AAAI 2019 | 云从科技联手上海交大提出端到端统一语义角色标注
机器之心发布
来源:云从科技
随着自然语言处理 (NLP , Natural Language Processing) 的发展,以及在语言信息处理与人工智能领域的地位愈发重要。作为自然语言处理的一项基础性任务,语义角色标注(SRL,Semantic Role Labeling)逐渐成为研究的重点。本文介绍了来自上海交通大学与云从科技联合创新实验室的 AAAI 2019 论文。本届大会共收到 7700 余篇有效投稿,其中 7095 篇论文进入评审环节,最终有 1150 篇论文被录用,录取率为近年最低仅为 16.2%。
论文:Dependency or Span, End-to-End Uniform Semantic Role Labeling

论文地址:http://bcmi.sjtu.edu.cn/~zhaohai/pubs/aaai2019-UniSRL-1113-2.pdf
语义角色标注(SRL)旨在发现句子的谓词-论元结构。它以句子的谓词为中心,分析句子中各成分与谓词之间的关系,即句子的谓词(Predicate)- 论元(Argument)结构。谓词是对主语的陈述或说明,指出「做什么」、「是什么」或「怎么样,代表了一个事件的核心,跟谓词搭配的名词称为论元。语义角色是指论元在动词所指事件中担任的角色。主要有:施事者(Agent)、受事者(Patient)、客体(Theme)、经验者(Experiencer)、受益者(Beneficiary)、工具(Instrument)、处所(Location)、目标(Goal)和来源(Source)等。
例如:「小明昨天晚上在公园遇到了小红。」
「遇到」是句子的谓词,「小明」是谓词的发起者,角色为「施事者」,「小红」是谓词的接受者,角色是「受事者」,「公园」是谓词的发生地点,据说是「处所」等。
作为自然语言处理的一项基础性任务,语义角色标注能提供上层应用的非常重要的语义信息。例如在阅读理解应用中,把语义角色标注作为输入的一部分,可以帮助阅读理解应用更加准确确定各部分的语义角色,从而提高阅读理解的准确性。
比如:「小明打了小华」和「小华被小明打了」,这两句话语义完全一致,但由于被动语态引起的主语和宾语位置上的变化,当提问「谁挨打了?」时,阅读理解算法在处理这两句时,有可能会给出不同的答案。但如果我们把语义角色标注也作为阅读理解的输入信息,由于两句话中「小华」都是「受事者」角色,问题也是在问「受事者」是谁,这时阅读理解算法往往比较容易给出一致准确的答案。
明确了一个句子中各个成分的语义角色,可以更好的帮助自然语言的理解和处理。比如在「信息提取」任务中,准确的提取出动作的发出者信息;在「阅读问答」中给出事件发生的时间、地点等。因此,语义角色标注时很多自然语言理解与处理任务的基础,对于实现自然语言处理意义非常重要。
传统的语义角色标注是建立在句法分析的基础上的,但由于构建准确的语法树比较困难,基于此方法的语义角色标注准确率并不高,因此,近年来无句法输入的端到端语义角色标注模型受到了广泛的关注。这些模型算法,根据对论元的表示不同,又划分为基于区间(span)和基于依存(dependency)两类方法,不同方法的模型只能在对应的论元表示形式上进行优化,不能扩展、应用到另一种论元表示上。
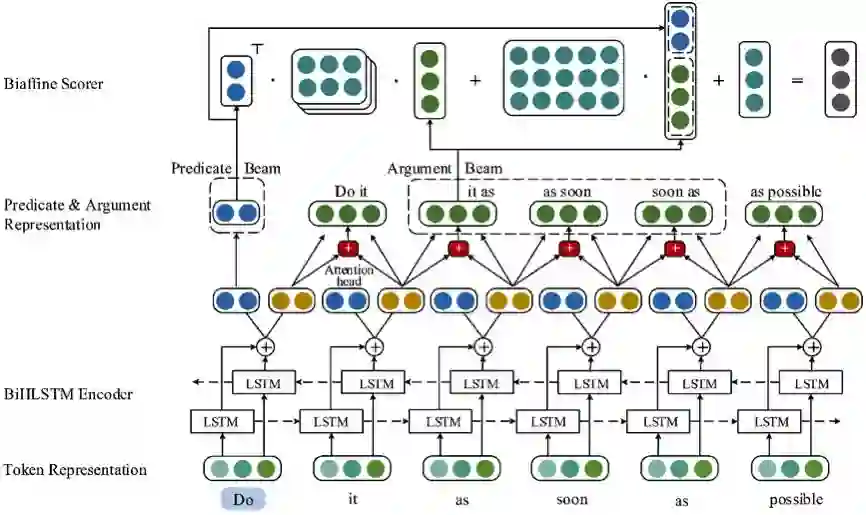
图 1:Span 与 Dependency 统一语义角色标注架构。
我们的论文则通过提出一个统一的谓词与论元表示层,实现了将论元表示形式的统一(参见上图中的 Predicate&Argument Representation 层),因此,该模型可以接受不同论元表示形式的数据集进行训练。
此外,我们的模型通过对谓词、论元评分,以及谓词和论元的一个双仿射变换,同时实现了对谓词的识别、以及谓词与论元的联合预测(参见上图中 Biaffine Scorer 层)。我们的单一模型在 CoNLL 2005、2012(基于 Span 的数据集)和 CoNLL 2008、2009(基于 Dependency 的数据集)SRL 基准数据集上,无论是在自主识别谓词、还是在给定谓词的情况下,相比于学术上目前已知的算法,都取得了较领先的结果,尤其是在 span 数据集、给定谓词的情况下,我们的单一模型甚至在所有指标上领先于已知的 Ensemble 模型。结果可参见表二、三、四、五。
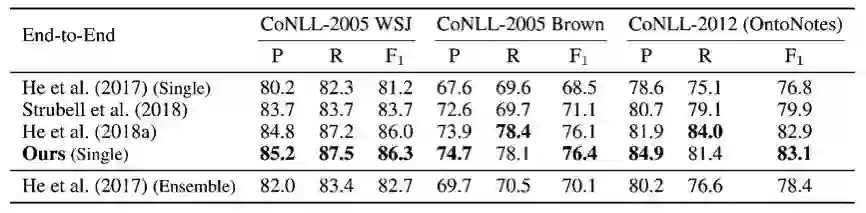
图 2:端到端设置下谓词与论元联合预测 Span 结果。
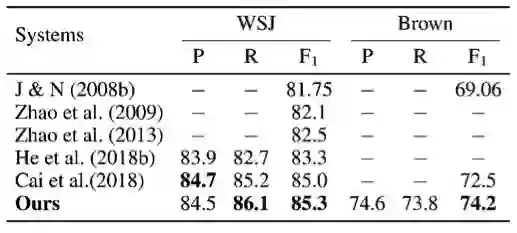
图 3:端到端设置下谓词与论元联合预测 Dependency 结果。
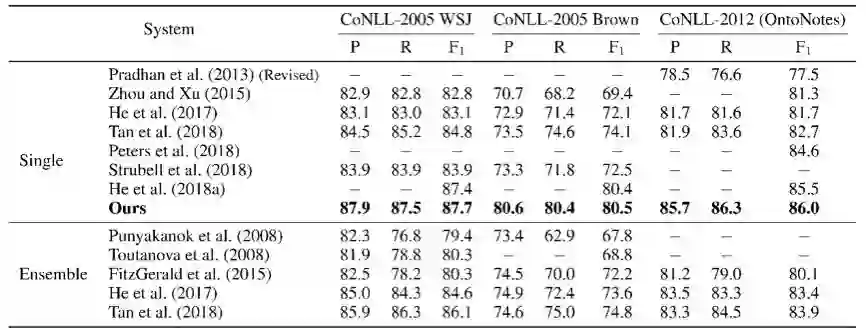
图 4:给定谓词情况下只预测论元 Span 结果。
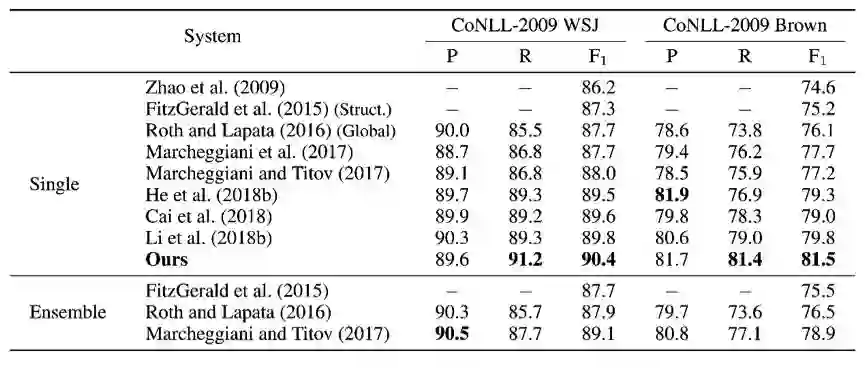
图 5:给定谓词情况下只预测论元 Dependency 结果。
本文报告了第一个在 span 和 Dependency 两种形式的语义角色标注的标准树库上同时获得最高精度的系统;
本文首次把目前最为有效的三大建模和机器学习要素集成到一个系统内,包括 span 选择模型、双仿射(biaffine)注意力机制以及预训练语言模型(ELMo);
本文首次针对依存形式的语义角色标注报告了超过 90% 的 F 值的里程碑精度。

本文为机器之心发布,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com




