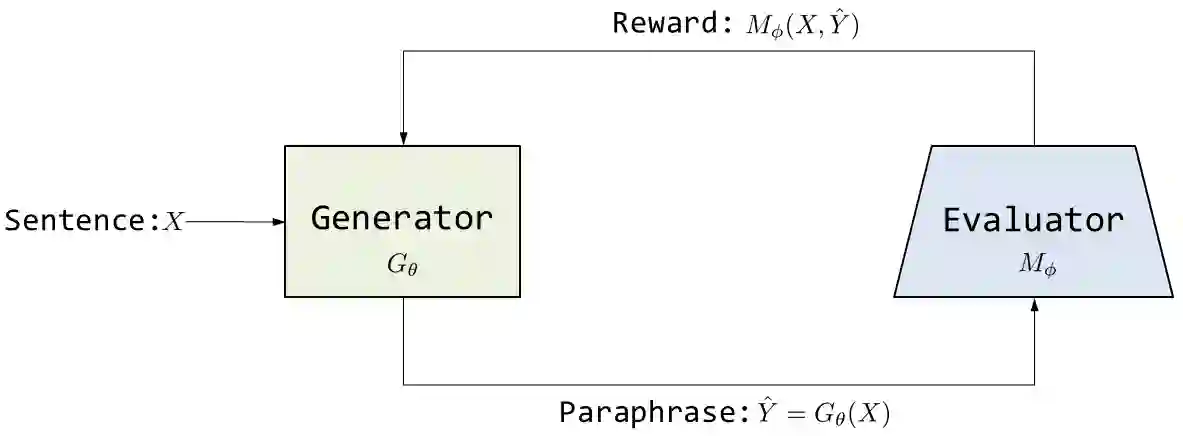
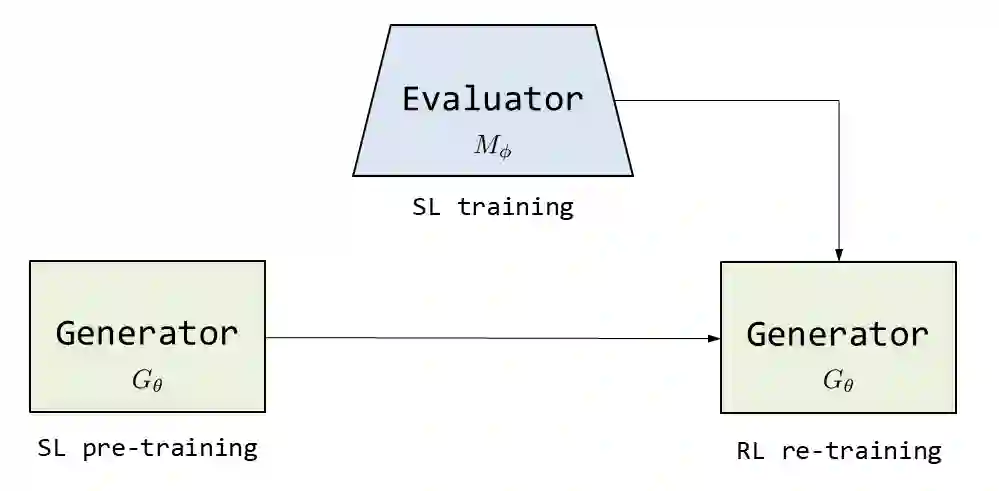
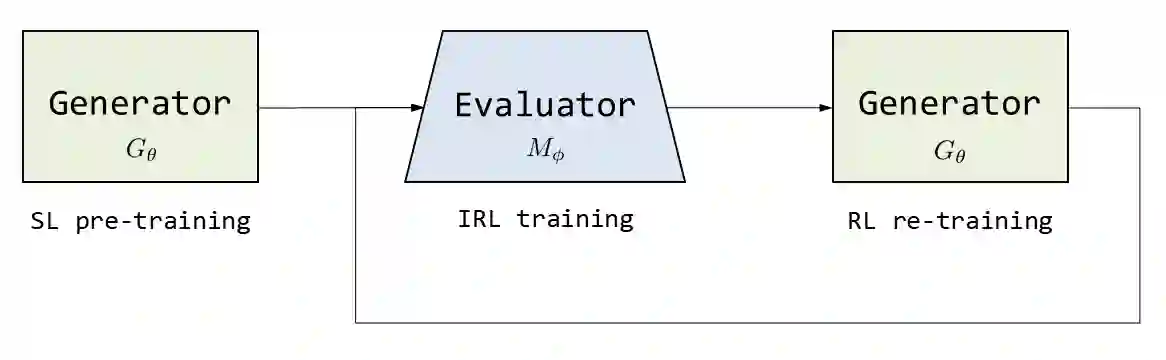
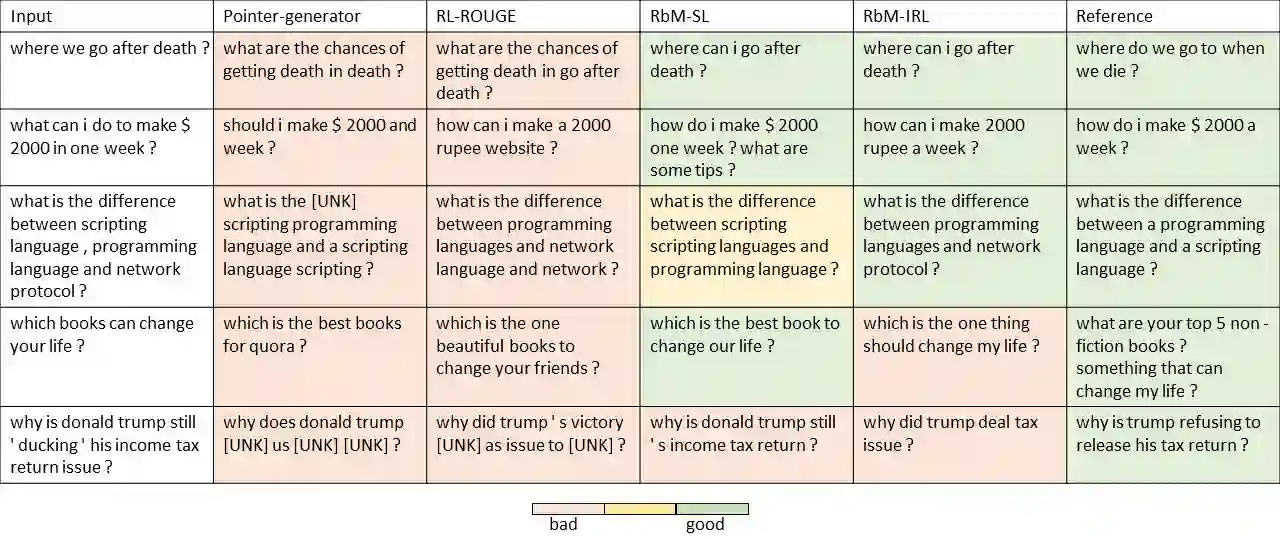
Automatic generation of paraphrases from a given sentence is an important yet challenging task in natural language processing (NLP), and plays a key role in a number of applications such as question answering, search, and dialogue. In this paper, we present a deep reinforcement learning approach to paraphrase generation. Specifically, we propose a new framework for the task, which consists of a \textit{generator} and an \textit{evaluator}, both of which are learned from data. The generator, built as a sequence-to-sequence learning model, can produce paraphrases given a sentence. The evaluator, constructed as a deep matching model, can judge whether two sentences are paraphrases of each other. The generator is first trained by deep learning and then further fine-tuned by reinforcement learning in which the reward is given by the evaluator. For the learning of the evaluator, we propose two methods based on supervised learning and inverse reinforcement learning respectively, depending on the type of available training data. Empirical study shows that the learned evaluator can guide the generator to produce more accurate paraphrases. Experimental results demonstrate the proposed models (the generators) outperform the state-of-the-art methods in paraphrase generation in both automatic evaluation and human evaluation.
翻译:在自然语言处理(NLP)中,从某一句中自动生成自动引言句是一项重要而又具有挑战性的任务,在诸如问答、搜索和对话等若干应用中发挥着关键作用。在本文中,我们提出了对引言生成的深度强化学习方法。具体地说,我们为这项任务提出了一个新的框架,由\ textit{generator}和\textit{evulator}组成,两者都是从数据中学习的。作为从序列到序列学习模式的生成者,可以产生给定一个句子。作为深相匹配模型设计的评价者,可以判断两句子是否是彼此的引言。先是深层学习,然后通过强化学习进一步调整生成者,而评价者则给予奖励。关于评价者的学习,我们根据现有培训数据的类型,分别提出基于监督学习和反强化学习的两种方法。Empiricalalal研究显示,作为深层次评价者可以指导发电机制作更精确的引言词句。实验性结果显示,在生成模型的自动模型中,在生成模型时,在自动成型方法中展示。