

作者:
Erik Lin-Greenberg:麻省理工学院
Reid B.C. Pauly:布朗大学
Jacquelyn G. Schneider:斯坦福大学
摘 要
政治科学家越来越多地将兵棋推演融入他们的研究。通过部署原创游戏或利用档案兵棋材料,研究人员可以研究难以观察证据的罕见事件或主题。然而,学者们对如何将这种新的方法论应用于政治科学研究几乎没有相关指导。本文评估了政治科学家如何将兵棋推演作为一种学术探究的方法,并着手建立国际关系中兵棋推演的研究议程。我们首先将兵棋推演与其他方法论区分开来,并强调它们的生态有效性。然后,我们绘制了研究人员如何构建和运行自己的游戏或从档案兵棋推演中提取理论开发和测试的图表。在此过程中,我们解释了研究人员在使用兵棋推演进行研究时如何解决招募、偏见、有效性和普遍性问题,并确定评估兵棋推演作为调查工具的潜在好处和缺陷的方法。我们认为,兵棋推演为政治科学家研究国际关系子领域内外的决策过程提供了独特的机会。
关键词
兵棋推演,博弈,方法论,档案,实验,网络,新兴技术,核扩散
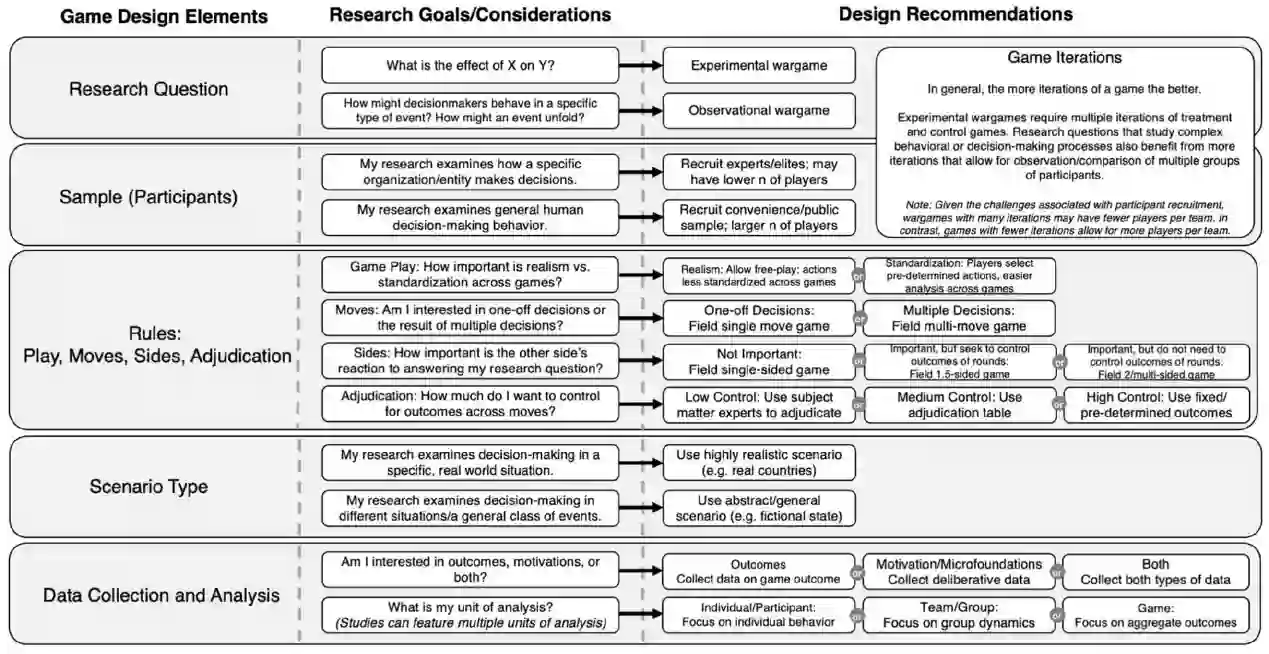
图 兵棋推演开发指导框架
1 背 景
人类行为和决策是国际关系 (IR) 中最持久难题的核心。然而,有关决策的数据很难获得,特别是涉及罕见事件以及与安全和外交决策相关的精英决策者。近年来,兵棋推演作为一种产生和获得这些行为洞察力的方式重新燃起(Bartels,2020 年;Colbert 等人,2017 年;Dorn 等人,2020 年;Hirst,2020 年;Jensen 和 Valeriano , 2019 ; Pauly, 2018 ; Reddie 等人, 2018 ; Schneider, 2017)[1]。作为政策制定者的领地,国际关系学者开始利用历史兵棋推演中的档案数据,并运用自己的兵棋推演来测试决策和冲突动态的理论。总之,这个崭露头角的学术问题使用兵棋推演来探索支撑外交政策决策的机制和逻辑。
关于此问题快速增长的研究兴趣是三个因素的产物。首先,冷战时期国防兵棋推演的解密为学者们提供了新的和独特的档案材料,以更好地了解有关核使用和冲突升级等主题的历史决策。其次,在过去的二十年中,政治科学家越来越多地转向综合数据生成过程,例如调查和实验室实验(Hyde,2015 年)。这种行为转向强调了实验设计,政治科学家在他们自己的游戏中应用了这种设计。第三,政治科学家对理论背后的微观基础越来越感兴趣(Kertzer,2017)。通过阐明决策过程,兵棋推演为研究人员提供了一种新的方法论工具,用于探索和测试 IR 理论所依赖的机制,可能比其他研究方法提供更深入的见解。
兵棋推演可能为学者们提供了一种很有前途的工具,可以以创造性的方式回答问题,但在该领域采用兵棋推演方法或数据之前,我们需要更好地了解博弈对政治科学的承诺和陷阱。兵棋推演与其他研究方法有何不同?兵棋推演可以产生哪些类型的见解和数据,学者如何最好地利用它们进行研究?研究人员在设计自己的游戏时应该考虑什么?将兵棋推演作为 IR 研究的一种方法应该解决哪些方法问题?
本文绘制并评估了政治科学家如何将兵棋推演作为一种学术探究的方法,并着手制定 IR 兵棋推演的研究议程。我们探索研究人员现场兵棋推演的发展以及使用档案兵棋推演材料来产生对决策的见解。我们考虑了博弈对理论开发和测试的效用;检查偏见、有效性和普遍性问题;并描述博弈如何阐明支撑核心 IR 理论的微观基础。
文章分五个部分进行。首先,我们定义兵棋推演并确定不同的博弈类型。其次,我们回顾了一系列关于兵棋推演价值的主张,这些主张将其与其他政治科学研究方法区分开来。第三,我们讨论了研究人员如何以社会科学规则为指导,评估设计选择的成本和收益。第四,我们描述了档案中出现的历史兵棋推演材料,如何最好地使用这些文献证据,并确定历史兵棋推演可以教给我们哪些关于研究人员现场兵棋推演的最佳实践。最后,我们概述了兵棋推演研究议程,探索兵棋推演如何补充其他研究方法,为正在进行的辩论做出贡献,并提出具体问题,以帮助研究人员更好地理解可以从兵棋推演中得出的推论。
2 什么是兵棋推演?
兵棋推演的使用可以追溯到几千年前,古罗马、早期伊拉克和中国都有兵棋推演的证据(Caffrey,2019 年)。随着普鲁士开发的Kriegspiel棋盘游戏,兵棋推演在现代战争行为中发挥了核心作用,这是一种模拟战斗训练军官的棋盘游戏(Schuurman,2019年;Wilson,1968年)。一个世纪后,美国在第一次世界大战和第二次世界大战期间将兵棋推演用于军事规划,成为海军在太平洋地区取得成功的关键部分(Lillard,2016年)。在冷战期间,美军再次转向兵棋推演来了解核革命的影响(Pauly, 2018;Schelling, 1987)。柏林墙倒塌后,美国的国防兵棋推演仍在继续,旨在测试有关战争和援助采购决策的新想法(Krepinevich和Watts,2015年)。
尽管发展历史悠久,但并不清楚什么是“兵棋推演”(Sepinsky,2021年)。虽然兵棋推演是为了准备战斗而出现的,但它们的用途超出了对战争的研究。政府使用游戏来模拟自然灾害和评估经济合作(Abbasi等,2012;Smith和Bell,1992);商业顾问使用兵棋推演来测试新的商业战略(Oriesek和Shwarz,2008年);学者应用游戏来研究人类行为如何影响各种社会和政治现象(Banks等人,1968年;Camerer,2011 年;Fiorina 和 Plott,1978 年)。例如,Thomas Schelling 关于强制的工作在很大程度上受到他设计的国防部兵棋推演的启发(Schelling,1987 年),而 Schelling 的同时代人使用模拟来探索冲突和核使用(Bloomfield 和 Whaley,1965 年;Brody,1963 年;Hermann,1967年)。此后,学者们使用游戏中嵌入实验来测试对冲突引发的解释(Johnson等人,2006 年;McDermott 等人,2008 年)以及国内政治讨价还价(Hamman等人,2011 年;Huckfeldt等人,2014年)。最近,政治科学家使用兵棋推演来研究数据稀少的现象,例如新兴技术对IR的影响(Jensen and Banks, 2018; Jensen and Valeriano, 2019; Lin-Greenberg, 2020; Pauly, 2018; Reddie et al., 2018; Schneider, 2017; Schneider et al., 2021)。
虽然通常被称为“模拟”或“演习”,但兵棋推演不同于计算机模拟战斗、以实际军队为特色的实地演习或有组织的头脑风暴会议。此外,大多数传统兵棋推演也不是旨在研究因果关系的实验室实验。相反,兵棋推演是具有四个特征的交互式事件:人类玩家、沉浸在场景中、受规则约束以及受基于结果的驱动。
首先,兵棋推演涉及人类玩家。正如Perla (1990 : 164) 解释的那样,“兵棋推演是人类互动的练习。它的长处是探索人类决策的作用和潜在影响” 。这种人类特征使得兵棋推演成为因变量或假设因果机制与人类行为有关的研究的理想选择。事实上,博弈可以帮助阐明微观基础,或源自个体人类行为的较低层次的机制,它们是许多学术理论的基础(Kertzer,2017年)。兵棋推演的人为因素将它们与计算机模拟或计量经济学“博弈”区分开来,其中模型模拟假定人类行为。
其次,兵棋推演将人类参与者置于模拟现实世界决策的场景中(Pettyjohn,2019年)。现实的表示和环境的整合产生了兵棋推演场景的厚度,并将它们与越来越多地用于 IR 研究的实验室和调查实验区分开来。这些模拟的决策环境,类似于参与者经常体验的环境,可以诱导玩家的行为方式与他们在相似的现实世界环境中的行为密切相关[2]。兵棋推演设计师必须仔细平衡抽象,这使游戏更容易执行,现实主义是兵棋独有的,并可能最终增加游戏发现的稳健性。
第三,兵棋推演具有规定人类玩家如何与场景互动的规则。规则可能是严格的,其中玩家有一组有限的动作,或者允许自由博弈,玩家几乎没有限制。这些规则可以塑造玩家的行为和结果,最终影响观察者从博弈中得出的结论。因此,规则会产生复杂的设计权衡。例如,免费游戏会使复制变得困难,而僵化游戏更有可能不自然地限制结果。尽管规则是博弈与许多模拟、模型和实验共有的特征,但兵棋推演(尤其是具有多个动作、玩家或团队的兵棋推演)通常使用更复杂的规则来管理团队如何互动,同时允许更广泛的行为选择,因此,导致结果差异更大。
兵棋推演区别于大多数其他国际关系研究方法的第四个特征是其基于结果的产出的经验性质。正如巴特尔斯所说,兵棋推演必须让人类玩家“沉浸在基于一组隐含或明确规则的竞争环境中,应对其行为的潜在后果”(Bartels,2020)。这些后果,例如“输掉”一场兵棋推演或在前一轮做出的决定会影响下一轮,被认为会激励参与者更深入地考虑他们的决定。在更常见的研究方法中,例如调查实验,参与者通常不会面对真实或模拟的后果。兵棋推演,在他们最好的情况下,超越了玩家的“游戏”结果,以感受和内化他们行为后果。最后一个特征的成功与游戏设计师在前三个特征之间进行权衡有关,包括使用正确的玩家、创建适当的场景和建立有用的规则。
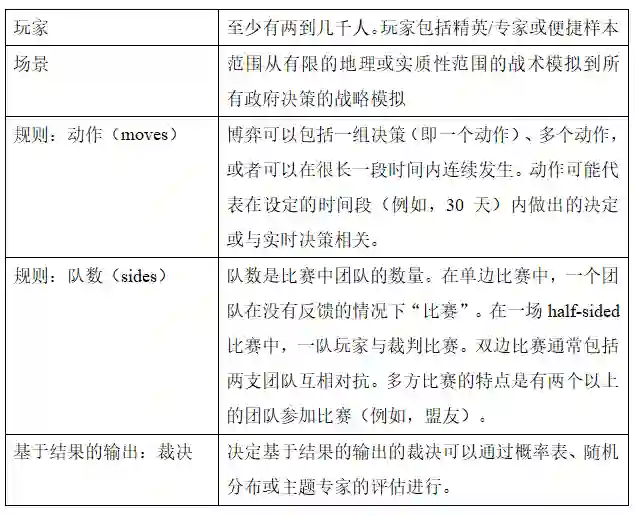
总之,兵棋推演是互动场景,让人类玩家沉浸其中,他们根据给定的规则做出决定,并对他们的选择的后果做出反应。这四个特征的变化导致了各种看起来截然不同的“兵棋推演”。例如,兵棋推演包括棋盘游戏、少数玩家参与的战术桌面演习,以及数百名参与者参与的政治军事游戏。它们可以面对面、虚拟或使用某种混合组合进行,并具有不同的规则(表1)。学者们需要了解这些博弈特征如何影响可以从博弈中得出的关于 IR 理论和决策的结论;我们将在后续部分中探讨。
表1 博弈的特征
3 为什么需要兵棋推演?
上面我们概述了兵棋推演是什么,但为什么研究人员会选择兵棋推演而不是其他方法或数据源?下面,我们确定了关于兵棋推演作为研究决策的研究工具有用性的四个命题:(1)兵棋推演比其他方法更能让研究对象身临其境,(2)经常玩兵棋推演的精英参与者使得比其他方法更接近实际决策者,(3)参与者之间的交互更好地代表了现实世界的决策,以及(4)兵棋推演向玩家展示了他们自己决策的后果。总之,这些命题表明,使用和分析兵棋推演的主要价值不是生成关于结果的新的或更好的数据,而是理解导致这些结果的行为和选择。兵棋推演不能预测冲突或危机中会发生什么,但它们可以告诉我们为什么以及如何发生一种结果或另一种结果。虽然在从业者社区中被广泛接受(Bartels, 2020; Oberholtzer et al., 2019; Perla, 1990; Perla and McGrady, 2011; Wong et al., 2019),但这些关于兵棋推演作为研究工具的价值的假设大多未经检验。我们在本节中列出它们,以开始概述关于兵棋推演与其他方法和档案数据源的独特作用的前瞻性研究议程。在结论中,我们评估了研究人员如何研究这些命题,并描述了学者可能使用兵棋推演解决的问题类型。
总体而言,这四个命题中的每一个都提高了兵棋推演作为一种研究方法的生态有效性。生态效度(心理学研究中的一个常见概念),关注测试条件下的行为反映现实世界行为的程度。换句话说,更生态有效的研究设计应该对实际行为提供更可靠的见解。为了获得高生态效度,心理学家关注三个关键维度。首先,测试环境应该包括在自然环境中发生的特征——例如时间限制和干扰——而不是表现出精简实验室设置的更加不切实际的性质。二、刺激——例如信息注入——在模拟环境中应该与现实世界的刺激相似。第三,参与者在测试中可以做出的行为反应和行为应该代表他们在现实世界中可以做出的行为。来自过于不切实际或涉及不自然刺激和行为反应的环境的测试信息可能会限制从研究中得出结论(Gouvier等,2014年)。
在兵棋推演中实现高生态有效性需要模拟条件,以反映真正的政策制定者在实际危机中必须应对的压力、激励和信息环境的类型。然后,这些条件允许参与者提出类似于他们在现实世界中提出的解决方案。如果兵棋推演具有较高的生态效度,学者们应该能够利用兵棋推演真实地模拟和研究外交政策决策过程。事实上,生态有效性使其他领域的专业人士能够将博弈和模拟用于培训目的。例如,使用准确的现实世界参数进行编程的飞行模拟器具有很高的生态有效性,并且是一种更便宜、更容易、更安全的方式来训练飞行员并了解他们的决策[3]。虽然跨学科的文献继续对其定义进行辩论(Baumeister 和 Vohs,2007;Brunswik,1947:276;Schmuckler,2001),但我们认为生态效度是外部效度的关键要素——研究结果在研究背景之外的普遍性(Findley等人,2020年)[4]。
3.1 命题 1:兵棋推演比其他方法更具沉浸感,因此在生态上更有效
作为兵棋推演专家Perla 和 McGrady (2011: 113) 断言:兵棋推演“吸引玩家参与并构建他们的故事;他们确实将玩家置于故事之中。” 这是兵棋推演优于其他不复制真实世界决策环境的方法的论据。就生态效度的维度而言,沉浸式旨在提供一个有效刺激的有效测试环境。理想情况下,玩家沉浸在其中,以至于他们暂时忘记或忽略了他们正在被研究的事实,而是关心他们在兵棋推演中的进展。因此,兵棋推演寻求创造沉浸式环境,在这种环境中,参与者不扮演游戏玩家的角色,而是内化他们过去和未来对类似现实生活场景的反应。从历史上看,兵棋推演反映了政府参与者的真实经历。在古巴导弹危机期间,一位曾参与过托马斯·谢林兵棋推演的国防官员表示,“这场危机确实证明了Schelling的兵棋推演是多么逼真”,一位同事对此回应说,“不”,兵棋推演“证明了这场古巴危机是多么不切实际”(Schelling and Ferguson, 1988: 10)。
当然,兵棋推演可能会被剥夺细节并失去其身临其境的品质,但随后该活动是否仍可被视为兵棋推演就成了问题。例如,调查实验优先考虑内部有效性和控制,但往往缺乏这种沉浸式互动或实际决策设置的应激源(Barabas和Jerit,2010 年)。相比之下,通常持续数小时或数天并具有大量细节的博弈,可以通过提供逼真的场景、创造参与者可以与另一个团队赢或输的条件以及允许参与者之间的扩展互动来引起参与者的支持。投入时间和精力参与其中的玩家,可能会比不那么投入的研究对象更好地理解场景并更关心其结果。因此,他们可能会更周到地对给定的场景做出反应。此外,兵棋推演通常要求玩家在信息过多(或过少)、时间限制和情感负担的情况下做出决策,从而产生了 McDermott (2002) 所说的“实验现实主义”。事实上,学者们发现“综合体验”向研究对象展示身临其境的小说或视频,会触发类似于现实世界决策的认知过程(Daniel 和 Musgrave,2017;Miller,2020)。最后,兵棋推演超越了许多调查实验,要求参与者扮演决策者的角色并回答我会做什么,而不是我会支持其他人做什么?[5]
3.2 命题 2:更具代表性的样本使兵棋推演更具生态有效性
兵棋推演可能比其他研究方法提供更多的见解,仅仅是因为它们传统上招募了包括决策者和军官在内的专家参与者。学者们通常认为,当研究样本反映感兴趣的人群时,研究提供了最有用的见解(Dietrich 等人,2021;Hyde,2015;McDermott,2002)。然而,国际关系学者越来越多地转向更大的在线和学生便利样本进行实证研究。虽然这种方法允许进行可重复的统计分析,从而克服因果推理的基本问题并能够研究公众偏好,但如果受试者不能代表实际的政策制定者,便利样本可能会产生对政府决策的有限见解(Dietrich 等人,2021 年);Oberholtzer 等人,2019 年)。
相比之下,精英兵棋推演的特点通常与便利样本相反——参与者被故意招募是因为他们的实质性知识或他们在现实世界决策中的经验。这种招募策略可以产生高度真实的样本。然而,即使是这些现实的样本也可能包括显着影响决策的经验和世界观的变化。例如,奥巴马政府的国家安全专家在做决定时会考虑与特朗普政府的国家安全专家相同的因素吗?因此,这些精英研究对象的代表性可能会提高兵棋推演的生态有效性,但是——如果只招募有限数量的参与者来玩少量的兵棋——研究人员仍然需要清楚地解释从研究结果中得出的推论的局限性。
即使精英参与者的数量很少并且有针对性的招募,精英兵棋推演参与者的独特性仍然可以提供重要的分析见解。例如,参与者在游戏中的审议可能会揭示精英在做决定时强调或不强调的因素。例如,规范或道德对于冲突决策有多重要?参与者将哪些国际政治信念带入决策?他们在做决定时是否讨论过心智模型、历史类比或其他启发式方法?由于精英参与者在玩研究人员和政府赞助的游戏时可以利用他们的实质性知识和专业知识,因此这些游戏的见解对于 IR 理论测试可能比非专家玩的游戏更有用。
3.3 命题 3:兵棋推演中的群体互动比收集个人偏好的实验或调查更能代表现实世界的决策
大多数兵棋推演和其他合成数据生成过程之间的一个显着区别是群体在决策中的作用。兵棋推演本质上是多玩家的努力,而大多数调查实验和许多实验室实验都收集个体参与者的反应。最终在兵棋推演期间形成决策的团队内部和团队之间的玩家互动非常重要,因为现实世界的外交政策决策很少由一个人做出(Kerr 和 Tindale,2004 年;Mintz 和 Wayne,2016 年;Saunders,2017 年)。大多数兵棋推演中的组级交互提供了一个独特的机会来研究决策如何展开,并通过比其他研究方法更好地模拟实际决策过程和行为反应来潜在地提高生态有效性。情绪、狂妄自大、沟通不畅、地位、声誉、多样性、性别、经验和鹰派等因素会影响兵棋推演期间的团队动态和决策,让研究人员有机会探索这些重要(但难以收集)的变量如何影响外围策略 ( Wang et al., 2020)。兵棋推演讨论还可以揭示团队如何根据团队成员的性格或特征进行自我排序以及分配或推迟决策责任。事实上,一位在 1960 年兵棋推演中的精明报告员指出,政策重量级人物沃尔特·罗斯托(Walt Rostow)在美国队“做了大约 75% 的谈话”((Bloomfield,1960 年)。相比之下,调查和许多实验往往忽视群体动态,并通过衡量个人层面的偏好来概括外交政策决策。
3.4 命题 4:兵棋推演向玩家展示后果,创建关于结果和决策的更生态有效的数据
博弈可能更有可能反映现实世界的决策,因为它们要求玩家做出响应或导致基于结果的输出的选择[6]。兵棋推演的这种体验品质,要求玩家在模拟挑战之后调整策略,超越了对迭代后果或未来阴影的担忧。反对派将政治-军事信号作为“感受对方可能接受或拒绝的过程”(Schelling 和Ferguson, 1988: 1)所做的远不止决定如何在实验室中分配一美元。事实上,这些决策逻辑可能类似于 Hayward Alker 所描述的参与囚徒困境游戏的玩家的“内心独白”,揭示了人类如何解释自己和他人的行为(Alker,1985 年)。
首先,兵棋推演通常允许玩家“赢”或“输”,至少相对于其他参与者而言。正如一位兵棋推演实践者所说,“兵棋推演是一种人类活动。当人们在游戏中输球时,他们会感到失落。当他们获胜时,他们会很兴奋”(McGrady,2019)。在这里,结果的引入再次以可以塑造行为反应的方式提供了一个更生态有效的测试环境。其次,这个命题断言,这种失落或兴奋感的强度随着研究对象在他们的策略上投入的努力而增加。将一群人长时间放在一起可以通过将玩家更多地投入到游戏中来增加这些后果的显着性,而不是通过在线、电话或邮件进行的调查实验。因此,游戏允许研究人员检查参与者为获胜而采取的权衡、选择和风险。
这四个命题表明,兵棋推演为研究人员提供了在现实世界数据有限的情况下进行决策的宝贵见解。至关重要的是,兵棋推演的价值不在于确定结果,而在于阐明决策者如何得出这些结果。尽管兵棋推演本质上是对现实的模拟,但我们相信其身临其境的性质、群体互动、后果以及精英样本的使用比其他研究方法更准确地模拟了现实世界的决策环境,从而提高了研究结果相对于其他方法的生态有效性。任何单独的游戏设计都可能会强调某些主张而削弱其他主张——例如,片面的博弈可能会牺牲一些竞争精神,同时赋予群体互动特权——但兵棋推演保留了每个命题的一些价值。在接下来的部分中,我们将绘制出学者如何使用原始兵棋推演和使用档案兵棋推演数据进行研究,并确定在设计游戏和分析游戏数据时如何驾驭这四个命题。
4 学者生成的兵棋推演
学者生成的兵棋推演最适用于回答有关人类决策的问题,无论是关于罕见事件还是难以获得真实世界数据的主题。因此,使用学者生成游戏的现有研究倾向于回答有关新兴技术和核武器的问题(Jensen and Valeriano, 2019; Lin-Greenberg, 2020; Reddie et al., 2018; Schechter et al., 2021; Schneider, 2017; Schneider et al., 2021)。然而,兵棋推演也可用于研究一系列国际关系主题,包括外交政策决策中的群体动态、决策中规范的强度、条约承诺在武力使用决策中的作用、军事力量的发展和效用、经济制裁、对威慑战略相对有效性的看法以及危机信号的准确性。
在本节中,我们整合了来自专业兵棋推演和政治科学研究设计的最佳实践,为学者们开发自己的兵棋推演提供了一个指导框架。在此过程中,我们概述了生态有效性、内部有效性和实施可行性之间的权衡。图1总结了我们的主要设计建议。
图1 游戏设计建议
4.1 游戏设计与迭代
兵棋推演开发的第一步是确定研究问题是否可以通过观察或实验设计得到最好的回答。观察性游戏通常是独立的事件,既不操纵玩家也不操纵他们面临的场景。一个单一的观察游戏通常会在定义的场景中揭示可能的结果,使这种类型的游戏最适合探索一般决策过程或产生假设[7]。相比之下,实验性游戏通过改变感兴趣的关键因素(例如有关场景的细节)来测试假设,从而创建“治疗”和“控制”游戏,使研究人员能够研究特定变量如何影响决策[8]。
游戏的类型通常会影响所需的迭代次数。实验设计的游戏可能需要比观察设计游戏更多的迭代,以评估实验操作是否会导致决策趋势。研究人员越来越多地部署数十到数百个实验性游戏迭代(Jensen 和 Valeriano,2019年;Reddie等人,2018年;Schechter等人,2021年;Schneider 等人,2021年),以识别游戏中的趋势并帮助确保发现不会偶然的结果。
4.2 参与者
对于观察性和实验性兵棋推演来说,比迭代更重要的是玩家选择。在选择样本时,学者们应该问两个问题:(1)我的研究问题是关于特定实体的决策还是关于人类决策?(2) 玩家将代表谁?
如果研究问题是关于特定实体做出的决策,那么在理想情况下,现实世界的决策者会在兵棋推演中“玩”自己。这样的构造将是最生态有效的。然而,由于高级官员甚至很少有时间参加政府赞助的高调游戏,因此实践者兵棋推演往往依赖于代理人,包括前政策制定者或在职的下级官员,他们具有足够的主题和组织专业知识。一些研究人员参与的游戏依赖于这种类型的样本,吸引了来自军方、私营部门和政府的玩家(Lin-Greenberg, 2020; Schneider, 2017; Schneider et al., 2021)。研究人员还缩短了游戏时间或部署虚拟游戏,以减轻精英参与者的负担。无论精英招募方法如何,研究人员都需要确定他们样本的人口统计学或意识形态特征是否会限制从调查结果中得出的结论。例如,一个主要由几十年前在政府任职的参与者组成的团队的行为可能与最近任职的官员不同。
或者,如果研究问题是关于更一般的决策或人类行为——例如人类如何响应不同的信号或威胁——研究人员可能能够证明招募更容易获得的便利样本是合理的(Goldblum 等人,2019年)。事实上,越来越多的研究表明,便利样本的偏好通常与更具代表性或精英样本的偏好相似(Berinsky 等人,2012 年;Kertzer,2020 年)。理想情况下,研究人员应尽可能招募更能代表感兴趣的目标人群的样本。然而,考虑到精英招募的两大挑战(Dietrich 等人,2021 年;Kertzer 和 Renshon,2022 年) 以及即使在精英人群中的重要变化,研究人员也不应该依赖“精英”作为参与者选择的充分特征。相反,研究人员应该识别精英样本和便利样本中可能影响兵棋推演行为的特征,并研究数据以了解这些特征在兵棋推演中的影响。
研究人员面临的一项特殊招募挑战是在兵棋推演中寻找代表外围决策者的参与者,这些兵棋以特定的盟军或敌对行动者为特色。理想情况下,这些参与者应该对他们被要求代表的人物有深入的知识。这有助于确保他们在兵棋推演中的行动保持在行动者可能实际做出的合理决定的范围内。然而,即使是专家也可能将他们自己的参考框架镜像到外围人物(Jervis,1976)。为了降低这种风险,研究人员可以尝试招募实际上来自他们被要求代表的州的参与者。由于这并不总是可能的,从业者的游戏通常依赖于地区专家,包括学者和外交官。或者,兵棋推演设计师可以为扮演外围人物的非区域专家提供详细的赛前准备材料,甚至是一本规则书,说明外围人物可能遵循的合理策略或原则。诚然,高手并不具备应对国外危机行为的水晶球,但这不是游戏的目的。设计师应该追求现实主义,而不是预测。在分析数据时,研究人员必须承认这些招聘挑战可能如何影响参与者的行为。
参与者的数量受玩家在游戏中所代表的人的影响,因此也受团队构建方式的影响。这种选择应该根据研究问题是关注群体做出的决定还是特定个人的角色来决定。例如,在某些游戏中,研究问题询问组织或团体的角色——例如军事指挥部的互动——因此需要足够多的玩家来模仿这些组织的功能。在其他情况下,玩家代表特定的角色——例如总统或内阁部长——或更抽象的职位不明确“官员”。在决定如何设计这些团队以及是否分配特定角色时,研究人员应考虑研究问题如何影响玩家在游戏中做出的决策类型(Bartels 等人,2013 年:42-46)。例如,研究对核攻击的反应的游戏可能需要代表多个机构的玩家,而不仅仅是国防机构。
游戏设计也会影响样本量。例如,具有多种治疗游戏的实验性游戏通常比不太复杂的游戏需要更多的参与者。同样,具有多面性或模拟详细组织过程的游戏通常比单面或高度抽象的游戏需要更多的玩家。对于理想的参与者人数没有硬性规定,但游戏应该包括足够的参与者,以允许将兵棋推演与其他研究方法区分开来的互动。
4.3 规则:动作(moves)、队数(sides)、裁决(adjudication)
研究人员接下来必须制定他们的游戏结构规则——有多少步数、多少边(即团队)以及游戏将包括多少裁决?首先,为了确定游戏需要多少轮(即动作),学者们应该询问他们是对一次性决策(例如,反击或不反击的选择)感兴趣,还是对多个决策的结果感兴趣(例如,长期危机或权力转移)。额外的回合可以通过引入切实的结果来增强现实性,但也会削弱对混淆因素的控制,特别是在以多次并行迭代为特色的实验游戏中。
研究人员还必须确定队数(即多少团队参加游戏)。单方面的游戏可能足以回答不取决于其他参与者的即时反应的问题——例如,我对恐怖袭击的即时反应是什么?这些游戏需要较少的参与者和较简单的裁决过程。相比之下,对于取决于对方反应的研究问题,例如策略对威慑的有效性,学者们应该考虑一个半边的游戏,其中对方的行动由游戏裁判员编写,或者两个/涉及多队玩家的多方比赛。这些提供了更大的活力,并允许研究人员探索演员之间的互动。然而,队数越多,研究人员在多个游戏迭代之间的控制就越少。
大多数具有不止一个动作的游戏都需要游戏组织者的裁决。这种对回合之间结果的“裁判”会影响后续回合的展开。在具有多个游戏迭代的项目中,这可能会在游戏之间引入差异,从而导致游戏不再具有直接可比性。在某些情况下,跨博弈差异可能对研究人员有用——例如,研究危机早期阶段的变化如何产生不同的下游效应。然而,这些差异可能会引入混杂因素,从而难以隔离第一轮之后引入的额外操作的影响。
学者们可以根据他们的研究目标从一系列裁决技术中汲取经验。对比较大量游戏感兴趣的研究人员可能会使用公式化的判断——比如概率表或随机生成的结果。这种方法允许跨游戏的标准化规则;但是,它会降低真实感。希望最大限度地提高玩家参与度的学者可以选择免费游戏裁决,专家根据主题知识确定结果。这可能会为玩家创造一个更有活力的游戏,支持生态有效性,但可能会引入裁判者的偏见,使得难以在多个游戏中复制裁判,并增加现场比赛所需的裁判员数量。免费游戏还增加了随机性,这会降低游戏多次迭代的可比性。
4.4 场景设计
与调查和实验室实验一样,研究人员必须在他们的场景设计中平衡控制和现实主义,以构建一个实用但生态有效的测试环境。在决定提供多少有关场景和环境的信息时,通常需要在抽象和细节之间进行权衡。兵棋推演必须足够逼真以捕捉现实世界决策的要素并在生态上有效,同时又足够简单以回答研究问题(Mutz,2011:65)。例如,参与者应该获得多少关于危机前导的背景信息?参与者可以获得多少关于对方团队的能力和意图的信息?
一个关键的设计选择是是否在场景中列出实际的国家(Dafoe等人,2018年)。一方面,识别真实的状态可能会创造一个更现实的场景,进而影响决策。但这种现实主义可能会导致政策制定者避免参与军事演习,因为他们担心泄露机密信息。或者,参与者可能会对这些国家产生偏见。另一方面,使用虚构的或不知名的国家可能会增加国家安全从业人员的参与,但限制了从发现中得出的推论。
一般来说,学者们应该倾向于针对特定案例的研究问题(例如美国如何应对伊朗赞助的网络攻击)的现实主义和具体性,并为适用于广泛案例的更广泛问题做出更抽象的场景选择。例如,网络攻击与传统攻击的看法不同。可以肯定的是,相对于提供更多上下文细节的场景,过于抽象的小插曲可能会导致参与者做出可能削弱研究人员控制的假设。Brutger等人最近的研究表明,抽象和细节之间的权衡可能被夸大了,研究人员应该在设计兵棋推演场景时认识到这些问题。
4.5 数据收集和分析:捕获动机(motivations)、交互(interactions)和决策(decisions)
最后,研究人员还必须制定一种策略来收集和分析兵棋推演期间产生的数据。兵棋推演数据可以分为两种类型:结果型和协商型。结果数据识别玩家在游戏中做出的决策,通常在动作、响应计划或其他正式数据输入中捕获。结果数据通常比记录参与者交互的审议数据更容易收集。然而,如果没有经过深思熟虑的数据,结果数据是不完整的。深思熟虑的数据揭示了决策的方式和原因,这可以帮助研究人员探索理论的微观基础。可以追溯丰富的审议数据,以了解想法是如何提出的、玩家如何反应以及团队如何做出决策。结果数据和审议数据结合起来,可以解释现象如何和为什么发生,反之,更多的概率评估可能发生的事情,这是许多实验IR研究的共同特征。
在理想情况下,研究人员会逐字记录所有参与者的互动和决定。在他们的在线兵棋推演中,Goldblum 等人(2019 年)通过数字化捕获玩家决策和参与者之间的聊天消息来实现这一目标。研究人员还可以通过视频或音频记录兵棋推演来捕捉参与者的语气和肢体语言。然而,数字收集并不总是可行的。参与者可能不同意录音,兵棋推演经常在禁止使用电子设备的环境中进行,环境噪音和串扰可能使录音变得困难。因此,研究人员经常依靠研究助理来记录审议并手动记录团队决策,这是从业者游戏中常见的过程。
然而,人类收集数据是一个固有的偏见过程。由于他们的背景,或者由于讨论的速度,记录者会写下某些观察结果并省略其他观察结果(Emerson et al., 2011: 13)。此外,数据收集可能会产生霍桑效应,其中参与者会因为被观察而改变他们的行为(Wickström 和 Bendix,2000)。为了降低这些风险,研究人员可以指派多名研究助理来观察每场比赛,允许进行三角测量,同时尽量让记录员不引人注目。为了准确捕捉游戏结果,研究人员可以指示参与者提交确定最终决定的表格。这些表格还可能要求参与者列出他们考虑的选项,并简要解释他们为什么选择他们所做的行动,生成关于参与者对自己决策过程的看法的书面数据。最后,研究人员可以在团队或个人层面进行赛后采访或调查,以获取有关指导决策的逻辑信息。为了衡量生态效度并改进未来的游戏,这些访谈和调查可能还会要求参与者描述兵棋推演如何模拟真实世界的决策环境。
在设计和分析兵棋推演时,研究人员必须确定分析单元。单元通常应位于与所研究假设相同的分析水平(Gerring,2012: 90–91)。如果被测试的理论与个人层面的信念或行为有关(例如关于内化规范),研究人员可能会使用兵棋推演者作为分析单元。这允许在游戏分析中评估玩家的背景或从属关系如何影响他的行为。同样,使用兵棋推演来研究群体动力学理论的项目可能会将团队视为一个分析单元,从而使研究人员能够解释群体在将个人信念与团队行为联系起来方面的中介作用。然而,如果该理论更广泛地涉及国家安全决策,研究人员可能会考虑使用博弈作为分析单元。一些研究,尤其是那些涉及多个游戏迭代的研究,可能包括多个分析单元,这些分析单元既可以进行内部比较,也可以进行交叉比较。
4.6 游戏设计过程图解
在实践中如何运作?为了演示兵棋推演设计过程,我们将介绍研究人员如何设计和部署国际危机兵棋推演系列(Schechter 等人,2021 年)。研究人员从一个研究问题开始:“网络行动如何影响核稳定性?” 具体来说,他们想评估竞争对手的核指挥、控制和通信网络(主要自变量)中的网络漏洞和漏洞利用是否会影响使用武力的决策(因变量)。基于研究漏洞和漏洞利用的变化是否会影响决策的愿望,研究人员决定使用实验方法。研究人员在“控制”和“治疗”游戏中改变了漏洞和利用的可用性。
为了生成样本,研究人员最初寻求外交政策、网络和核政策方面的精英专业知识,但后来扩大了他们的人口,包括学生和便利样本,以探索不同类型的专业知识和人口统计变量如何影响决策。在规则方面,研究人员选择了一个相对简单的游戏玩法结构,一招一式。这种简单的结构允许团队跳过裁决。正如研究人员解释的那样,“ICWG 优先考虑内部有效性和控制,但也试图随着时间的推移使用大量且异质的样本进行迭代,以创建可概括的发现”(Schechter 等人,2021:6)。
最后,研究人员收集了定量和定性数据进行分析。游戏期间完成的响应计划“移动表”捕获了群体决策,而调查收集了数据以了解单个玩家的动机和对游戏中所采取行动的解释。正如研究人员详述的那样:尽管响应计划是由团队集体制定的,但个别参与者可能对危机有不同的看法或对最佳行动方案的信念。这些调查旨在捕捉这些看法和信念。此外,该调查试图捕捉群体动态如何影响响应计划的完成(Schechter 等人,2021年)。
在设计他们的游戏时,研究人员做出了几个明确的权衡。为了增加他们在三年内进行的迭代之间的游戏总数和控制游戏,研究人员做出的选择可能会降低真实感和沉浸感。例如,使用单方游戏而不是多方游戏增加了游戏迭代的次数,但以现实主义为代价。同样,使用单步游戏而不是多步游戏有助于增强控制力,但可能会限制研究人员探索更复杂的升级问题的能力。此说明的目的不是确定一组选择是对还是错,而是帮助未来的学者慎重思考兵棋推演中固有的权衡取舍。在下面的章节中,我们将评估与分析兵棋推演产生的数据相关的最佳实践和挑战。
5 兵棋推演档案数据
除了开发自己的游戏外,学者们还可以使用历史游戏中的数据。在 1950 年代后期,两位研究人员所做的正是我们在本文中讨论的内容:麻省理工学院 (MIT) 政治学家Lincoln Bloomfield和哈佛经济学家 Thomas Schelling 着手设计社会科学兵棋推演 ( Bloomfield, 1984 : 784–785)。然而,当 1961年参谋长联席会议创建了兵棋推演办公室并引进了Schelling和Bloomfield的方法时,这些创新又回到了政府分类的混乱之下(Bloomfield,1963年)。
这些数据越来越多地可供 IR 研究人员使用(Pauly,2018;Emery,2021)。今天,可以在总统图书馆、中央情报局的 CREST 档案馆、美国在线解密文件、兰德公司和麻省理工学院档案馆找到美国早期兵棋推演的解密记录。这些数据来自高级决策者参与社会科学家兵棋推演的黄金时代,对于政治学理论检验来说已经成熟。由政府机构、智囊团、非政府组织和学者运营的最新游戏的数据也经常公开,包括由兰德公司、海军战争学院、海军研究生院、哈佛贝尔弗中心发布的数据,并且越来越多地出现在定期复制材料中(Pauly, 2018; Schneider, 2017)。
无论是冷战还是现代游戏——学者们应该如何使用档案游戏数据来思考其比较优势、内部、生态和外部有效性以及偏见?关于设计和分析未来游戏的最佳实践,过去的游戏可以教给我们什么?
5.1 分析存档游戏数据
与兵棋推演设计一样,学者的研究问题将为他们的档案游戏选择提供信息。在某些情况下,研究人员可能会寻求解释特定的历史政策或危机决定,生成假设以针对历史记录进行测试(Levine等人,1991),或生成历史反事实。在其他情况下,学者可能会寻求检验理论。
试图了解特定历史决策的学者可以使用兵棋推演来研究对政策过程的投入、决策者考虑的突发事件或机构如何游说。学者们应该更加关注从业人员兵棋推演的一个关键原因是,许多政策制定者使用兵棋推演为规划和决策提供信息。因此,游戏选择将与进行游戏的历史背景相关联。例如,了解约翰逊政府领导下的核政策或决策将受益于他的政府成员所玩的游戏。相比之下,如果研究人员对冲突或危机的一项新技术的影响感兴趣,玩家的政治立场可能不那么重要,但玩家的专业知识可能仍然很重要。
如果研究问题涉及更普遍的国家行为模式——例如威慑何时起作用、领导人何时升级或危机如何失控——选择特定的档案兵棋推演记录就类似于定性案例选择。开放式的政治军事兵棋推演,其中玩家对一系列治国之道工具拥有自由裁量权,可能更适合回答有关战争原因和后果及其限制的问题或测试理论。玩家在战场上进行战术行动的作战兵棋推演可能更适合测试关于战争行为的安全研究理论。然而,学者们必须确保他们选择的游戏确实考虑到了兴趣的变化,因为有些兵棋推演可能会排除某些玩家的行动。例如,使用存档游戏来研究核升级问题的研究人员应该确保,他们从中抽取的游戏不会禁止使用核武器。
学者们还必须确保档案中呈现的数据类型有助于解决他们的研究问题。例如,如果学者们有兴趣解析理论的微观基础机制,那么某些具有良好审议数据的历史兵棋推演是最合适的。与大型游戏甚至现实世界事件的记录相比,小型精英兵棋通常提供非常精细的定性证据,证明玩家选择背后的动机和逻辑。许多冷战兵棋推演数据甚至记录了赛后举行的私人讨论的记录。这些参与者的反思提供了在现实世界事件之后通常无法获得的证据。
在极少数情况下,研究人员可能会在档案中找到旨在提出与他们自己类似研究问题的游戏。即便如此,由于兵棋推演仍然是对现实的模拟,研究人员在分析发现时必须谨慎行事。例如,玩家是否将基于结果的输出视为对现实世界的准确表示,还是将其视为限制生态有效性的“游戏主义”?参与者是否认为她是在为赢得比赛或解决危机而竞争,可以通过对理论发展和测试产生有意义的影响的方式塑造她的行为。因此,在可能的情况下,对理论测试和机制感兴趣的研究人员应收集多个档案兵棋推演进行跨游戏分析,以揭示行为模式,尽管各个游戏在设计、背景或玩家之间存在显著差异。
不同兵棋推演收集、报告和总结审议数据的方式各不相同,研究人员对设计选择了解得越多越好。研究人员必须适应几种常见的偏见。就像采访、日记或回忆录一样,兵棋推演档案记录并不代表对事件的完整和公正的描述。相反,这些数据提供了很好的证据,必须对这些证据进行评估和三角化。为了做到这一点,学者们应该认识到原始和处理过的战局数据之间的区别。原始数据包括游戏行动或结果的定量和定性核算,玩家讨论的文字记录,或玩家体验的调查或访谈。原始的战局数据比处理过的数据更不容易受到系统偏差的影响,但也会受到完整性的影响(Bartels,2020:23-25)。
与原始数据相比,处理后的数据呈现出更完整的兵棋推演画面。已处理的数据包括游戏设计者或管理员记录游戏设计、玩家行为、结果、结论和政策建议的游戏摘要或报告。由于其完整性,研究人员起初可能更喜欢处理过的数据。然而,处理后的数据比原始数据更有可能表现出一些关键的偏差。游戏报告通常是高度政治化的文件,反映了行政人员的官僚动机,这对学者事后可能不透明。事实上,追踪谁被告知(或没有被告知)兵棋推演结果已被证明是过程追踪者的有效数据(Pauly,2020)。例如,Greenstein和Burke (1990[1989]: 576)发现越南兵棋推演的悲观结论从未在1960年代提交给美国总统办公室。
这种偏见源于许多从业者游戏由机构“赞助”,这些机构使用游戏报告来验证现有的记录或理论计划或证明预算和权限的合理性。例如,空军赞助的兵棋推演得出的结论是国会应该为更多的轰炸机买单也就不足为奇了。另一方面,经过处理的数据对研究人员仍然很有价值,因为它们可以揭示有关兵棋设计的决策:场景、裁决和主题,以及原始设计者试图学习的内容。此外,赞助商造成的偏见为学者们提供了一个机会,可以就外交政策制定中的组织和官僚竞争的政治问题提出研究问题。
其他兵棋推演的偏见可能不是其设计或赞助,而是其玩家。研究人员必须努力了解主机和玩家之间的关系。有些人可能会引入严重的霍桑观察者效应,从而破坏测试环境的生态有效性。例如,考虑海军研究生院与印度和巴基斯坦玩家进行的危机游戏(Khan et al., 2016)。乍一看,这些模拟似乎是研究南亚升级的绝佳机会。然而,在美国东道主在场的情况下,比赛有可能变得表演性强,每个地区的核大国都不是为了胜利而努力,而是将对方视为不负责任的。因此,虽然一些游戏服务于召集和教育决策者的重要目的,但寻求检验理论的研究人员需要了解玩家激励和潜在的观察者偏见。
最后,无论是原始的还是经过处理的,许多档案兵棋推演数据都存在解密过滤器遗漏的偏差。这个问题并不是兵棋推演所独有的,解密偏差对兵棋推演记录的影响并不比类似的定性来源(例如在案例研究分析中经常使用的机密会议纪要、政策审查和情报评估)更严重(尽管国防组织经常选择解密兵棋推演支持他们的预算或组织优先事项)。如果玩家在私人或匿名分类录音中更公开地讲话,分类也可以提高数据质量。尽管如此,如果对兵棋推演的兴趣结果影响其解密,这对学者来说是一个问题。美国兵棋记录,即使是“蓝”(美国)队“输掉”的那些,也可以解密,但它们在 1970 年代以后的档案中的可用性很少。参与兵棋推演研究议程的学者必须继续提交 FOIA 和强制解密审查文件请求。
6 兵棋推演研究议程
长期以来,国家安全从业人员一直依靠兵棋推演来制定政策。通过从现有的游戏中汲取经验或运用自己的游戏,研究人员还可以使用游戏来测试 IR 理论——尤其是探索决策背后的微观基础和机制。作为一种学术探究的工具,兵棋推演有可能比其他常用方法更好地逼近现实世界决策的混乱程度,并对人类决策产生更深入的见解。研究人员可能会将兵棋推演作为独立的研究设计,或将其纳入混合方法研究设计,兵棋推演有助于弥补其他研究方法的不足。兵棋推演的核心是通过让学者深入了解为什么会形成某些看法或做出决定,从而强调过程而不是结果。
兵棋推演为研究人员提供了一个机会来分析玩家审议中的证据,例如,来自团队内部关于对手信号和意图感知的对话。这可以产生关于人类如何理解他们的角色、他人的角色或解释决策的意义和背景的见解。兵棋推演构建的社会环境还允许研究人员探索性别、身份、等级和经验等特征如何影响团队内部和团队之间的互动。兵棋推演期间的互动可以揭示决策背后的机制,帮助学者研究大量实质性主题。事实上,国际关系中的许多核心概念,如威慑、危机信号和发动战争,都是基于决策者的决策和互动。因此,从兵棋推演中获得的见解可以帮助研究人员以超越只关注结果变化的实证测试的方式来解读理论。
除了使用兵棋推演对国际关系理论进行实质性研究外,学者们还可以研究政策兵棋推演对现实世界的影响。例如,未来的研究可以检查决策者是否以及何时从政府部署的游戏中学习。五角大楼在 1960 年代的 SIGMA 兵棋推演系列以高级决策者为特色,并预言了越南的困境(McDermott, 2002; Pauly, 2018),但其结果在外交决策过程中被搁置了。这种对兵棋推演课程的忽视有多普遍?相反,选择性解密的兵棋推演在美国最近的公共预算和武器采购讨论中发挥了巨大作用,立法者甚至呼吁更多兵棋推演来为决策提供信息(Gallagher,2020)。兵棋推演如何与组织政治互动?兵棋推演的政治化与其他影响预算或政策选择的政治尝试有何相似之处?研究人员可能会将档案兵棋推演报告与过程追踪和精英访谈相结合来研究这些问题。
然而,为了有效地将兵棋推演用于实质性 IR 研究,学者们还必须检查兵棋推演设计和执行的各种元素是否以及如何影响其整体有效性(内部、外部和生态)以及可以从游戏中得出结论。为此,学者们可能会更深入地研究我们在本文中提出的四个命题。这将有助于学者们更好地利用兵棋推演作为其他研究方法的补充。
首先,未来的项目可能会研究兵棋推演的沉浸性是否会产生不同于非沉浸性方法的行为。例如,受试者在参与兵棋推演时是否使用与完成调查时不同的决策逻辑或调用相同的启发式方法?这对兵棋推演结果的生态和外部有效性意味着什么?而且,这能告诉我们学者们可以使用兵棋推演解决的问题类型吗?
为此,研究人员可以求助于档案游戏数据来研究沉浸感的影响。对 1958 年至 1964 年间在麻省理工学院举行的政治军事兵棋推演中的 77 名参与者进行的一项调查发现,64.9% 的参与者报告了“极端”或“强烈”程度的情感参与。Schelling 回忆说,参与者“虚拟地”进行了兵棋推演,很难在“没有开始看起来真实或可能是真实的场景”的情况下花费这么多小时(美国国防部,1966 年,D3)。但是,虽然这些游戏可能创造了身临其境和逼真的环境,但一些玩家也报告了表现出攻击性的倾向(Barringer 和 Whaley,1965:440)。
如果沉浸在兵棋推演中可以提高生态有效性,我们可能会期望看到玩家在游戏中的行为与现实世界危机决策的记录平行。档案兵棋推演提供了几个示例——越南、古巴、柏林危机——其中参与者在游戏中的行为与实际危机相似。如果没有这样的历史验证,研究人员可能会在几天、几周或几年后询问精英参与者,他们的兵棋推演经验是否影响了他们在现实世界中的决策。
有一些证据表明,在玩家离开游戏环境后,他们会受到这种影响。在上述麻省理工学院的同一项调查中,56% 的“参与政策规划、制定或实施”的玩家可以回忆起他们的兵棋推演经验在他们的工作中具有实际价值。虽然当代数据较少,但一些参与者回忆起深远的影响。例如,Condoleezza Rice报告说,作为国家安全顾问,她于 2001 年 9 月 11 日考虑将美国的军事警报通知莫斯科,并向朋友和敌人解释“美国没有被斩首”,这是基于她的误解和冷战危机模拟期间的升级(Rice 和 Zegart,2018: 178)。同样,前国防部副部长Robert Work和负责情报的国防部副部长Michael Vickers讲述了网络评估办公室在 1990 年代和 2000 年代初期设计的一系列未来兵棋推演在制定战略和武器采购方面发挥的关键作用(Krepinevich 和 Watts,2015 年)。
除了分析档案数据之外,研究人员还可以设计和实施混合方法项目,其中包括在平行研究中与替代方法一起进行的兵棋推演。这将使研究人员能够评估沉浸感如何影响参与者的行为和决策。最近开展了平行调查实验和兵棋推演来解决相同研究问题的项目提供了一个有用的起点(Reddie 等人,2018 年)。例如Schneider等人(2021),发现沉浸在虚拟兵棋推演中的参与者比提供相同场景和预备阅读材料的调查实验受访者对兵棋推演的理解要高得多。事实上,97.5% 的兵棋推演参与者正确回答了一个场景理解问题,而调查实验受访者的这一比例仅为 73%。其他研究也可能通过改变兵棋推演的结构和设置来更系统地探索沉浸感。例如,研究人员可以改变兵棋推演的时长(例如几小时与几天)或进行兵棋推演的物理环境,并评估决策过程或结果是否发生变化。
其次,更多的研究可以帮助学者们更好地理解在兵棋推演中专家和非专家的行为是否不同,以及如何不同。这一研究方向将直接促成关于现代实证 IR 研究中不同类型样本效用的方法论辩论。一方面,一些学者认为,使用具有高度代表性但规模较小的专家样本来进行较少的兵棋推演会限制研究结果的推广程度(Reddie 等人,2018 年)。他们认为,玩多个游戏迭代的大样本(通常是方便的)允许进行统计分析,从而克服普遍性问题并实现复制。然而,其他学者和从业者认为,便利样本限制了游戏的结论(Oberholtzer et al., 2019)。具体而言,非专家可能缺乏做出现实决策所需的技术或政策知识,这些决策反映了现实世界中可能出现的决策。使用其他研究方法的政治科学家长期以来一直在争论便利样本是否足以代表更具代表性的专家样本(Dietrich 等人,2021 年;Hyde,2015 年)。一些研究发现便利样本和精英样本的行为存在差异(Mintz et al., 2006 ; Pauly, 2018),而另一些研究发现精英和非精英偏好之间存在一致性(Kertzer, 2020)。
同样,来自档案游戏的见解提供了探索我们的第二个命题是否会影响我们从兵棋推演中学到东西的机会。惊人的“精英”使一些档案兵棋成为很好的比较点。例如,谢林指挥了参谋长联席会议主席、陆军参谋长和司法部长参与的兵棋推演(Schelling和Ferguson,1988)。这些游戏可以与五角大楼嘉宾(包括名人、记者和企业高管)玩的其他档案游戏进行比较。有兴趣参与关于研究样本的方法论辩论的研究人员可能会考虑部署兵棋推演,将专家玩的兵棋推演中的决策过程与非专家玩的相同博弈中的决策过程进行比较。
第三,未来的研究可能会通过探索群体互动是否以及如何影响兵棋推演期间的决策和行为来促进对群体动力学的研究。如果兵棋推演在生态上是有效的,那么从兵棋推演中汲取的教训应该适用于实际的决策环境。例如,参与者是否担心队友会根据他们的言行来评判他们?团体是否更有可能减轻或放大个人风险倾向?团队组成如何影响团队动态?来自研究人员现场游戏和档案游戏的成绩单通常包括玩家相互证明他们的选择。这些数据可以用来分析与等级、顺从、战斗、情感或性别决策相关的语言,研究人员可以探索不同的团队组成如何影响给定游戏的多次迭代动态。
近期将兵棋推演与交互性较低的合成数据生成过程一起进行的项目为此类未来研究提供了起点(Reddie 等人,2018 年)。Lin-Greenberg (2020),发现兵棋推演团队的决策在参与者之间的审议过程中经常发生变化。在某些情况下,参与者在与队友讨论问题后会改变立场。或者,持有特定观点的参与者可能只是人数超过团队的其他成员,并服从多数立场。因此,兵棋推演审议的动态性质提供了优于互动较少的研究方法的优势,后者通常只在特定时间捕捉个人层面的偏好,使研究人员对想法如何发展和演变的了解较少。
第四,学者们应该评估基于结果的输出是否以及如何影响兵棋推演中的行为和决策。兵棋推演专家难以区分准确反映现实世界决策的后果和可能限制从游戏中得出的结论的“游戏主义”。玩家在游戏中是否会比在实际危机中承担更大的风险?参与者是诚实行事,还是采取行动支持雇主的机构利益?关于激励和奖励是否会影响模拟和实验期间的行为的类似争论仍未解决(Andersen 等人,2011 年;Karagözoglu 和 Urhan,2017 年)。为了解决这些问题,研究人员可能会转向档案游戏,看看精英们在兵棋推演中是否承担了与现实世界危机中类似的风险。或者,研究人员可以评估参与者的行为是否会随着多个兵棋推演的利害关系而变化。
将兵棋推演用于 IR 学术研究仍处于复兴的早期阶段,但我们相信这种方法对于寻求了解如何制定外交政策和国家安全决策的研究人员具有巨大的潜力。随着学者们探索兵棋推演作为一种探究工具的好处和局限性,我们看到兵棋推演研究令人兴奋的可能性,有助于解决其他难以解决的理论和政策问题。
7 致谢
作者感谢 Valentin Bolotnyy、Amber Boydstun、Cole Bunzel、Peter Dombrowski 和 Rose McDermott 对草稿的有益评论,以及 2020 年美国政治学协会会议、乔治城大学兵棋推演协会、伦敦国王学院、海军的研讨会参与者战争学院和麻省理工学院,尤其是 Richard Samuels、Eric Heginbotham、Stacie Pettyjohn、Ellie Bartels 和 Andrew Reddie。Andrew Ortendahl 提供了出色的研究协助。




