CVPR 2022 | 超越Transformer!FAIR重新设计纯卷积架构:ConvNeXt
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
导读
“文艺复兴”,ConvNet卷土重来,压过Transformer。本文是FAIR的Zhuang Liu(DenseNet的作者)与Saining Xie(ResNeXt的作者)关于ConvNet的最新探索,以ResNet为出发点,逐步引入近来ViT架构的一些设计理念而得到的纯ConvNet新架构ConvNeXt,取得了优于SwinT的性能,让ConvNet再次性能焕发。

A ConvNet for the 2020s
论文链接:https://arxiv.org/abs/2201.03545
代码链接:https://github.com/facebookresearch/ConvNeXt
Abstract
ViT伴随着视觉的“20年代”咆哮而来,迅速的碾压了ConvNet成为主流的研究方向。然而,当应用于广义CV任务(如目标检测、语义分割)时,常规的ViT面临着极大挑战。因此,分层Transformer(如Swin Transformer)重新引入了ConvNet先验信息,使得Transformer成实际可行的骨干网络并在不同视觉任务上取得了非凡的性能。然而,这种混合方法的有效性仍然很大程度上归根于Transformer的内在优越性,而非卷积固有归纳偏置。
本文对该设计空间进行了重新审视并测试了ConvNet所能达到的极限。我们将标准卷积朝ViT的设计方向进行逐步“现代化”调整,并发现了几种影响性能的关键成分。由于该探索是纯ConvNet架构,故将其称之为ConvNeXt。完全标准ConvNet模块构建的ConvNeXt取得了优于Transformer的精度87.8%,在COCO检测与ADE20K分割任务上超越了SwinTransformer,同时保持了ConvNet的简单性与高效性。
Modernizing ConvNet:Roadmap
接下来,我们将提供从ResNet到ConvNeXt的演变轨迹。我们考虑了两种不同FLOPs尺寸的模型:ResNet50/Swin-T(FLOPs约 )与ResNet200/Swin-B(FLOPs约 ),为简单起见,这里仅呈现ResNet50/Swin-T复杂度模型的结果。
我们以ResNet50作为出发点,首先采用类似ViT的训练技术对其重训练并得到ResNet50的改进结果(这将作为本文的基线);然后我们研究了一系列设计准则,总结如下:
-
Macro Design -
ResNeXt -
Inverted Bottleneck -
Large Kernel Size -
Various Layer-wise Micro Design.
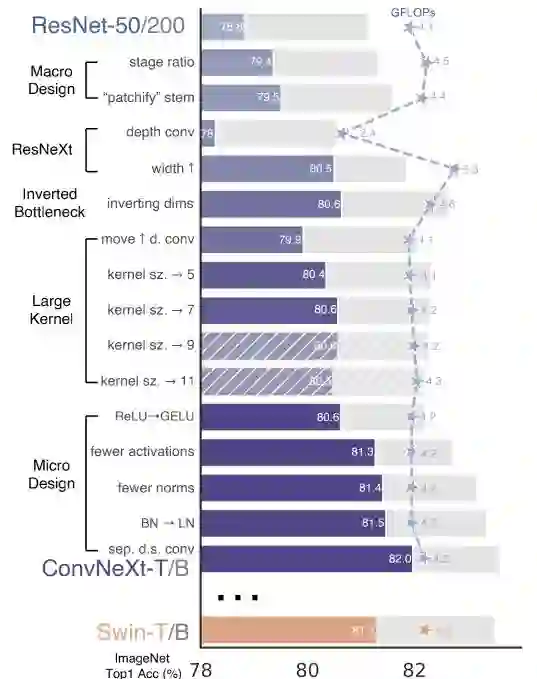
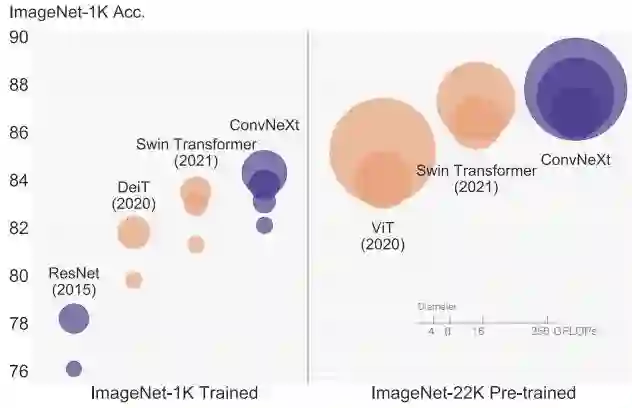
从上图可以看到网络架构每一次进化所能取得的性能(ConvNeXt-T取得了82%,超越了Swin-T的81.3%),由于模型复杂度与最终性能相关,故FLOPs进行了一定程度的控制。
Training Techniques
除了网络架构的设计外,训练方式也会影响最终的性能。ViT不仅带来了新的模块与架构设计,同时还引入了不同的训练技术,如AdamW优化。因此,探索的第一步就是采用ViT的训练机制训练基线模型ResNet-50/200。
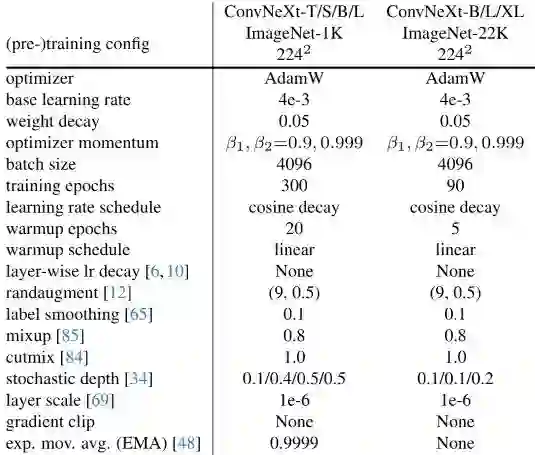
本文采用了DeiT与SwinTransformer的训练方案,可参见上表。训练周期从原始的90epoch扩展到了300epoch;优化器为AdamW,数据增广包含Mixup、Cutmix、RandAugment、RandomErasing;正则化技术包含Stochastic Depth与Label Smoothing。增强的训练技术将ResNet50的性能从76.1%提升到了78.8%,这说明:Transformer与ConvNet的性能差距很大比例源自训练技术的升级。
Macro Design
我们现在开始对SwinTransformer的宏观架构设计,它参考ConvNet采用了多阶段设计思想,每个阶段具有不同的特征分辨率。它具有两个有意思的设计考量:(1) Stage Compute Ratio; (2)Stem Cell架构。
Changing Stage Compute Ratio. 原始ResNet的计算分布是经验性成果。“res4”的重计算设计是为了与下游任务(如目标检测)相兼容;而Swin-T参考了类似的设计准则但将计算比例微调为 ,更大的SwinTransformer的比例则为 。参考该设计理念,我们将ResNet50每个阶段的块数从 调整为 。此时模型的性能从78.8%提升到79.4%。
Changing Stem to "Patchify". 一般来讲,Stem设计主要关心:在网络起始部分如何对图像进行处理。由于自然图像的信息冗余性,常见的Stem通过对输入图像下采样聚合到适当的特征尺寸。ResNet中的Stem包含stride等于2的 卷积+MaxPool,它将输入图像进行4倍下采样;而ViT则采用了"Patchify"策略,它对应了大卷积核(如14、16)、非重叠卷积;SwinTransformer采用了类似的"Patchify",但块尺寸为4以兼容多阶段设计架构。我们将ResNet中的Stem替换为 的"Patchify"层。此时,模型的性能从79.4%提升到了79.5%。
ResNeXt-ify
在这里,我们尝试采用了ResNeXt的设计理念(采用更多的组扩展宽度),其核心成分为组卷积。具体来说,ResNeXt在Bottleneck中为 采用组卷积。这种设计方式可以大幅减少FLOPs,故通过提升网络宽度补偿容量损失。
在本文中,我们采用depthwise卷积,同时将网络的宽度进行了提升,此时它与Swin-T具有相同的通道数。此时,模型的性能提升到了80.5%,而FLOPs则提升到了53.G。
Inverted Bottleneck
Transformer模块的一个重要设计:它构建了Inverted Bottleneck,如MLP的隐层维度是输入维度的4倍。有意思的是:Transformer的这种设计与ConvNet中的Inverted Bottleneck(最早源自MobileNetV2)设计相一致。
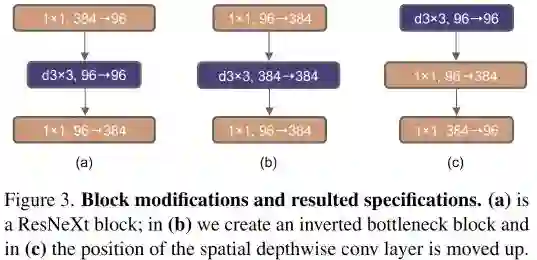
在这里,我们探索了上图的几种不同设计,它将网络的FLOPs下降到了4.6G。有意思的是,这种设计将模型的性能从80.5%提升到了80.6%。对ResNet200的性能提升则更大,从81.9%提升到了82.6%。
Large Kernel Sizes
在这部分,我们聚焦于大卷积核的行为表现。ViT的最重要区分是其非局部自注意力,它使得每一层均具有全局感受野。尽管SwinTransformer采用了局部窗口机制,但其感受野仍至少为 ,远大于ConvNet的 。因此,我们将ConvNet中使用大卷积核卷积进行回顾。
Moving up depthwise conv layer. 为探索大核,先决条件是depthwise卷积的位置上移(见Figure3c)。这种设计理念等同于Transformer中的MHSA先于MLP。此时,模型的性能临时下降到了79.9%,而FLOPs也下降到了4.1G。
Increasing the kernel size. 基于上述准备,我们采用了更大的卷积核,如 。此时,模型的性能从79.9%!提升到了80.6%( ),而模型的FLOPs几乎不变。
Micro Design
接下来,我们将从微观角度(即OP层面)探索几种架构差异,主要聚焦于激活函数与Normalization层的选择。
Replacing ReLU wit GELU. NLP与视觉架构的一个差异体现在激活函数的实用。ConvNet大多采用ReLU,而ViT大多采用GELU。我们发现:ConvNet中的ReLU可以替换为GELU,同时性能不变(80.6%)。
Fewer Activation Functions. Transformer与ResNet模块的一个小区别:Transformer模块使用了更少的激活函数。类似的,我们对ConvNeXt模块进行下图所示的改进,模型性能从80.6%提升到了81.3%(此时,它具有与Swin-T相当的性能)。
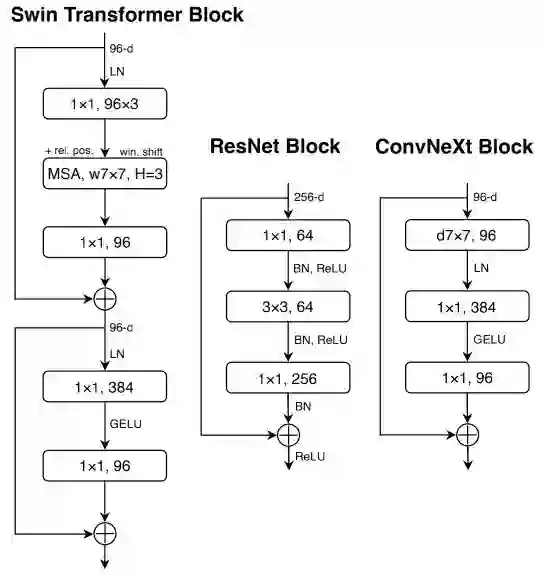
Fewer Normalization Layers Transformer通常具有更少的Normalization层,因此我们移除两个BN层仅保留 卷积之前的一个BN。模型的性能提升到了81.4%,超越了Swin-T。
Substituting BN with LN 尽管BN是ConvNet的重要成分,具有加速收敛降低过拟合的作用;但BN对模型性能也存在有害影响。Transformer中的LN对不同的应用场景均具有比较好的性能。直接在原始ResNet中将BN替换为LN会导致性能下降,而组合了上述技术后再将BN替换为LN则能带来性能的提升:81.5%。
Separate Downsamling Layers 在ResNet中,每个阶段先采用stride=2的 卷积进行下采样;而SwinTransformer则采用了分离式下采样层。我们探索了类似的策略:采用stride=2的 卷积进行下采样,但这种方式导致了“不收敛”。进一步研究表明:在下采样处添加Normalization层有助于稳定训练。此时,模型的性能提升到了82.0%,大幅超越了Swin-T的81.3%。
Closing remarks. 到此为止,我们完成了ConvNet的进化之路,得到了超越SwinTransformer的纯ConvNet架构ConvNeXt。需要注意的是,上述设计并没有新颖之处,均得到了研究,但并未进行汇总集成。ConvNeXt具有与SwinTransformer相当的参数量、吞吐量、内存占用,更高的性能,且不需要依赖特定的模块(比如移位窗口注意力、相对位置偏置)。
Exmpirical Evaluations on ImageNet
基于前述ConvNeXt架构,我们构建了ConvNeXt-T/S/B/L以对标Swin-T/S/B/L。此外,我们还构建了一个更大的ConvNeXt-XL以进一步测试ConvNeXt的缩放性。不同变种模型的区别在于通道数、模块数,详细信息如下:
-
ConvNeXt-T: C= ,B= -
ConvNeXt-S: C= ,B= -
ConvNeXt-B: C= ,B= -
ConvNeXt-L: C= ,B= -
ConvNeXt-XL: C= ,B=
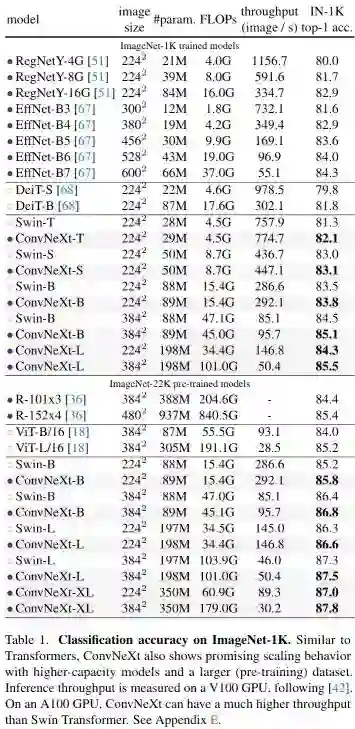
上表给出了ImageNet上的性能对比,从中可以看到:
-
ConvNeXt具有比ConvNet(如RegNet、EfficientNet)更佳的精度-计算均衡以及吞吐量; -
ConvNeXt同样具有比SwinTransformer更佳的性能,且无需特殊操作模块; -
ConvNeXt@384比Swin-B性能高0.6%且推理速度快12.5%; -
仅需ImageNet训练,ConvNeXt-XL的性能即可达到85.5%;当采用ImageNet-22K预训练时,模型性能进一步提升到了87.8%。
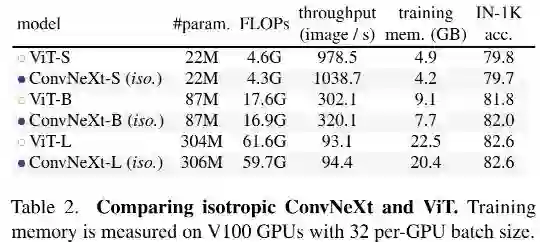
既然ConvNeXt这么好,其设计理念能否应用到ViT中呢?结果见上表,从中可以看到:两者具有相当的性能,这意味着:ConvNeXt的设计理念用于非分层模块时仍具有竞争力。
Empirical Evalution on Downstream Tasks
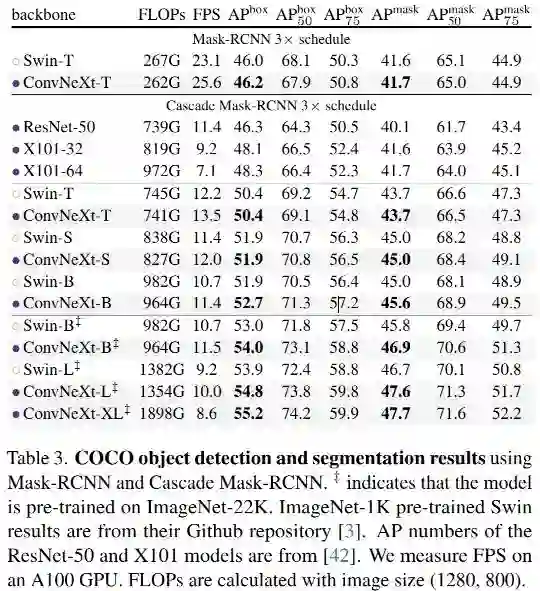
为进一步验证ConvNeXt在下游任务的表现,我们基于Mask R-CNN与Cascade Mask R-CNN在COCO检测方面的性能,结果见上表,从中可以看到:ConvNeXt取得了与SwinTransformer相当,甚至更优的性能。当采用更大的骨干且ImageNet22K预训练时,ConvNeXt的性能更佳。
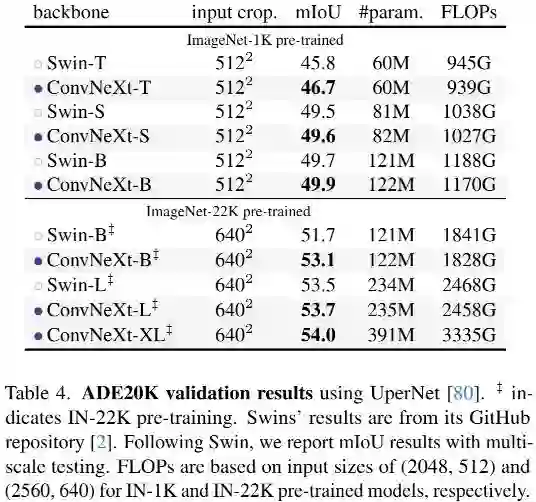
上表给出了ADE20K数据上的性能对比,从中可以看到:在不同容量大小下,ConvNeXt均可取得极具竞争力的结果,进一步验证了ConvNeXt的有效性。
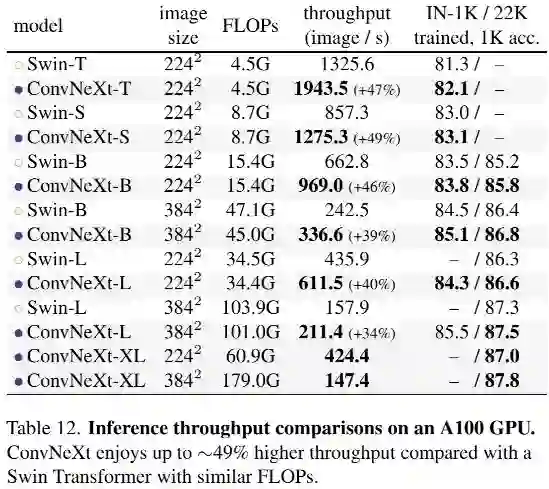
上表还给出了Swin与ConvNeXt在吞吐量方面的对比,很明显:ConvNeXt具有比Swin更高的吞吐量、更高的精度。
上面论文和代码下载
后台回复:ConvNeXt,即可下载上述论文和代码
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看