层级强化学习概念简介
通用人工智能
Artificial General Intelligence

本文对层级增强学习(HRL)的一些概念(包括封建学习、选择框架、分层抽象机器、MAXQ等)进行扼要介绍,并对研究方向提供参考建议。
Hierarchical Reinforcement Learning
层次强化学习(HRL)是一种计算方法,旨在通过学习在不同的时间抽象层次上操作来解决这些问题。
为了真正理解在学习算法中需要一个层次结构,以及为了在RL(增强学习)和 HRL 之间架起桥梁,我们需要记住我们正在努力解决的问题: MDPs (马可夫决策过程)。 HRL 方法学习由多个层组成的策略,每个层负责时间抽象的不同级别的控制。 事实上,HRL 的关键创新之处在于扩展了一系列可用的操作,这样受训者不仅可以选择执行基本操作,而且还可以执行宏操作(即一系列较低级别的操作)。 因此,对于随着时间推移而延长的行动,我们必须考虑到决策时刻之间所经过的时间。 幸运的是,MDP 规划和学习算法可以很容易地扩展以适应 HRL。
Feudal Learning
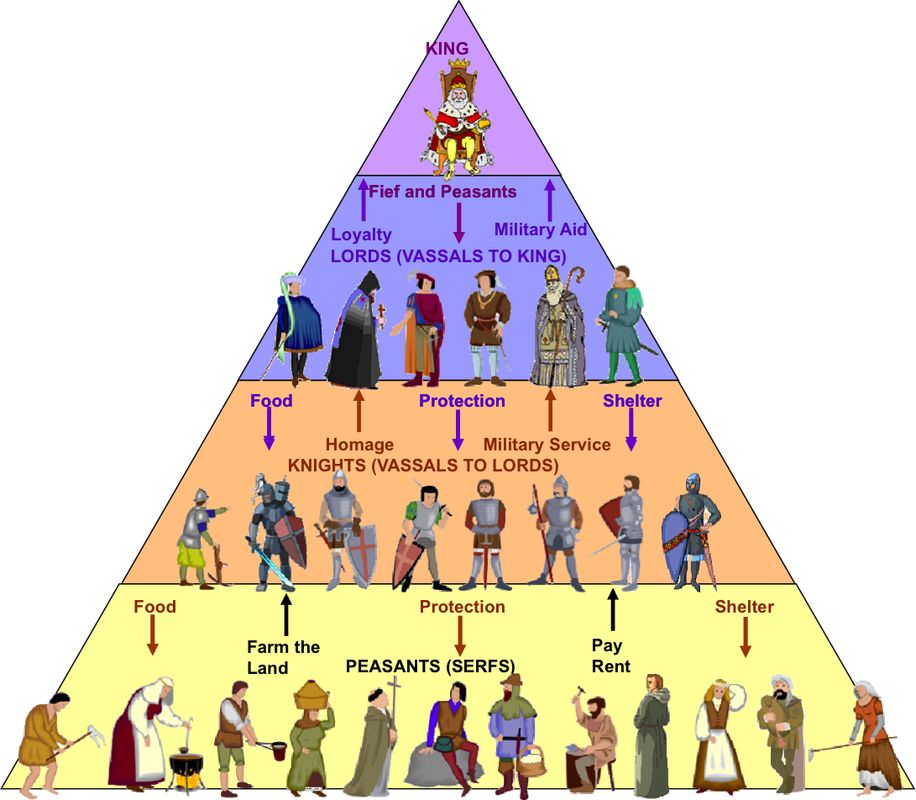
受中世纪欧洲封建制度的启发,这种 HRL 方法演示了如何创建一种管理学习等级制度,在这种制度下,领主(或管理者)学会将任务(或次级目标)分配给他们的农奴(或次级管理者) ,而农奴(或次级管理者)则学会满足他们。 次级经理学会最大限度地增强他们的命令(如下图中的黑色圆圈)。
在实践中,封建学说利用了两个概念:
信息隐藏: 管理层以不同的分辨率观察环境
隐藏奖励: 管理者和"员工"之间通过目标进行沟通——达到目标会得到奖励
信息和奖励隐藏的一个值得注意的效果是,管理者只需要知道他们自己的任务选择尺度的系统状态。 他们也不知道他们的工人做出了什么样的选择来满足他们的命令,因为系统设置不需要学习。
遗憾的是,Feudal Q-learning 学习算法只适用于特定类型的问题,并不能收敛到任何定义良好的最优策略。 但它为许多其他贡献铺平了道路。
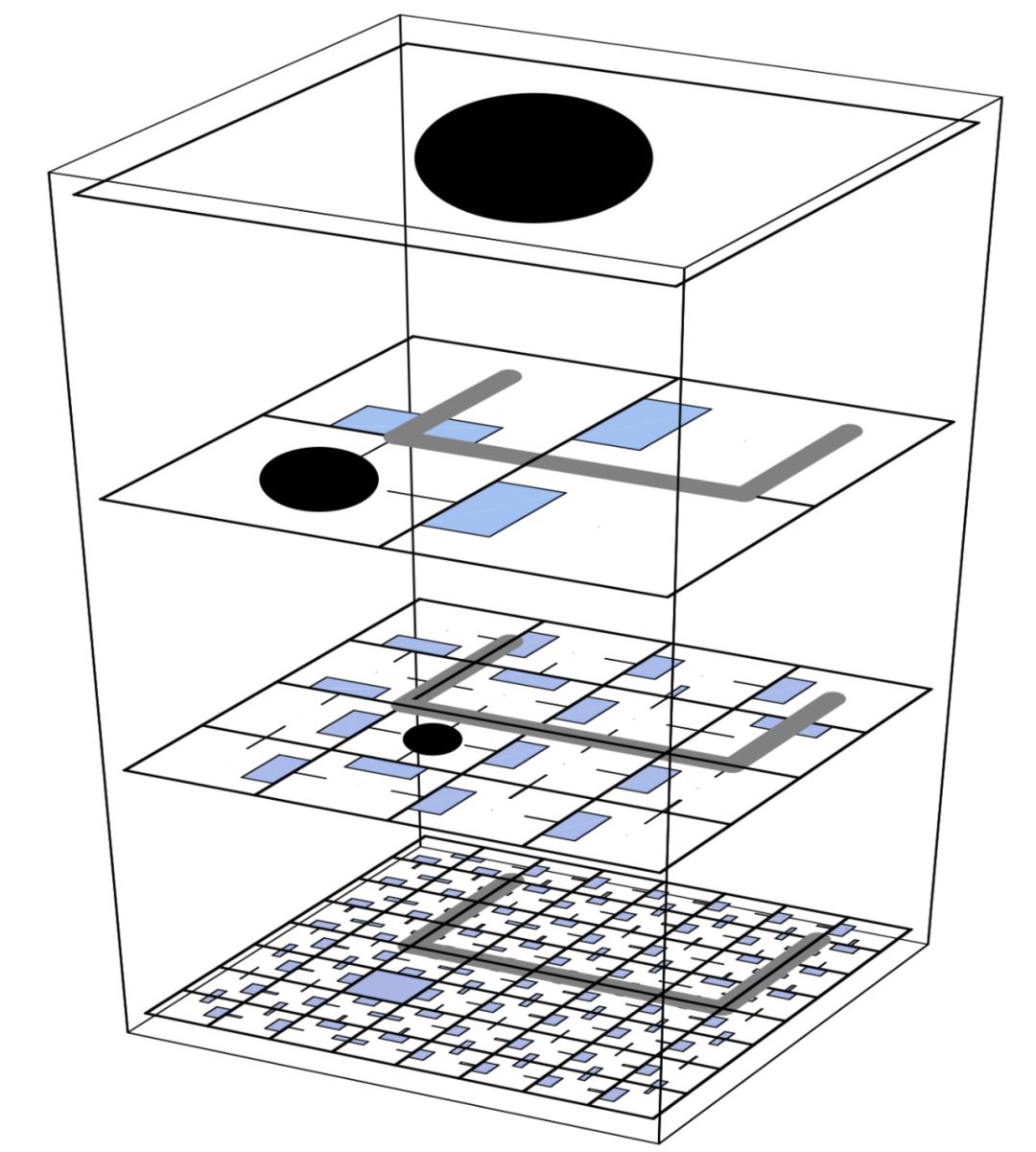
Options Framework
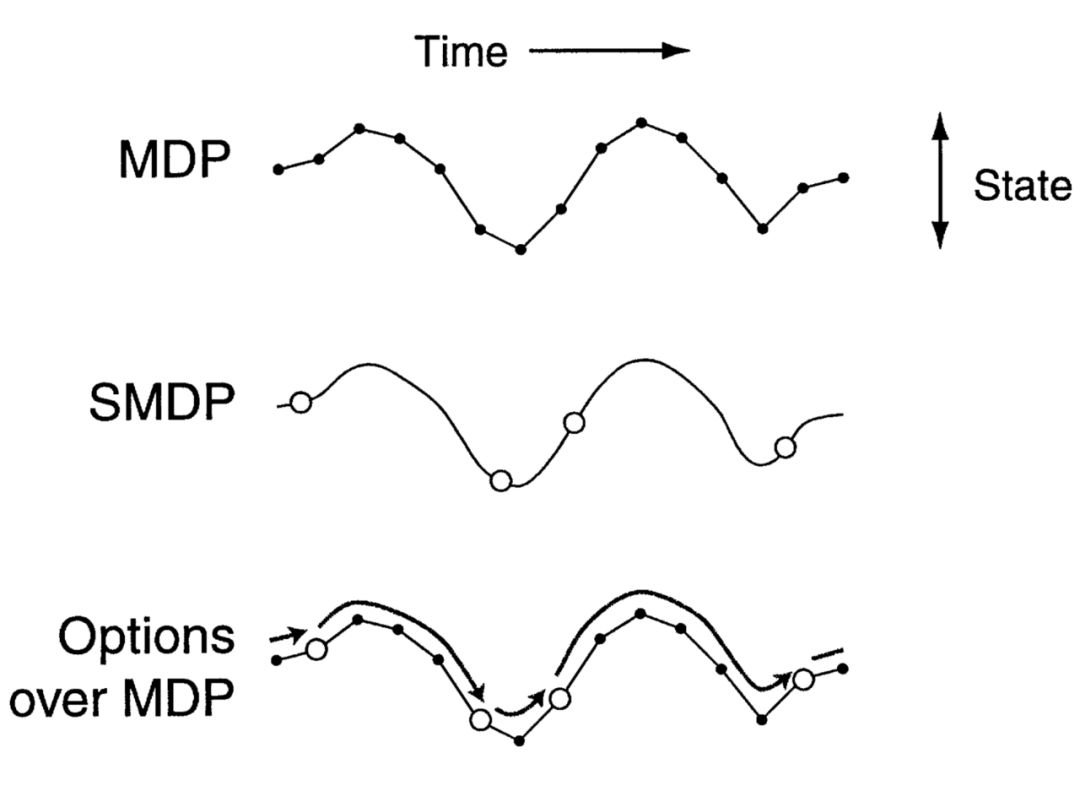
HRL最著名的理论架构可能是选项框架。与封建学习不同,如果动作空间由原始动作和选项组成,那么遵循选项框架的算法被证明会收敛到最优策略。 否则,它仍将趋于一致,但将成为一个等级最优的政策。
由此产生的想法是,一个选择框架由两个层次组成:
-
底层是一个次级政策(进行环境观察、输出动作、一直持续到终止)
-
顶层是选项之上的政策(进行环境观察、产出次级政策、一直持续到终止)
“选项”非常容易实现,而且在界定高级别能力方面非常有效,这反过来又提高了收敛速度。 此外,选项本身可用于定义选项层次结构。 然而,自然而然地,选项增加了 MDP 的复杂性。 它们也没有明确地解决任务分割的问题。
Hierarchical Abstract Machines
分层抽象机(HAMs)由不确定的有限状态机组成,它们的转换可能会调用较低级别的机器(最佳操作尚未决定或学习)。 机器是由有限状态自动机(Finite State Automaton,FSA)表示的部分策略。 有四种机器状态:
1. 动作状态——在环境中执行一个动作
2. 调用状态——作为子例程执行另一台机器
3. 选择状态——概率性地选择下一个机器状态
4. 停止状态——停止机器的执行并将控制返回到前一个调用状态
我们可以将政策视为程序。 对于 HAMs 来说,学习发生在机器内部,因为机器只是部分定义的。该方法是将所有的机器分解,并考虑问题的状态空间 <s, m> 其中 m 是机器状态,s 是底层 MDP 的状态。
当机器遇到 Call 状态时,它以确定的方式执行它应该执行的机器。 当它遇到 Stop 状态时,它只是将命令发送回父计算机。 与直接在 MDP 上进行学习的情况不同,在 HAM 框架中,学习只在 Choice 状态下进行。 因此,学习发生的状态空间可能比实际状态空间小。
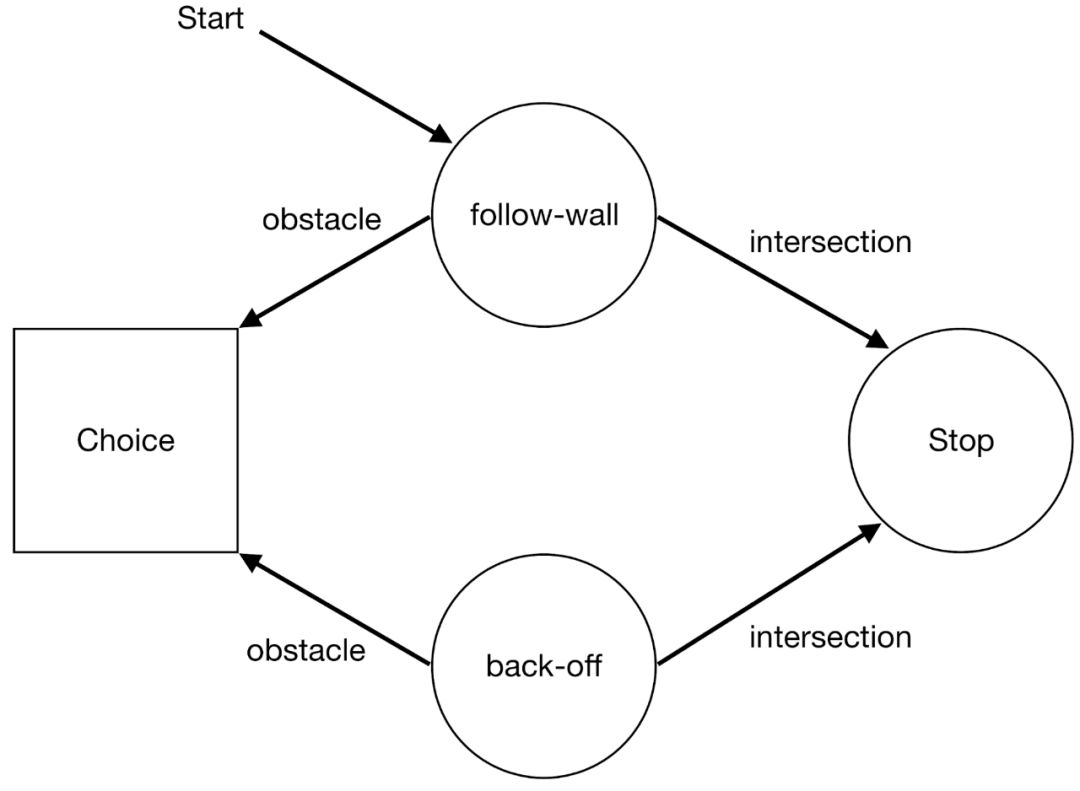
在上面的例子中,每次遇到障碍时,机器进入一个 Choice 状态,在这个状态中,机器要么选择"跟随墙机器"(它只是在某个方向上不断地跟随墙) ,要么选择"后退机器"(后退并继续执行)。因此,学习机的策略是以多大的概率来决定调用哪台机器。
由于上述所有原因,HAM 框架通过限制可实现策略的类,为我们提供了简化 MDP 的能力。 与期权框架类似,它也具有最优性的理论保证。 主要的问题是 HAMs 的设计和实现非常复杂,并且没有多少重要的应用程序可用。
MAXQ
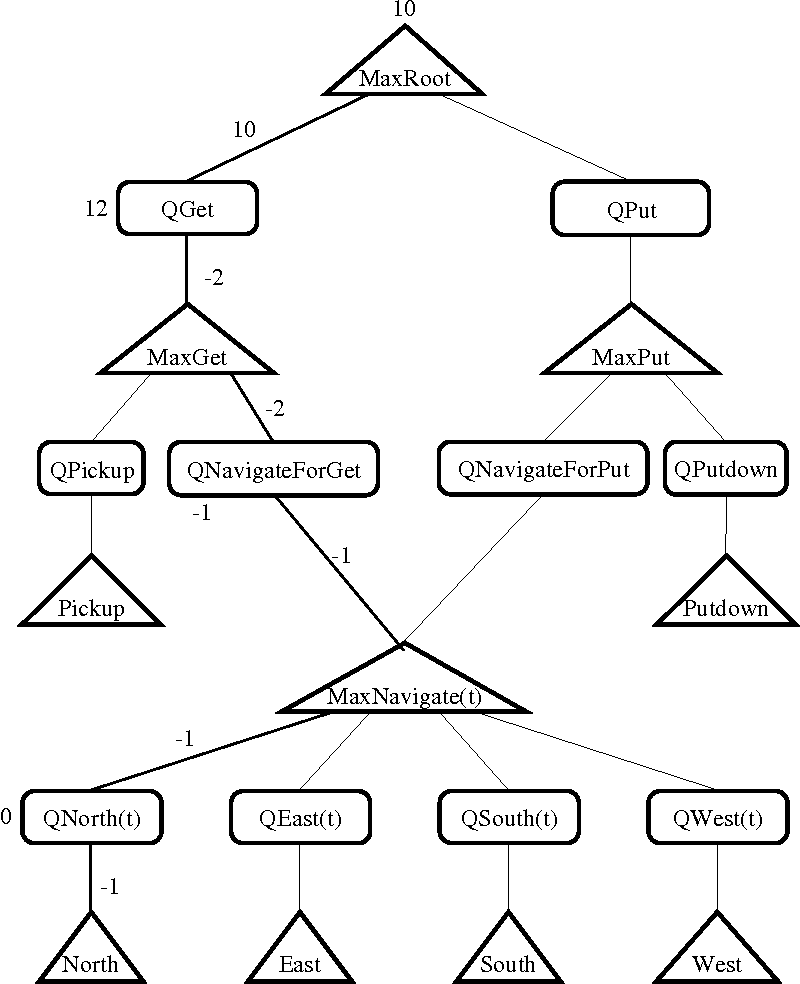
MAXQ 是一种深度学习算法,通过将状态-动作对的 Q 值分解为 Q(p,s,a) = V(a, s) + C(p,s,a)得到任务的层次结构,其中 V(a,s) 是执行状态为 a 的动作时期望得到的总奖励(经典Q-learning中的Q), C(p,s,a) 是父任务执行后期望得到的总奖励。 事实上,动作 a 可能不仅包含一个原始动作,而且还包含一系列动作。
本质上,MAXQ 框架可以理解为将 MDP 的值函数分解为较小的组成 MDPs 的值函数的组合,一个有限的子任务集合,其中每个子任务被形式化为:
-
一个终止信号
-
一系列的动作
-
一个准奖励
在这方面,MAXQ 框架与封建 Q-Learning 有关联。
尽管如此,MAXQ 相对于其他框架的优势在于它学习了一个递归最优策略,这意味着父任务的策略在子任务的学习策略下是最优的。 也就是说,任务的策略是与上下文无关的: 每个子任务都是在不参考执行它的上下文的情况下优化解决的。 虽然这并不意味着它将找到一个最佳的政策,但它打开了国家抽象和更好的转移学习的大门,并可以提供许多其他任务的共同宏观行动。
Outlook
Options 框架和 MAXQ 分解都为算法设计人员提供了强大的工具来分层地解决问题。 如果你对这方面的研究感兴趣,读者可以选择自己认为最有前途的方法,或者你认为最能从改进中获益的方法。 然后,读者可以开发新的假设来进行基准测试,使用开源代码(比如 HIRO、 HAC、 MLSH、 HSP)来构建新的想法,或者通过从上面提到的许多贡献中汲取灵感,自己实现一个系统。
总而言之,如果不能恰当地衡量这些发展,就无法量化这些发展,而且我有一种感觉,即仍然缺乏有效地衡量 HRL 以及更广泛的 RL 所取得进展的工具。 幸运的是,这个研究领域的社区也在积极地研究这些问题。当然,我们有责任认识到我们领域固有的问题,这些问题不是短期的困难,而是长期的进展缓慢。 我们有责任参与解决这些问题,并以可重复的方式为进展作出贡献。
作者简介:Yannis Flet-Berliac 是 Inria SequeL 团队法国里尔北方的大学的博士生。 他的研究项目主要涉及深海强化学习,主要关注随机和非平稳的环境。 在开始攻读博士学位之前,他在法国和丹麦主要从事对话模型、机器翻译和摄影师风格识别方面的工作。

Editor:Zen



学习/创造/分享
通用人工智能-AGI
CONTACT US
骥智智能科技上海有限公司
上海市浦东新区
▼
招贤纳士