

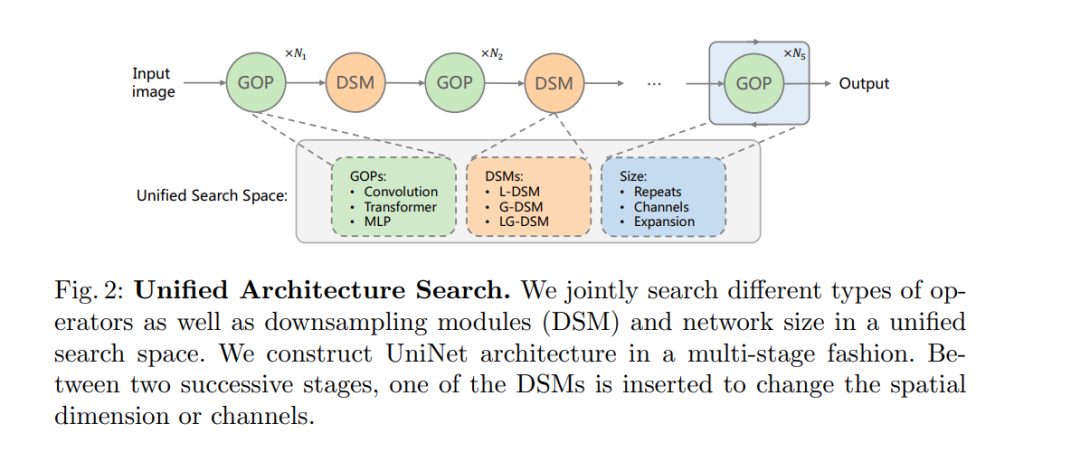
近年来,transformer和多层感知器(MLP)架构在各种视觉任务中取得了令人印象深刻的成果。然而,如何有效地将这些运算符组合在一起,形成高性能的混合视觉架构仍然是一个挑战。在这项工作中,我们通过提出一种新的统一架构搜索方法来研究卷积、transformer和MLP的可学习组合。我们的方法包含两个关键设计来实现对高性能网络的搜索。首先,我们以统一的形式对不同的可搜索运算符进行建模,从而使这些运算符可以用相同的一组配置参数来表征。这样,整体搜索空间的大小大大降低,总搜索成本变得可以承受。其次,我们提出了上下文感知下采样模块(DSMs),以减轻不同类型操作之间的差距。我们提出的DSM能够更好地适应不同类型运算符的特征,这对于识别高性能混合架构非常重要。最后,我们将可配置算子和DSM集成到一个统一的搜索空间中,并使用基于强化学习的搜索算法进行搜索,以充分探索这些算子的最优组合。为此,我们搜索了一个基线网络,并将其扩大,得到了一个名为UniNets的模型家族,它比以前的ConvNets和transformer取得了更好的精度和效率。特别地,我们的UniNet-B5在ImageNet上实现了84.9%的top-1准确率,比efficient - net - b7和BoTNet-T7分别减少了44%和55%的失败。通过在ImageNet-21K上进行预训练,我们的UniNet-B6达到87.4%,性能优于Swin-L,失败次数减少51%,参数减少41%。代码可以在https://github.com/Sense-X/UniNet上找到。
成为VIP会员查看完整内容
相关内容

Transformer是谷歌发表的论文《Attention Is All You Need》提出一种完全基于Attention的翻译架构
Arxiv
12+阅读 · 2021年8月30日
相关主题

相关VIP内容
相关资讯