自从十年前发现针对机器学习模型的对抗性攻击以来,对抗性机器学习的研究已经迅速演变为一场永恒的战争,捍卫者寻求提高ML模型对对抗性攻击的鲁棒性,而对手则寻求开发能够削弱或击败这些防御的更好攻击。然而,这个领域几乎没有得到ML从业者的支持,他们既不关心这些攻击对他们在现实世界中的系统的影响,也不愿意牺牲他们模型的准确性来追求对这些攻击的鲁棒性。
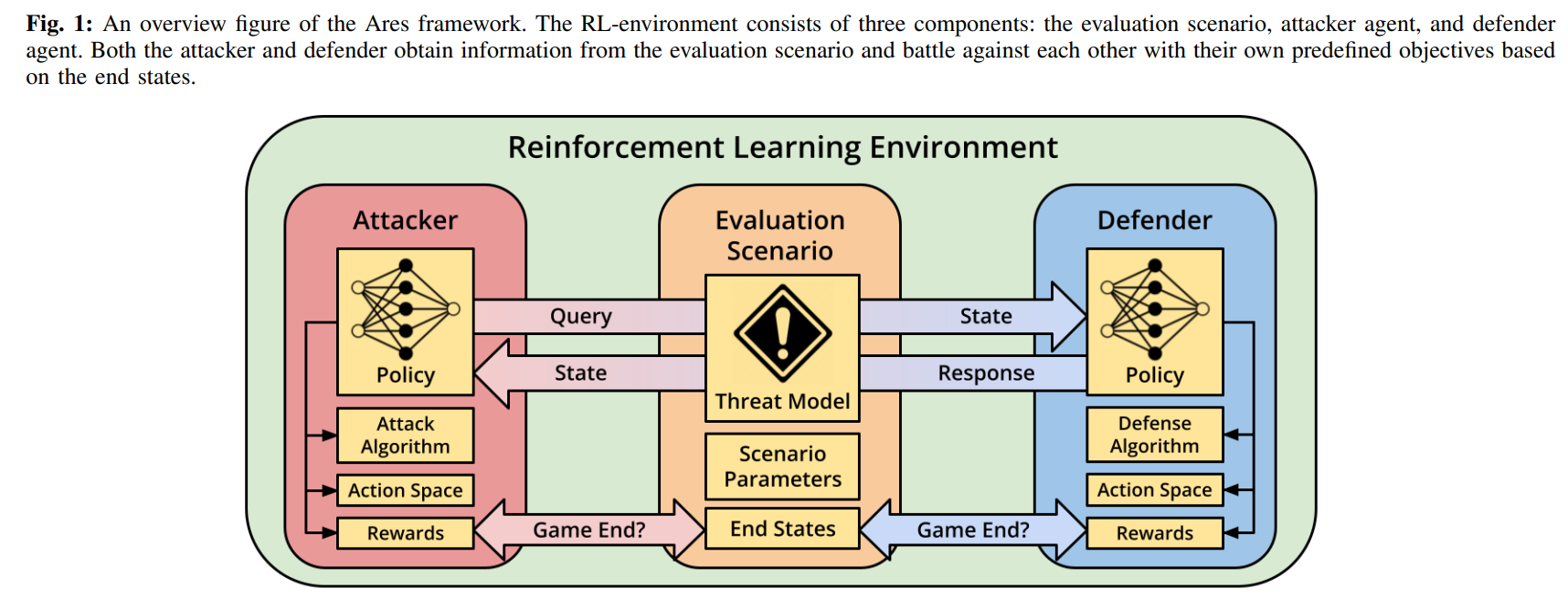
在本文中,我们旨在设计和实现Ares,这是一个对抗性ML的评估框架,允许研究人员在一个现实的兵棋推演环境中探索攻击和防卫。Ares将攻击者和防御者之间的冲突设定为强化学习环境中目标相反的两个Agent。这允许引入系统级的评估指标,如失败的时间和评估复杂的策略,如移动目标防御。我们提供了我们初步探索的结果,涉及一个白盒攻击者对一个经过对抗性训练的防御者。

I. 前言
人工智能系统的大规模采用,促使人们重新审视人工智能算法的可靠性、隐私性和安全性。在安全性方面,人们很早就发现,基于图像的人工智能算法很容易受到一类对抗性规避攻击[1],[2]。在这种攻击中,对手会引入人眼无法察觉的少量噪声,以便在推理过程中可靠地诱发错误分类。自其发现以来,大量的研究提出了许多经验性的防御策略,如改造模型的输入[3],修改神经网络结构[4],以及在另一个训练数据集上训练网络[5]。尽管有大量的工作,无论是开发新的对抗性攻击还是提出新的防御措施,包括强大的物理世界攻击[6],对抗性威胁模型对ML从业者来说仍然没有动力。在一项小型的行业调查中,Kumar等人[7]发现,虽然大多数被调查的组织都知道对抗性样本,但他们说 "对抗性ML是未来的",并且缺乏研究和缓解这种攻击的工具。
我们认为,有两个关键问题阻碍了人们接受对抗性规避攻击作为一种威胁:(1)大多数先前的工作所使用的非激励性威胁模型;(2)缺乏评估复杂的对抗性攻击者和防御者互动的工具。遵循Kerckhoffs原则,对抗性攻击和防御的研究主要采用白盒威胁模型,即对网络和防御参数的完全了解。在这种视角下,许多提议的防御措施被证明是无效的,因为拥有完美知识的攻击者可以适应防御[8]。然而,这样一个强大的威胁模型只能由具有内部访问AI算法和训练数据的攻击者复制。在真实的部署场景中,一个组织主要关注的是其人工智能系统对外部攻击者的安全性。
尽管没有认识到对抗性ML是一种威胁,但对抗性攻击库已经兴起,使ML从业者能够研究目前最先进的攻击和防御算法。一些例子包括多伦多大学的CleverHans[9],麻省理工学院的鲁棒性包[10],图宾根大学的Foolbox[11],以及IBM的对抗性鲁棒性工具箱(ART)[12]。每个库都定义了一个统一的框架,从业者可以通过它来评估使用自己的人工智能系统的攻击或防御的有效性。不幸的是,这种评估在本质上是有限的,因为评估的威胁模型受到攻击算法的限制。此外,攻击者和防御者都被认为是静态的。他们不会根据对方的行动来修改自己的行为,因此,报告的有效性是误导性的,不能转化为现实世界中的有意义的有效性概念。
在本文中,我们描述了一个新的评估框架--Ares,它将对抗性攻击场景表现为攻击者和防御者之间复杂的、动态的互动。我们将攻击者和防御者之间的冲突作为强化学习(RL)环境中的两个独立Agent来探索,其目标是对立的,为对抗性ML评估创造了一个更丰富、更真实的环境。通过利用这种RL环境,我们能够将攻击者或防御者的策略(RL策略)调整为静态的、随机的、甚至是可学习的。Ares还允许调查白盒和黑盒威胁模型,从先前评估的局限性中汲取灵感。
作为其首次亮相,我们使用Ares重新审查了白盒场景下的集合/移动目标防御(MTD)框架的安全性,并强调了这种设置的脆弱性。使用自然训练和对抗性训练模型的不同组合,Ares评估发现,一般来说,攻击者总是获胜,对抗性训练只能稍微延迟攻击者的成功。正如之前的工作所讨论的,攻击者的成功主要是由于对抗性例子的可转移性[2]。我们通过Ares的视角对这一现象进行了更深入的调查,发现网络之间共享的损失梯度,无论训练方法或模型架构如何,都是罪魁祸首。然后,我们讨论了如何根据这一发现改进MTD,以及我们下一步如何通过Ares在黑盒威胁模型中评估MTD和其他先前的工作。
在本文中,我们做出了以下贡献:
-
我们开发了Ares,一个基于RL的对抗性ML的评估框架,允许研究人员在系统层面上探索攻击/防御策略。
-
利用Ares,我们重新审查了白盒威胁模型下的集合/移动目标防御策略,并表明这种失败的根本原因是由于网络之间的共享损失梯度。
Ares框架在https:// github.com/Ethos-lab/ares上公开提供,我们将继续开发更多的功能和改进。