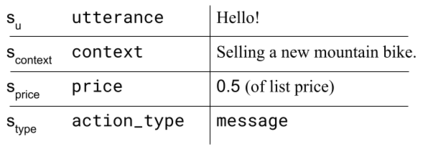
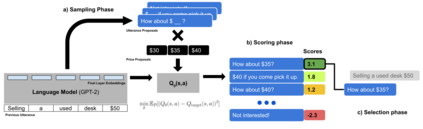
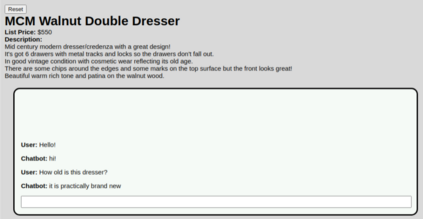
Conventionally, generation of natural language for dialogue agents may be viewed as a statistical learning problem: determine the patterns in human-provided data and generate appropriate responses with similar statistical properties. However, dialogue can also be regarded as a goal directed process, where speakers attempt to accomplish a specific task. Reinforcement learning (RL) algorithms are designed specifically for solving such goal-directed problems, but the most direct way to apply RL -- through trial-and-error learning in human conversations, -- is costly. In this paper, we study how offline reinforcement learning can instead be used to train dialogue agents entirely using static datasets collected from human speakers. Our experiments show that recently developed offline RL methods can be combined with language models to yield realistic dialogue agents that better accomplish task goals.
翻译:就公约而言,为对话者创造自然语言可被视为一个统计学习问题:确定人类提供的数据模式,并产生具有类似统计特性的适当反应;然而,对话也可被视为一个目标导向进程,发言者试图完成具体任务;强化学习算法是专门为解决此类目标导向的问题而设计的,但最直接地通过在人类对话中进行试验和人工学习来应用RL的方法代价高昂;在本文件中,我们研究如何利用从人类演讲者那里收集的静态数据集完全利用离线强化学习来培训对话者。我们的实验表明,最近开发的脱线学习算法可以与语言模型相结合,产生更能实现任务目标的实际对话者。