神操作!RM让ResNet等价转换为Plain架构

极市导读
本文在ResBlock上实施RM(Reserving and Merging, RM)操作移除残差连接,将ResNet等价转换为类VGG架构,取得了更好的精度-速度均衡。>>加入极市CV技术交流群,走在计算机视觉的最前沿

arXiv:https://arxiv.org/abs/2111.00687
code: https://github.com/fxmeng/RMNet
Abstract
尽管残差连接有助于极深网络训练,但其多分支拓扑结构不利于在线推理 。这也就促使了诸多研究员设计推理时无残差连接的CNN模型。比如,RepVGG将训练时的多分支结构重参数为推理时的单分支类VGG结构,当网络相对浅时表现出了非常优异性能 。然而,RepVGG无法将ResNet等价转换为类VGG结构,这是因为重参数机制仅适用于线性模块 ,而将非线性层置于残差连接之外则会导致有限的表达能力,对于极深网络影响尤为严重。本文旨在解决上述问题,在ResBlock上实施RM(Reserving and Merging, RM)操作移除残差连接 ,将ResNet等价转换为类VGG架构 。作为一种“plug-in”方案,RM具有以下三个优势:
-
其实现方式天然的对高比例网络剪枝友好; -
有助于打破RepVGG的深度限制 -
取得了更好的精度-速度均衡。
Preliminary
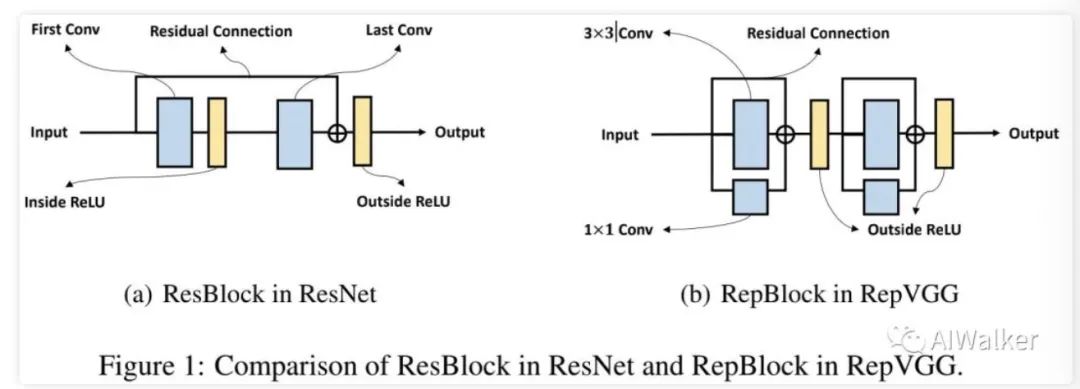
上图给出了ResNet与RepVGG中的基础模块示意图,可以看到:在ResBlock中,两个ReLU分别位于残差连接内外;而在RepBlock中,两个ReLU均位于残差连接之外 。由于重参数是基于乘法交换律,故ReLU需要位于残差连接之外方可进行结构重参数化。当然,我们采用两个RepBlock替换一个ResBlock,接下来,我们将从forward与backward两个角度分析为何RepVGG无法像ResNet那样深 。
Forward Path :已有研究认为:ResNet的成功源自“模型集成” 。我们可以将ResNet视作多个不同长度模型的集成,因此具有n-block的ResNet具有个隐式路径连接。然而,RepVGG中的多分支可以表示为单分支,这使其不具备ResNet的隐式“集成假设” 。这就导致RepVGG与ResNet的表达能力差距会随模块数提升而变大。
Backward Path :有研究对DNN中的“破碎梯度(Shattered Gradients)问题”进行了分析。当反向路径中有更多ReLU时,梯度的相关性表现类似“高斯白噪声 ”。假设ResNet与RepVGG均有n层,那么ResNet的反向分支中的ReLU数量为,而RepVGG的则是。这就意味着:相比RepVGG,当深度较大时,ResNet的梯度更不易“破碎”,进而具有比RepVGG更好的性能 。
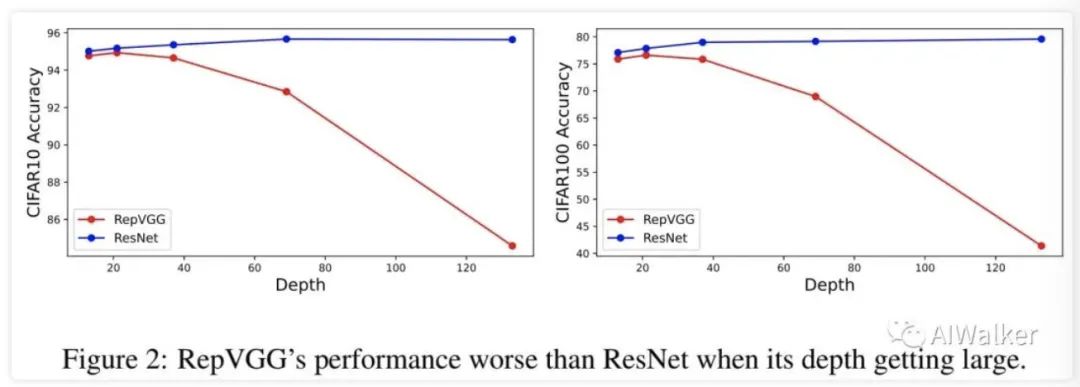
上图研究了深度对于ResNet和RepVGG的性能影响,从中可以看到:随深度提升,ResNet取得越来越好精度,这与前述分析相一致;而RepVGG的精度则会下降 。比如,ResNet-133的精度为79.57%@CIFAR100,而RepVGG-133的仅为41.38%@CIFAR100。(PS:为啥我就这么信不过呢??? )
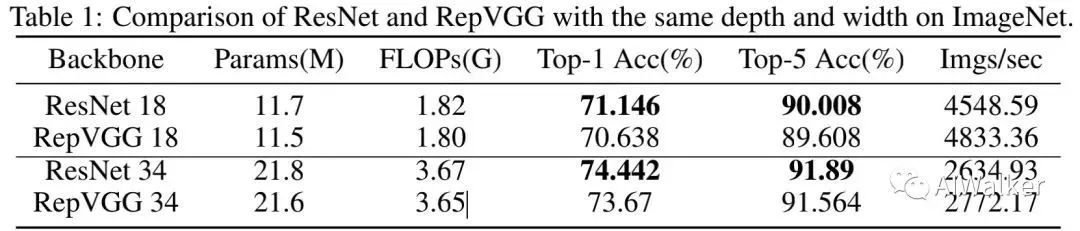
上图还给出了ImageNet数据集上的性能对比,从中可以看到:ResNet-18的性能要比RepVGG-18高0.5%;ResNet-34的性能要比RepVGG-34高0.8%。因此,RepVGG以损失表达能力为代价进行速度提升。
RMNet
RM Operation
下图给出了RM操作移除残差连接的等价过程。为简单起见,上图没有显示BN层。输入通道、中间通道以及输出通道均为C。
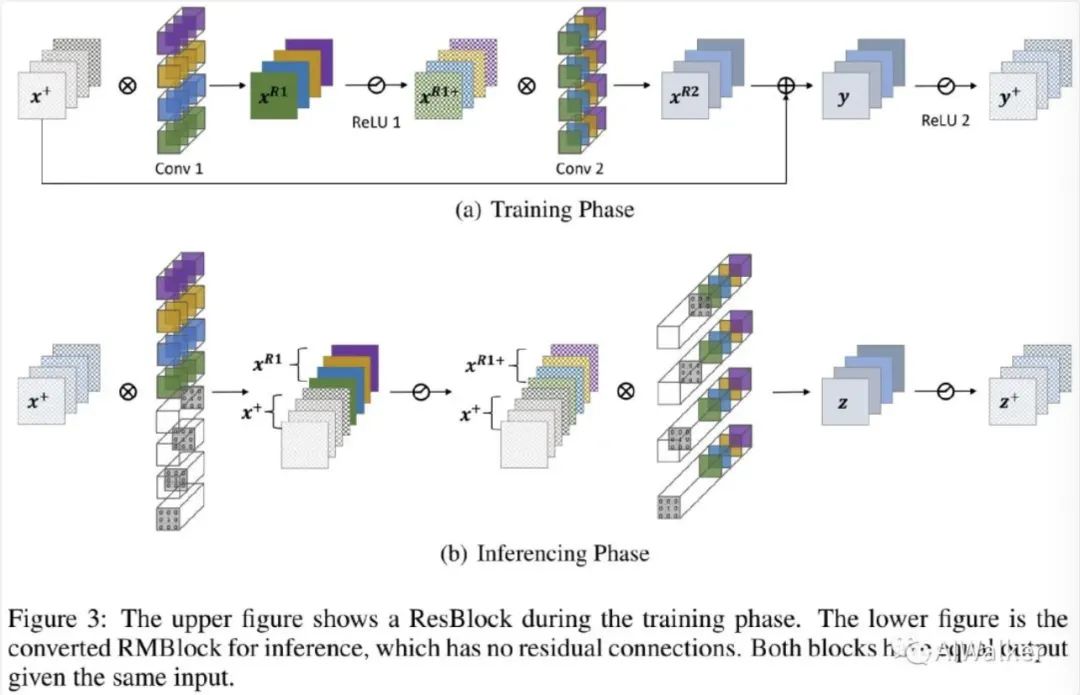
Reserving 我们首先在Conv1中插入几个Dirac初始化的滤波器(即输出通道,可参见上图b),可表示如下:
对于BN层, 为保持输入特征, BN中的权值与偏置需要进行调整以确保BN层具有类似identity的效果。假设特征的滑动均值 与方差分别为 。我们设置权值与偏置为 。因此,对于经过BN层的任意输入, 其输出可以表示为:
对于ReLU层,需要考虑以下两种情形:
-
当通过残差连接的输入值为非负时,我们可以直接使用ReLU保持该信息; -
当通过残差连接的输入值为负时,我们采用PReLU保持该信息。将PReLU中对应通道的参数设置为1,此时PReLU可以起到Identity作用。
Merging 我们对Conv2的输入通道进行扩展并通过direc初始化。z的第i通道等于原始滤波结果输出 的第i通道相加。整个合并过程表示如下:
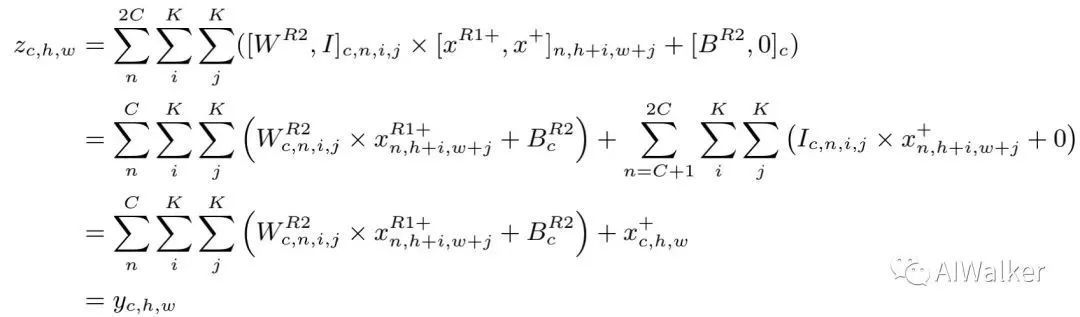
因此,通过Reserving与Merging操作,我们可以移除残差连接且不会改变ResBlock的输出。
Pruning RMNet
由于RMNet没有任何残差连接,它对于滤波器剪枝非常友好。接下来,我们将采用Network slimming对RMNet进行剪枝。
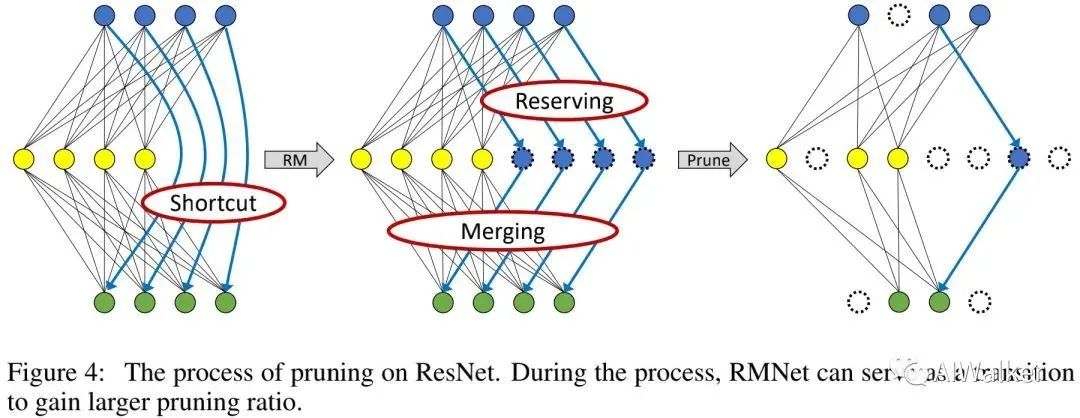
具体来说,我们首先训练ResNet并稀疏化BN层的权值。在完成训练后,我们将ResNet转换成RMNet并根据BN层权值进行剪枝。上图对剪枝过程进行了可视化,RMNet可视作更大剪枝比例的过渡。
Improving RepVGG with RM Operation
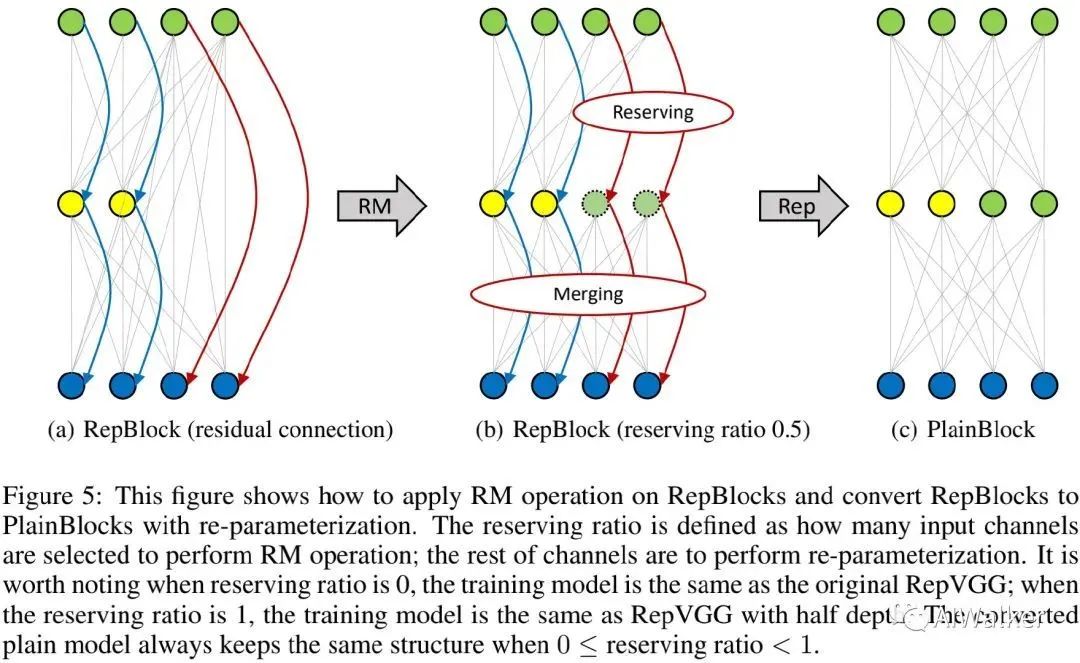
作为一种“plug-in”操作,当网络比较深时,RM可以帮助RepVGG取得更好性能。额额额,看了半天没看懂,以后再补上吧....
Convert MobileNetV2 to MobileNetV1
技术上来讲,转换ResNet与MobileNetV2没有区别。然而,MobileNetV2结构的特殊性使得我们可以在RM之后利用参数融合进一步降低推理速度。
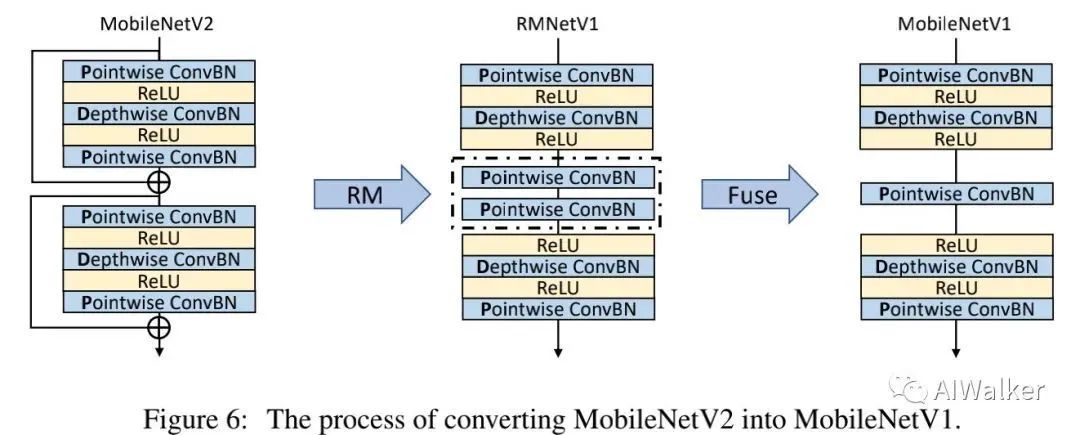
上图给出了MobileNetV2经由RM处理到RMNetV1的示意图,此时残差连接被移除,导致了两个连续的Pointwise-ConvBN层(见上图虚线部分)。由于两个Pointwise ConvBN之间无非线性操作,故他们可以进一步融合。融合公式描述如下:
RMNet经过参数量后等效于MobileNetV1,这就非常有意思了:MobileNetV2是通过利用残差连接提升MobileNetV1的性能而得到,而RM与参数融合则将MobileNetV2退化回MobileNetV1了 。是不是可以说:RM让MobileNetV1再次伟大 !
Experiments
在实验部分,我们首先验证RMNet在剪枝任务上的有效性,然后再证实RM操作有助于训练更深的RepVGG,其次我们表明RMNet可以作用于轻量型模型,最后证实RMNet可以取得更好的速度-精度均衡。
Friendly for Pruning
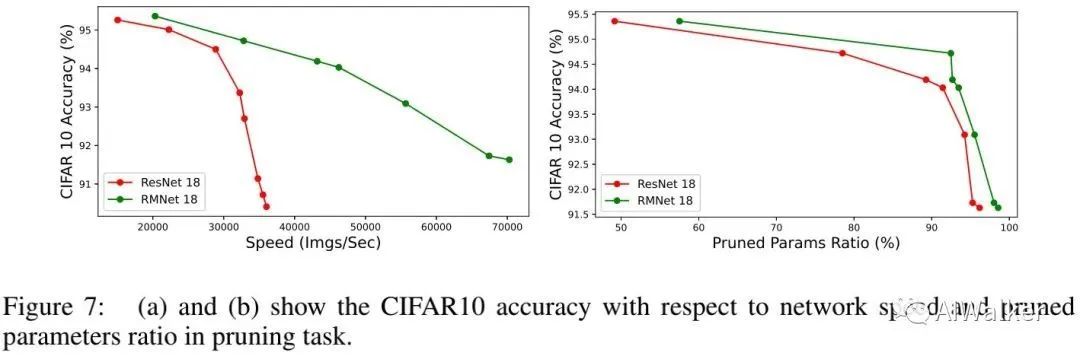
上图对比了ResNet-18与RMNet-18在L1Norm剪枝上的性能对比,可以看到:
-
相比ResNet,剪枝后的RMNet具有更高的精度 ; -
当剪枝比例相当时,RMNet具有更快的速度; -
在剪枝任务上,相比ResNet,RMNet具有更好地精度-速度均衡。
Break the depth limitation of RepVGG
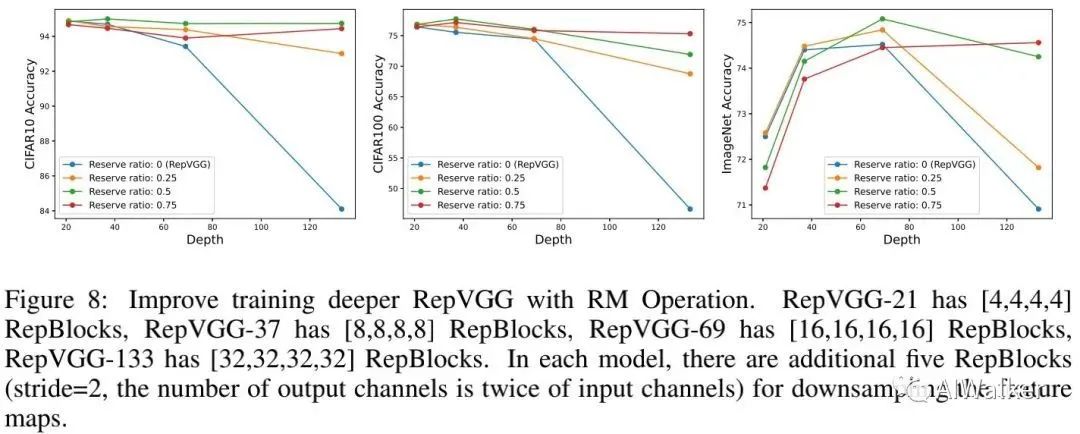
上图给出了不同reserving比例的性能对比,可以看到:
-
当深度较小时,RepVGG表现很好,而随深度增加性能轻微下降; -
RepVGG+RM则能随深度提升保持好性能。 -
结果表明:浅层网络需要更多参数、更少残差连接;而更深网络需要更多残差连接。因此,该实验表明:本文RM设计有助于打破RepVGG的深度局限性。
Friendly for light-weight Models
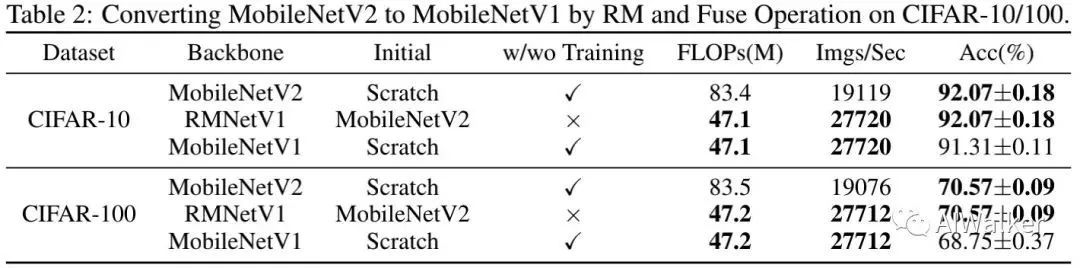
上表对比了MobileNet系列与RMNet的性能(注:这里的MobileNetV2与原生模型不一样),可以看到:RMNet的速度要快于MobileNetV2,而精度高于MobileNetV1 。这说明:RM操作对轻量型模型非常友好 。
Design better accuracy-speed tradeoff RMNeXt
正如前面所提到:RMNet以引入额外的参数为代价移除残差连接 。为缓解该问题,我们采用RM+Inverted Residual Block (IRB)构建RMNet。这里的IRB包含三个连续操作:point-wise、group-wise以及point-wise卷积。其中第一个point-wise会将输入通道提升T倍,而第二个point-wise则会将通道数降为原始通道数。
对于point-wise卷积, RM操作仅提升 的参数量与计算量。假设输入特征为 , 第一个point-wise卷积的参数量描述为 , 我们仅需额外的 参数以保持输入特征。
Group-wise同样是一种参数友好的操作。对于常规卷积, 我们需要 参数保持一个输入通道信息; 而对于groupwise卷积, 我们仅需 参数量即可。
基于IRB, 我们设计了一系列RMNet模型。我们首先确定输入与输出的经典宽度配置 。在stem部分, 我 们将 卷积 MaxPooling替换为两个连续的 ;在尾部,我们采用了与ResNet相同的配置。
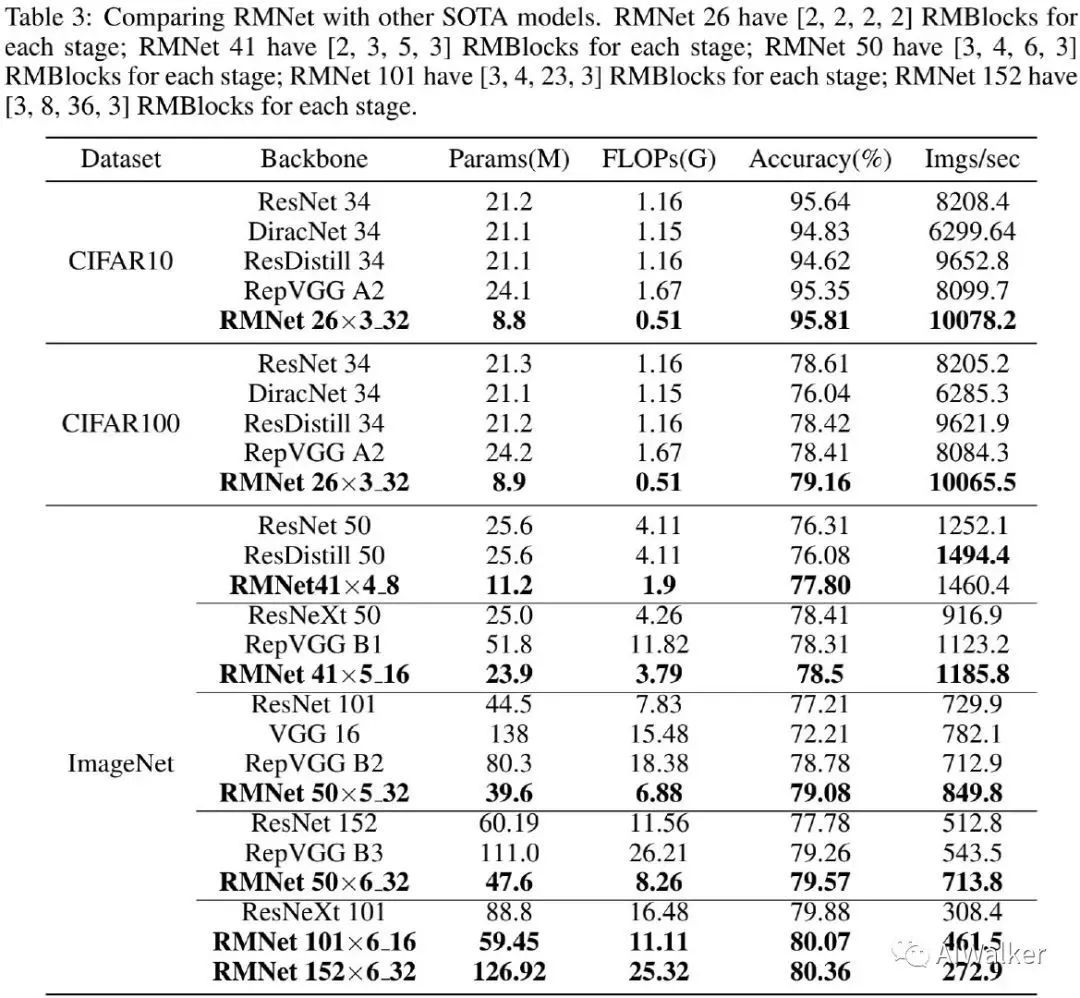
上表给出了ImageNet上不同方案的性能对比,从中可以看到:
-
RMNet-50x6_32比ResNet101的精度高2.3%,比RepVGG-B2高0.59%同时具有相当速度; -
无需任何tricks,RMNet-101x6_16取得了超80%的精度,成为 首个无需任何trick性能超越80%的plain模型 。PS:RepVGG应该是首个性能超越80%的plain模型,不过它使用了autoaugment,训练了200epoch;而RMNet则并未提到相关训练配置信息。 -
当深度提升到152时,RMNet性能仍可进一步提升,达到80.36%。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

