
转载机器之心机器之心编辑部
大模型想打开应用前景,要从数据集入手。 胸部 X 光片图像作为临床诊断最常用的手段之一,是计算机与医学结合的一个重要领域。其丰富的视觉和病例报告文本信息促进了 vision-language 在医学领域发展。医学 VQA 是其中的一个重要方向,近年来比较著名的 ImageCLEF-VQA-Med,和 VQA-RAD 数据集包含了许多了胸部 X 光片问答对。
然而,尽管 X 胸片检查报告中包含大量临床信息,现有医学 VQA 任务的问题种类和数量有限,在临床方面的贡献也相对有限。例如,ImageCLEF-VQA-Med 对于胸部 X 光片模态只有两种问题,“这张图片里是否有异常?”,以及 “这张图片里最主要的异常是什么?”,VQA-RAD 的问题种类虽然更丰富,但是却只含有 315 张图片。
在今年的 KDD2023 上,来自德州大学阿灵顿分校,NIH 以及日本理化学研究所,东京大学,国立癌症研究中心的研究人员和放射科医生,联合设计了一个服务临床诊断的大型 VQA 数据集,MIMIC-Diff-VQA。

论文地址:https://arxiv.org/abs/2307.11986
该数据基于放射科胸片报告,设计了种类更加丰富,内容更加准确的具有逻辑递进的问答对,涵盖 7 种不同的问题类型。
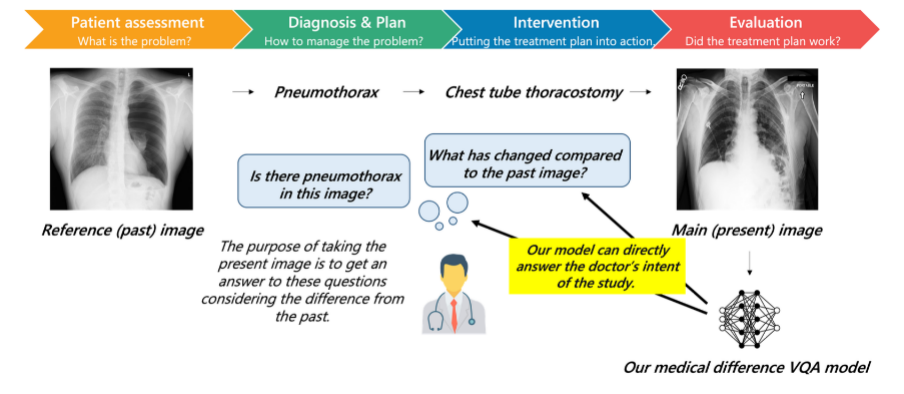
图 1:临床的诊断过程,医生通过比较病程前后图像的差异做出判断
该研究同时提出了一个全新任务,图像对比 VQA (difference VQA):给定两张图片,回答关于这两张图片差异性的问题。在医学领域,这个任务直接反映了放射科医生的需求。在临床实践中,如图 1 所示,医生经常需要对比回看病人之前的医学影像,评估病灶变化情况并以评价诊疗过程。因此 Difference VQA 提出的问题包括” 这张图片与过去的图片相比有什么变化?”, “疾病的严重程度是否有减轻?”
本次公布的数据集包含 16 万张图片和 70 万问题,这大大刷新了此前的医学 VQA 数据集的大小记录。基于该数据集,本文同时也提供了一个利用 GNN 的 VQA 方法作为 basline。为了解决临床放射科图片中病人姿态差异的问题,该研究使用 Faster R-CNN 提取器官的特征作为图的节点,通过整合隐含关系、空间关系和语义关系三种图网络关系来融合了医学专家的知识。其中空间关系是指各个器官之间的位置关系,语义关系包括解剖学和疾病关系知识图,隐含关系通过全连接关系作为前两者的补充。这些节点间的关系被嵌入到图网络的边中,并通过 ReGAT (Relation-aware graph attention network) 用于对最终图特征进行计算。研究团队希望这个数据集能够促进医学领域视觉问答技术的发展,特别是为如 GPT-4 等 LLM 真正服务于临床提供基准,真正成为支持临床决策和患者教育有用的工具。
目前医学 Vision Language 发展现状
医学 Vision Language 领域对现有医疗数据库进行了很多探索来训练深度学习模型。这些数据库包括,MIMIC-CXR, NIH14 和 CheXpert 等。在这些工作通常分为三类:疾病标签的直接分类 (图 2 (b)),医学报告生成 (图 2 (c)) 以及视觉问答任务 (图 2 (d))。疾病标签分类任务首先通过简单的 rule-based 工具,例如 NegBio 和 CheXpert,从报告内容中提取生成预先定义的标签, 随后对正样本和负样本进行分类。报告生成领域的方法繁多,诸如对比学习,Attention 模型,Encoder-Decoder 模型等,核心工作都是将图片信息转化为文字来拟合原始的报告。尽管这些任务取得了很多进展,但从具体临床应用角度来看仍存在局限性。
例如在疾病标签分类中 (图 2 (b)) 中,自然语言处理(NLP)规则经常处理不好不确定性和否定项,导致提取的标签出了不准确。同时,简单的标签只提供了单一的异常信息,无法反映临床疾病的多样性。报告生成系统 (图 2 (c)) 通过挖掘图像中的隐含信息避免这个问题,但是它不能结合临床情况回答医生关注的特定问题。例如图 2 (a) 中,原始放射学报告中排除了多种常见或是医生较为关注的疾病,但是人工报告生成器很难猜测放射科医师想要排除哪些疾病。
相比之下,视觉问答(VQA)任务 (图 2 (c)) 更加可行,因为它可以回答医生或病人所关注的特定问题,比如在之前提到的例子中,问题可以设定为 “图像中是否有气胸 ",而答案无疑是" 没有 "。然而,现有的 VQA 数据集 ImageCLEF-VQA-Med 仅仅包含少量通用问题,比如" 图像有什么问题吗?这张图像的主要异常是什么?",缺乏多样性。这样的问题不仅将 VQA 问题降级为分类问题,而且对临床提供的帮助信息也有限。虽然 VQA-RAD 涵盖 11 种问题类型的问题更加多样,但该数据集仅含有 315 张图像,无法充分发挥出需要大量数据投喂的深度学习模型的性能。为了填补医学 Vision Language 领域的这个空缺,该研究充分结合放射科医生的实践,提出了这项图像对比 VQA(difference VQA)任务,并且基于此任务构建了一个大型的 MIMIC-Diff-VQA 数据集。
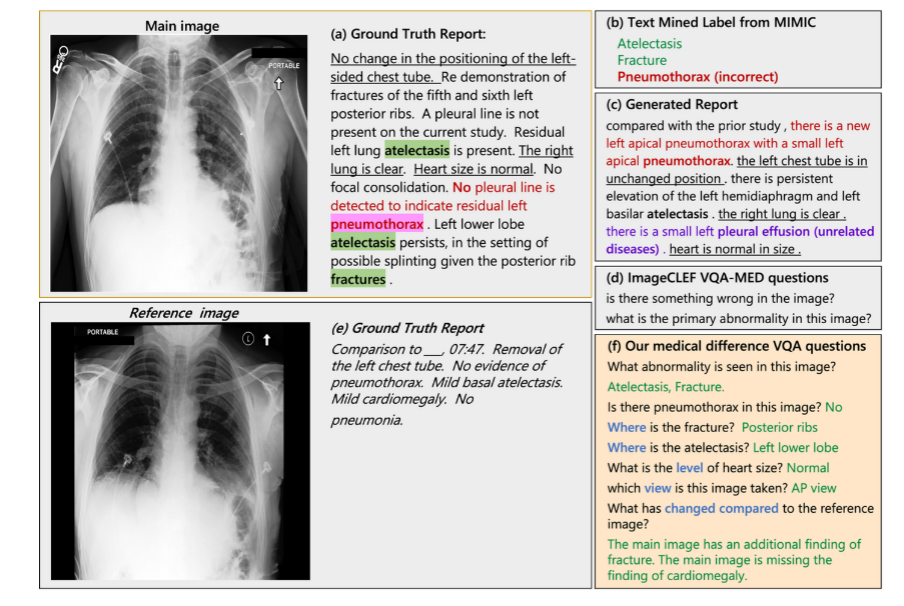
图 2:目前医学 Vision Language 各种方法的对比
数据集介绍
MIMIC-Diff-VQA 数据集包括 164,654 张图片,和 700,703 问题,含盖 7 种不同的具有临床意义的问题类型,包括异常,存在,方位,位置,级别,类型,和差异。前六种问题和传统 VQA 一致,针对于当前图片提问,只有差异类型问题是针对两张图片的问题。各个问题的比例数据和完整问题列表请分别见图 3 和见表格 1。
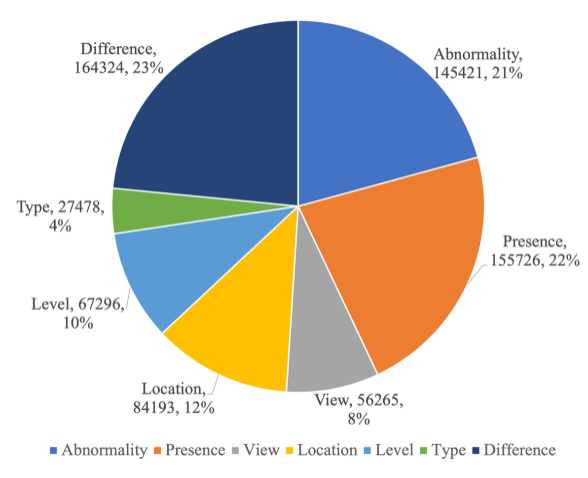
图 3:MIMIC-Diff-VQA 问题类型的统计数据
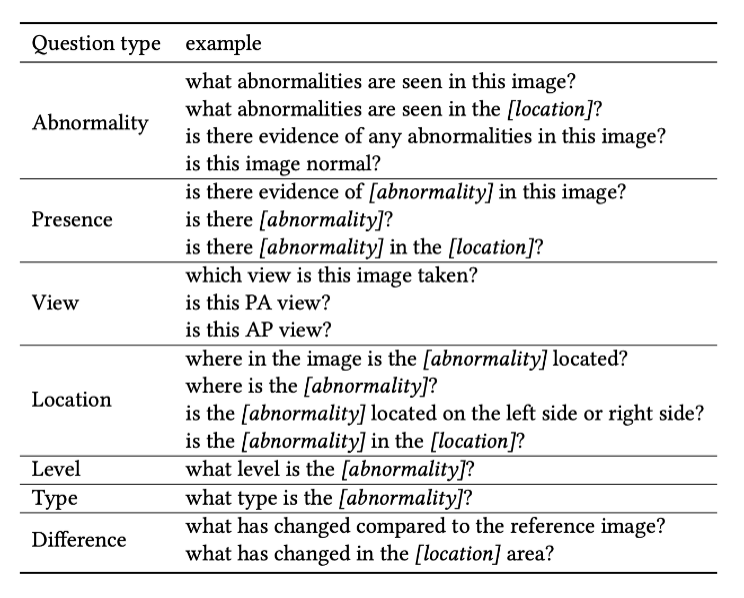
表 1:每种问题类型的问题示例
数据集构建
依托于 MIMIC-CXR 提供的海量的胸部 X 光片图像和文本报告,从 377110 张图片和 227835 个放射学报告中,该研究在放射科医生的指导下构建了 MIMIC-Diff-VQA 数据集。
构造 MIMIC-Diff-VQA 数据集的第一步是提取一个 KeyInfo dataset。这个 KeyInfo dataset 包含每个放射学报告中的关键信息,比如报告中出现的肯定的异常对象,及其对应的异常名称、级别、类型、位置,以及否定出现的对象名。提取过程的第一步是根据医生的意见选取出最常用的异常关键词,和其对应的属性关键词(级别、类型、位置),之后再设定相应的规则对这些关键信息进行提取,同时保留其” 肯定 / 否定 “信息。
为了保证数据集构建的质量,该研究主要遵循 “提取 - 检查 - 修改” 的步骤,首先通过正则表达式设定的规则对数据库报告中的关键信息进行提取,然后利用手动和自动的方法对提取结果进行检查,接下来对出现问题的地方进行修改使提取结果更加准确。其中,检查时使用的自动方法包括:使用 ScispaCy 提取报告中的 entity 名称,考虑 Part-of-Speech 在句子中的作用,交叉验证 MIMIC-CXR-JPG 数据集中的 label 提取结果。综合这些自动化方法和手动验证筛选,通过 “提取 - 检查 - 修改” 的步骤,该研究最终完成了 KeyInfo dataset 的构建。
在完成 KeyInfo dataset 的构建之后,该研究便可以在其基础上设计每一个病人的单次或多次访问对应的问题和答案,最终构成了 MIMIC-Diff-VQA 数据集。
质量保证
为了进一步保证生成数据集的质量,该研究使用三个人工验证者随机对总计 1700 个考题和答案进行了人工验证,如表 2 所示,最终的平均正确率达到了 97.4%。
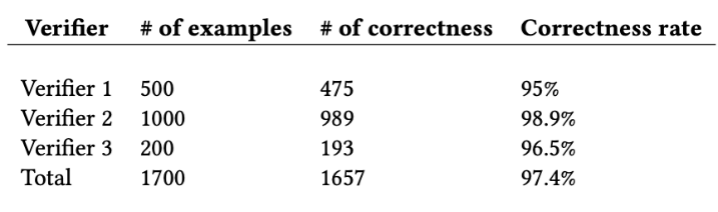
表 2:人工验证数据集结果
Baseline 模型介绍
同时,在提出的数据集基础上,该研究针对胸部 X 光片和 Difference VQA 任务设计了一个图网络模型。如图 4 所示,考虑拍摄胸部 X 光片的过程中,到同一个病人在不同时间点可能由于身体姿态的不同,拍摄的图像可能伴随着大尺度的位移和改变。
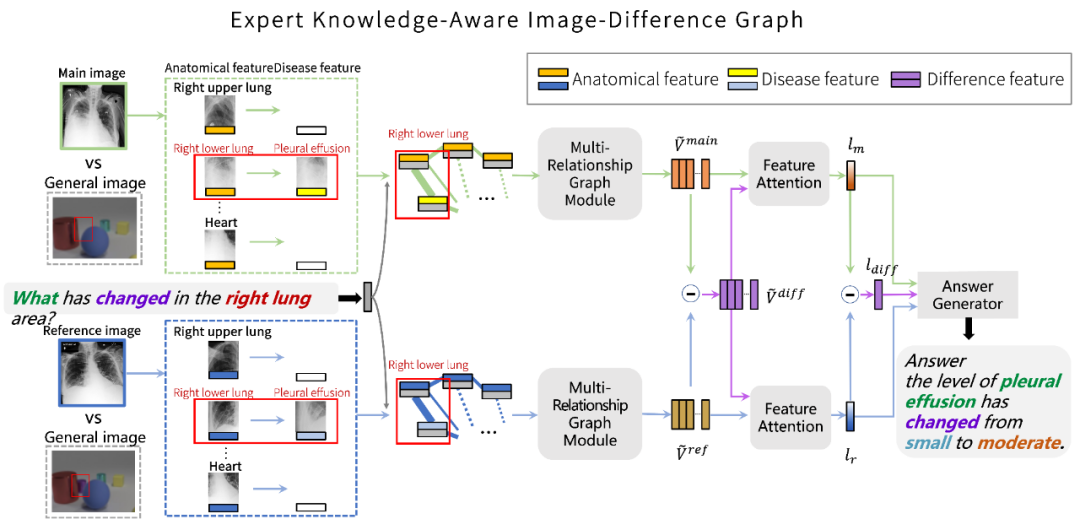
图 4:该研究提出方法的模型结构
因此,gai通过对输入的图片进行解剖学结构定位,并提取对应检测对象的特征作为图网络的节点,以排除病人身体姿态对特征的影响。图网络中的每一个节点是一个解剖学结构位置的特征与问题特征的结合。为了充分挖掘图像中可能包含的病变信息,该研究通过不同的预训练模型为每一个解剖学结构提取一个纯解剖学结构特征和一个疾病特征。
在 “多关系图网络模块” 中,该研究进行了三种不同的图网络关系来计算最终的图网络特征,包括:隐含关系,空间关系,语义关系。对于隐含关系,使用简单的全连接以让模型在潜在关系中发掘有价值的信息。对于空间关系,研究团队考虑了节点之间 11 种不同的空间关系作为边,并用 ReGAT (Relation-aware Graph Attention Network) 进行计算。对于语义关系,该研究引入了两种知识图谱,即,共现知识图谱(Co-occurrence Knowledge graph),和解剖学知识图谱(Anatomical Knowledge graph)。前者考虑不同疾病之间共同出现的概率关系,后者考虑疾病与解剖学之间的关系。
由于该研究在第一步提取了对应的解剖学结构特征和疾病特征,于是便可以将他们嵌入到这两种知识图谱当中。与空间关系的图网络计算类似,该研究考虑了三种语义关系:共现关系,解剖学关系,无关系,来作为图网络的边,每一种关系用一个数字标签来进行表征,并使用 ReGAT 进行运算。
最终,三种关系图网络计算后的节点特征进行全局平均池化,得到最终图像对应的图特征。将两张图片的图特征相减便可得到差异图特征。对这些特征通过注意力机制得到对应的特征向量,然后将两张图片的特征向量和相减后得到的差异特征向量输入最终的 LSTM 答案生成器,便可得到最终的答案。
该研究将模型与领域内最先进的方法做对比,包括 MMQ (Multiple Meta-model Quantifying), MCCFormers ( Multi-Change Captioning transformers), 和 IDCPCL (Image Difference Captioning with Pre-training and Contrastive Learning)。其中 MMQ 是传统医学 VQA 模型,MCCFormers 和 IDCPCL 是差异描述(Difference Captioning)模型。由于 MMQ 无法处理多张图像,该研究仅在除了 Difference 类问题以外的其他六种问题上将它与所提模型作对比。对于 MCCFormers 和 IDCPCL,由于他们不是 VQA 模型并且必须同时输入两张图片,因此该研究仅在 Difference 类问题上与他们进行对比。对比结果如表 3 和表 4 所示,该模型在 Difference VQA 上显示出了更优越的性能。
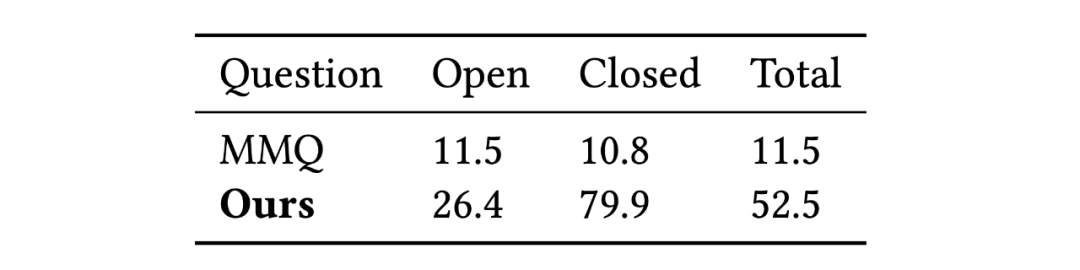
表 3:该研究提出的方法与 MMQ 在 non-difference 类问题上的准确率对比
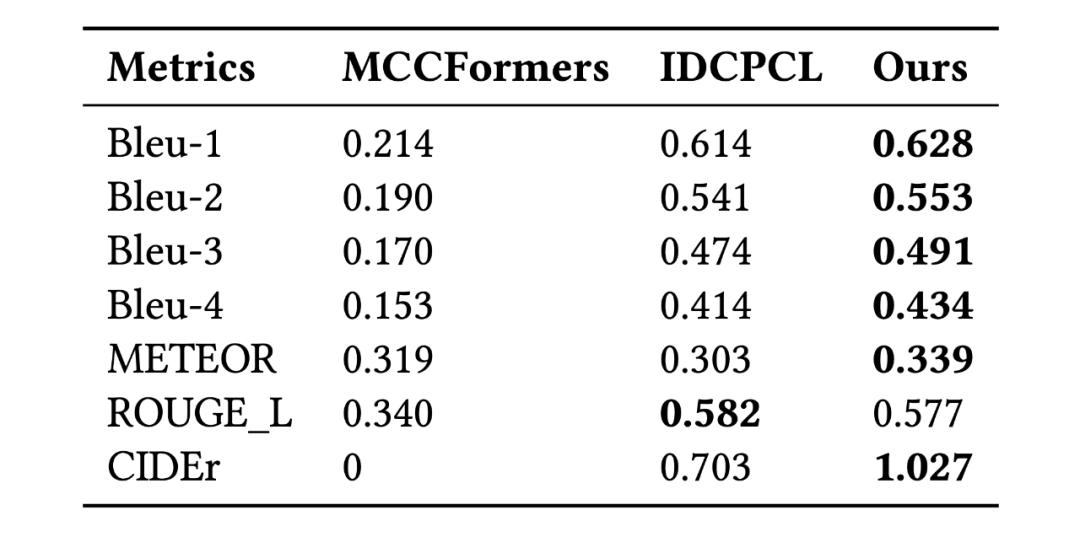
表 4:几种方法与差异描述方法在 Difference 类问题上的对比
总结与讨论
该研究提出了一个医学 Difference VQA 问题,并收集了一个大规模的 MIMIC-Diff-VQA 数据集,以此希望能对推动学界相关技术的发展,同时为医学界提供有力的支持,包括提供临床决策辅助和患者教育工具等方面。同时,该研究设计了一个专家知识感知的多关系图网络模型来解决这个问题,为学界提供了一个基准模型作为参照。与当前在相关领域最先进的方法的比较表明,该研究所提方法取得了显著改进。
然而,该研究的数据集和方法仍存在一定的局限性,比如数据集没有考虑对于特殊情况下同一个病灶出现在多于两处的情况,以及同义词的合并也有进一步的提升空间。
此外,所提模型也会产生一些错误,包括:1、对同一异常的不同呈现方面的混淆,例如肺不张和肺浸润被互相误认。2、相同类型异常的不同名称,例如心影增大被错误分类为心脏肥大。3、用于提取图像特征的预训练模型(Faster-RCNN)可能提供不准确的特征,并导致错误的预测,例如错误地将肺浸润识别为胸膜积液。
