又快又强的轻量化主干来了!EfficientFormer:在iPhone上能实时推理的ViT模型
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达

EfficientFormer: Vision Transformers at MobileNet Speed
论文:https://arxiv.org/abs/2206.01191
代码(即将开源):
https://github.com/hkzhang91/EdgeFormer
Vision Transformers(ViT) 在计算机视觉任务中取得了快速进展,在各种基准测试中取得了可喜的成果。然而,由于大量的参数和模型设计,例如注意力机制,基于ViT的模型通常比轻量级卷积网络慢几倍。因此,应用部署ViT具有很大的挑战性,尤其是在移动设备等资源受限的硬件上。最近的很多工作都试图通过网络架构搜索或与
MobileNet Block的混合设计来降低ViT的计算复杂度,但推理速度仍然不能令人满意。这就引出了一个重要的问题:Transformer能否在获得高性能的同时运行得像MobileNet一样快?为了回答这个问题,首先重新审视基于
ViT的模型中使用的网络架构和ViT算子,并确定其低效的设计。然后引入了一个维度一致的纯Transformer(没有MobileNet Block)作为设计范式。最后,执行延迟驱动的瘦身以获得一系列最终模型,称为EfficientFormer。大量实验表明
EfficientFormer在移动设备上的性能和速度方面具有优势。EfficientFormer-L1在ImageNet-1K上实现了 79.2% 的 Top-1 准确率,在iPhone 12(使用CoreML编译)上只有 1.6 ms 的推理延迟,这甚至比MobileNetV2(1.7 ms,71.8% Top-1),EfficientFormer-L7获得了 83.3% 的准确率,延迟仅为 7.0 ms。EfficientFormer证明,正确设计的Transformer可以在移动设备上达到极低的延迟,同时保持高性能。
1简介
最初为自然语言处理 (NLP) 任务设计的 Transformer 架构引入了多头自注意力 (MHSA) 机制,该机制允许网络对长期依赖关系进行建模并且易于并行化。在这种情况下,Dosovitskiy 等人将注意力机制应用于 2D 图像并提出了 Vision Transformer (ViT):将输入图像划分为不重叠的块,通过 MHSA 学习块间表示,缺失了归纳偏差。
与计算机视觉任务上的卷积神经网络 (CNN) 相比,ViT 展示了可喜的结果。在此成功之后,通过改进训练策略、引入架构更改、重新设计注意力机制以及提升各种视觉任务(如分类、分割和检测)的性能来探索 ViT 的潜力。
不利的一面是,Transformer 模型通常比 CNN 慢几倍。有许多因素限制了 ViT 的推理速度,包括大量参数、关于Token长度的二次增加的计算复杂度、不可融合的归一化层以及缺乏编译器级别的优化(例如,CNN 的 Winograd)。高延迟使得 Transformer 对于资源受限硬件上的实际应用程序不切实际,例如移动设备和可穿戴设备上的增强或虚拟现实应用程序。因此,轻量级 CNN 仍然是实时推理的默认选择。
为了缓解 Transformer 的延迟瓶颈,已经提出了许多方法。例如,一些努力考虑通过改变线性层与卷积层(Conv)来设计新的架构或算子,将自注意力与 MobileNet Block 相结合,或引入稀疏注意力以降低计算成本,而其他努力则利用网络搜索算法或修剪以提高效率。尽管现有工作已经改善了计算性能权衡,但与 Transformer 模型的适用性相关的基本问题仍未得到解答:强大的 Vision Transformers 能否以 MobileNet 速度运行并成为边缘应用程序的默认选项?这项工作通过以下贡献对答案进行了研究:
首先,通过延迟分析重新审视
ViT及其变体的设计原则。在现有工作之后,使用 iPhone12 作为测试平台,并使用CoreML作为编译器;其次,根据分析,确定了
ViT中低效的设计和操作符,并为Vision Transformers提出了一种新的尺寸一致设计范式;最后,从具有新设计范式的
supernet开始,提出了一种简单而有效的latency-driven slimming方法,以获得一个新的模型族,即EfficientFormers。直接优化推理速度,而不是 MAC 或参数数量。
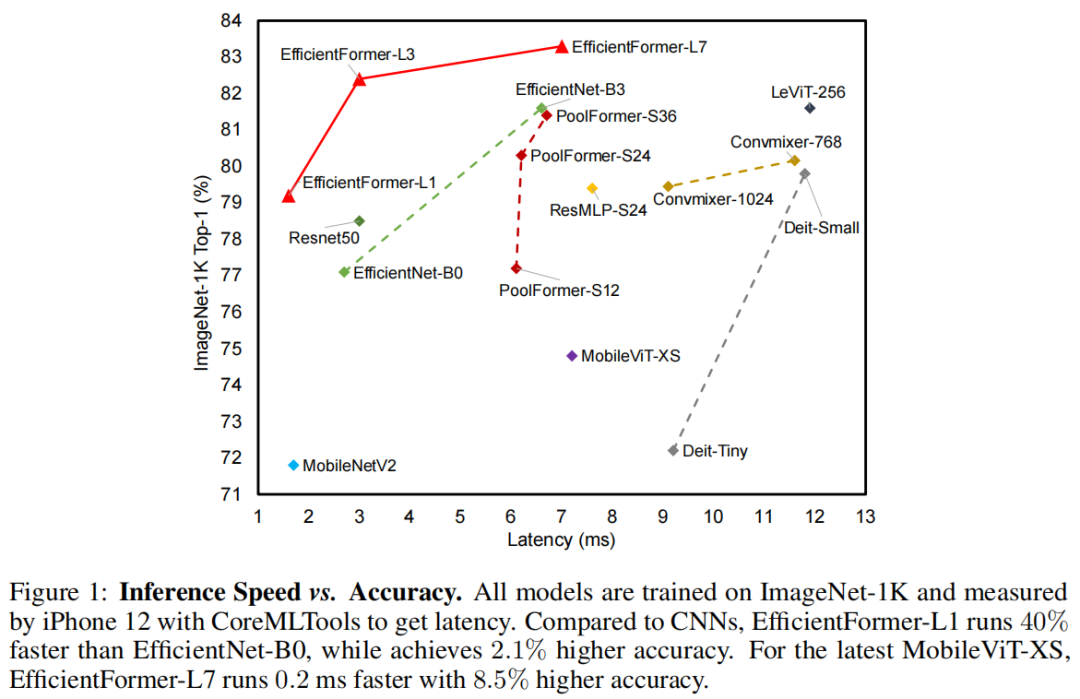
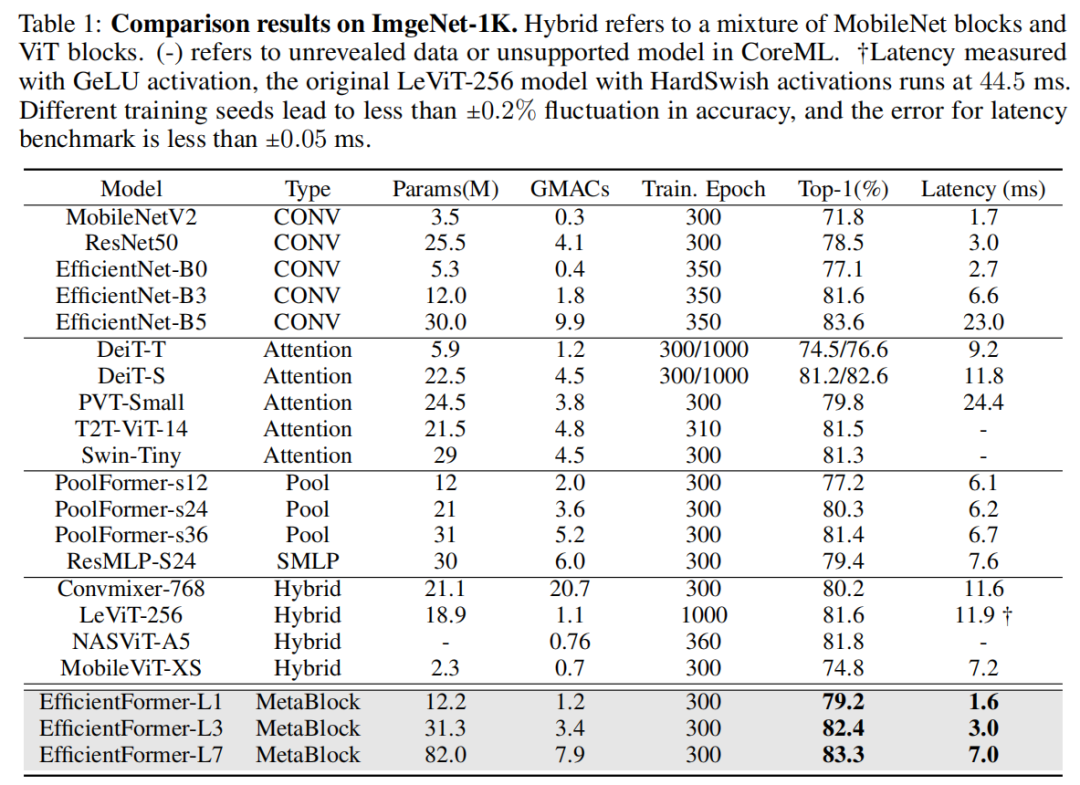
EfficientFormer-L1 在 ImageNet-1K 分类任务上实现了 79.2% 的 top-1 准确率,推理时间仅为 1.6 ms,与 MobileNetV2 相比,延迟降低了 6%,top-1 准确率提高了 7.4%。有希望的结果表明,延迟不再是广泛采用Vision Transformers的障碍。
EfficientFormer-L7 实现了 83.3% 的准确率,延迟仅为 7.0 ms,大大优于 ViT×MobileNet 混合设计(MobileViT-XS,74.8%,7.2ms)。
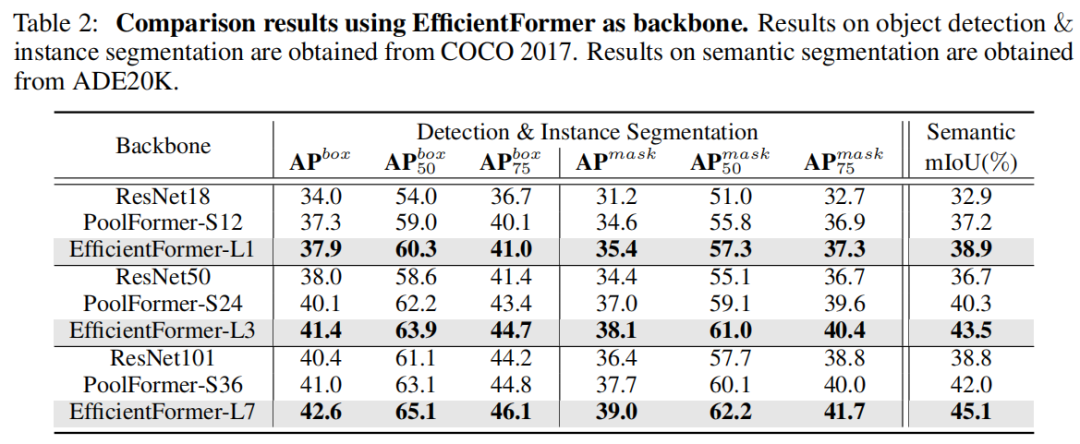
此外,通过使用 EfficientFormer 作为图像检测和分割基准的Backbone,观察到了卓越的性能。对上述问题提供了初步答案,ViTs 可以实现超快的推理速度和强大的性能。
2Vision Transformers的延迟分析
大多数现有方法通过从服务器 GPU 获得的计算复杂度 (MAC) 或吞吐量(图像/秒)来优化Transformer的推理速度。虽然这些指标并不能反映真实的设备延迟。为了清楚地了解哪些操作和设计选择会减慢边缘设备上的 ViT 推理,作者对许多模型和操作进行了全面的延迟分析,如图 2 所示,由此得出以下观察结果。
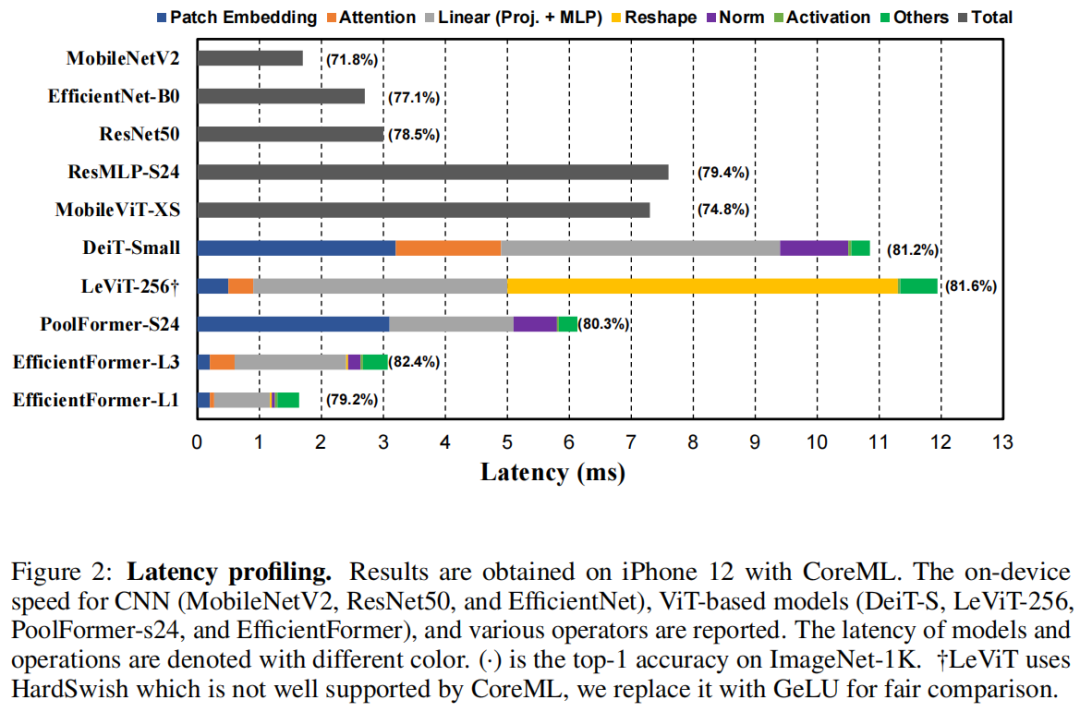
观察1:具有大
kernel和stride的Patch embedding是移动设备的速度瓶颈。
Patch embedding通常使用具有较大kernel-size和stride的非重叠卷积层来实现。一个普遍的看法是,transformer 网络中Patch embedding的计算成本不显着或可以忽略不计。然而,在图 2 中比较了具有大kernel和stride的Patch embedding模型,即 DeiT-S 和 PoolFormer-s24,以及没有它的模型,即 LeViT-256 和 EfficientFormer,表明Patch embedding反而是移动设备上的速度瓶颈。
大多数编译器都不能很好地支持大内核卷积,并且无法通过 Winograd 等现有算法进行加速。或者,非重叠Patch embedding可以由具有快速下采样的卷积stem代替,该卷积干由几个硬件高效的 3×3 卷积组成。
观察2:一致的特征维度对于
token mixer的选择很重要。MHSA不一定是速度瓶颈。
最近的工作将基于 ViT 的模型扩展到由 MLP 块和未指定的 token mixer 组成的 MetaFormer 架构。在构建基于 ViT 的模型时,选择 token mixer 是必不可少的设计选择。选项很多——具有全局感受野的传统 MHSA、更复杂的移位窗口注意力或非参数运算符(如池化)。
这里将比较范围缩小到池化和 MHSA 这两个 token mixer ,选择前者是因为它的简单性和效率,而后者是为了更好的性能。大多数公共移动编译器目前不支持更复杂的 token mixer ,如移位窗口,因此将它们排除。此外,不使用深度卷积来代替池化,因为模型更专注于在没有轻量级卷积帮助的情况下构建架构。
为了了解这2个 token mixer 的延迟,进行了以下两个比较:
-
首先,通过比较
PoolFormer-s24和LeViT-256,观察到Reshape操作是LeViT-256的瓶颈。LeViT-256的大部分是在 4D 张量上使用 Conv 实现的,在将特征转发到MHSA时需要频繁的Reshape操作,因为必须在修补后的 3D 张量上执行注意力(丢弃注意力头的额外维度)。Reshape的广泛使用限制了LeViT在移动设备上的速度(图 2)。另一方面,当网络主要由基于 Conv 的实现组成时,池化自然适合 4D 张量,例如,作为 MLP 实现的 Conv 1×1 和用于下采样的 Conv stem。因此,PoolFormer表现出更快的推理速度。 -
其次,通过比较
DeiT-S和LeViT-256发现如果特征尺寸一致且不需要Reshape,MHSA不会给手机带来显著的计算开销。尽管计算量更大,但具有一致 3D 特征的DeiT-S可以实现与新的ViT变体(即LeViT-256)相当的速度。
因此在本文的工作中,提出了一个具有 4D 特征实现和 3D MHSA 的维度一致网络,但消除了低效的频繁 Reshape 操作。
观察3:CONV-BN比LN-Linear更利于延迟,并且精度降低通常是可以接受的。
选择 MLP 实现是另一个重要的设计选择。通常,选择以下2个选项之一:使用 3D 线性投影的 层归一化(LN)和使用 批量归一化 (BN) 的 Conv1×1。Conv-BN 对延迟更有利,因为 BN 可以融合到前面的卷积中以加快推理速度,而 LN 仍然在推理阶段收集运行统计信息,从而导致延迟。根据实验结果和之前的工作,LN 引入的延迟占整个网络延迟的 10%-20% 左右。
根据消融研究,与 LN 相比,Conv-BN 仅略微降低了性能。在这项工作中,尽可能多地应用 Conv-BN以获得可忽略不计的性能下降的延迟增益,同时将 LN 用于 3D 特征,这与 ViT 中的原始 MHSA 设计一致并且产生更好准确性。
观察4:非线性的延迟取决于硬件和编译器
最后,研究非线性,包括 GeLU、ReLU 和 HardSwish。以前的工作表明 GeLU 在硬件上效率不高,并且会减慢推理速度。但是,作者观察到 GeLU 得到 iPhone 12 的良好支持,并且几乎不比其对应的 ReLU 慢。相反,在实验中,HardSwish 的速度出奇地慢,编译器可能无法很好地支持(LeViT-256 的 HardSwish 延迟为 44.5 毫秒,而 GeLU 为 11.9 毫秒)。得出的结论是,非线性应该根据特定硬件和编译器的具体情况逐个确定。在这项工作中,使用了 GeLU 激活。
3EfficientFormer的设计
基于延迟分析,提出了 EfficientFormer 的设计,如图 3 所示。该网络由 patch embedding (PatchEmbed) 和meta transformer blocks,堆栈组成,表示为 MB:

其中
是输入图像,批大小为 B,空间大小为 [H,W],Y是所需的输出,m是Block的总数(深度)。MB由未指定的TokenMixer和一个MLP Block组成,可以表示如下:
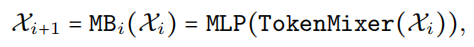
其中
是转发到第 i 个 MB 的中间特征。进一步将 Stage 定义为处理具有相同空间大小的特征的几个 MetaBlock 的堆栈,例如图 3 中的
表示 S1 具有
个 MetaBlock。
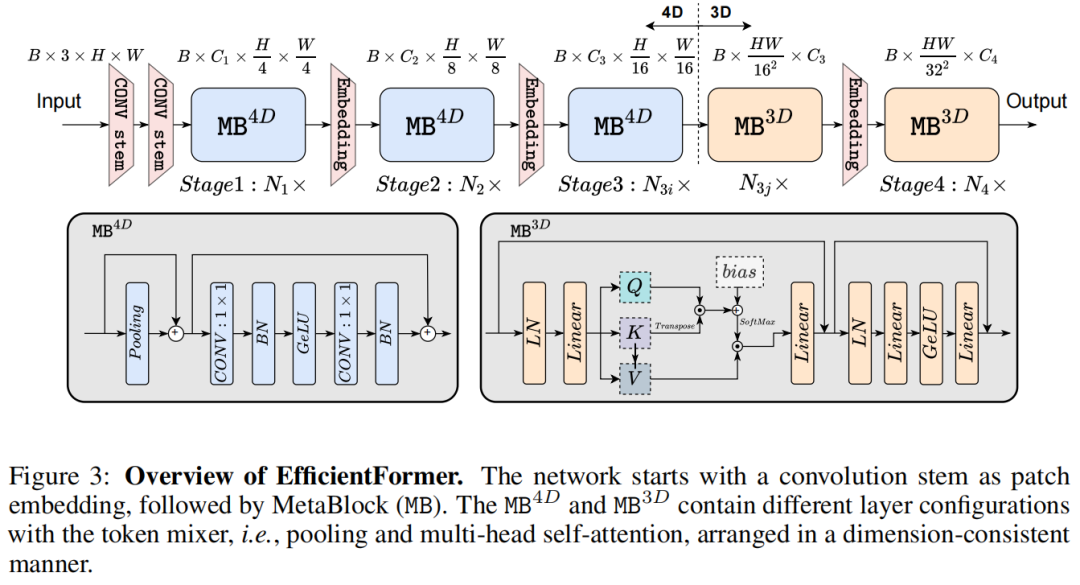
该网络包括 4 个阶段。在每个阶段中,都有一个嵌入操作来投影嵌入维度和下采样Token长度,在图 3 中表示为嵌入。在上述架构下,EfficientFormer 是一个完全基于Transformer的模型,没有集成 MobileNet 结构。
3.1 维度一致的设计
本文提出了一种维度一致的设计,将网络分成一个 4D 分区,其中算子以 ConvNet 样式 (MB4D) 实现,以及一个 3D 分区,其中线性投影和注意力在 3D 张量上执行,以利用 MHSA 的全局建模能力,而无需牺牲效率(MB3D),如图3所示。具体来说,网络从4D分区开始,而3D分区在最后阶段应用。请注意,图 3 只是一个实例,4D 和 3D 分区的实际长度是稍后通过架构搜索指定的。
首先,使用由具有2个 kernel-size为3×3, Stride为 2的卷积组成的 Conv stem处理后的图像作为 patch embedding,

其中
是第 j 个阶段的通道数(宽度)。然后网络从 MB4D 开始,使用简单的Pool mixer来提取 low level特征,
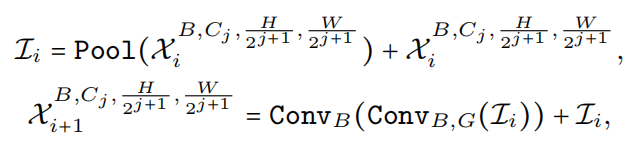
其中
是指卷积后是否分别跟BN和GeLU。注意这里没有在Pool mixer之前使用 Group Normalization 或 Layer Normalization (LN),因为 4D 分区是基于 CONV-BN 的设计,因此每个Pool mixer前面都有一个 BN。
在处理完所有 MB4D 块后,执行一次Reshape以变换特征大小并进入 3D 分区。MB3D 遵循传统的 ViT 结构,如图 3 所示。形式上,
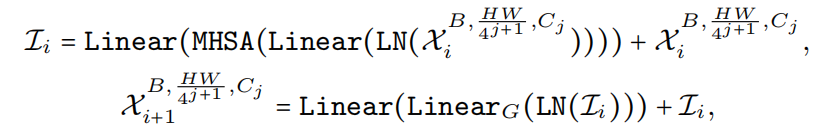
其中
表示线性后跟 GeLU,并且
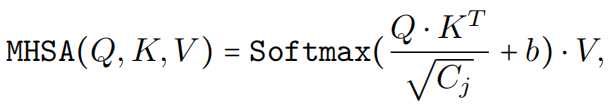
其中 Q、K、V 表示通过线性投影学习的query、key和value,b 是作为位置编码的参数化注意力偏差。
3.2 延迟驱动Slimming
1、SuperNet的设计
基于维度一致的设计,构建了一个Supernet,用于搜索图 3 所示网络架构的高效模型(图 3 显示了搜索到的最终网络的示例)。为了表示这样一个Supernet,定义了 MetaPath (MP),它是可能块的集合:
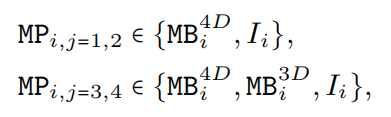
其中 I 表示identity path,j 表示第 j 个阶段,i 表示第 i 个块。Supernet可以通过用 MP 代替图 3 中的 MB。
在Supernet的第1阶段和第2阶段中,每个Block可以选择 MB4D 或 I,而在第3阶段和第4阶段中,Block可以是 MB3D、MB4D 或 I。
本文只在最后两个阶段启用 MB3D,原因有2个:首先,由于 MHSA 的计算相对于Token长度呈二次增长,因此在早期集成它会大大增加计算成本。其次,将全局 MHSA 应用于最后阶段符合直觉,即网络的早期阶段捕获低级特征,而后期层则学习长期依赖关系。
2、搜索空间
搜索空间包括 (每个 Stage 的宽度)、 (每个 Stage 中的块数,即深度)和最后 N 个要应用 MB3D 的块。
3、搜索算法
以前的硬件感知网络搜索方法通常依赖于每个候选者在搜索空间中的硬件部署来获得延迟,这是非常耗时的。在这项工作中,提出了一种简单、快速但有效的基于梯度的搜索算法,以获得只需要训练一次Supernet的候选网络。

3.3 模型架构
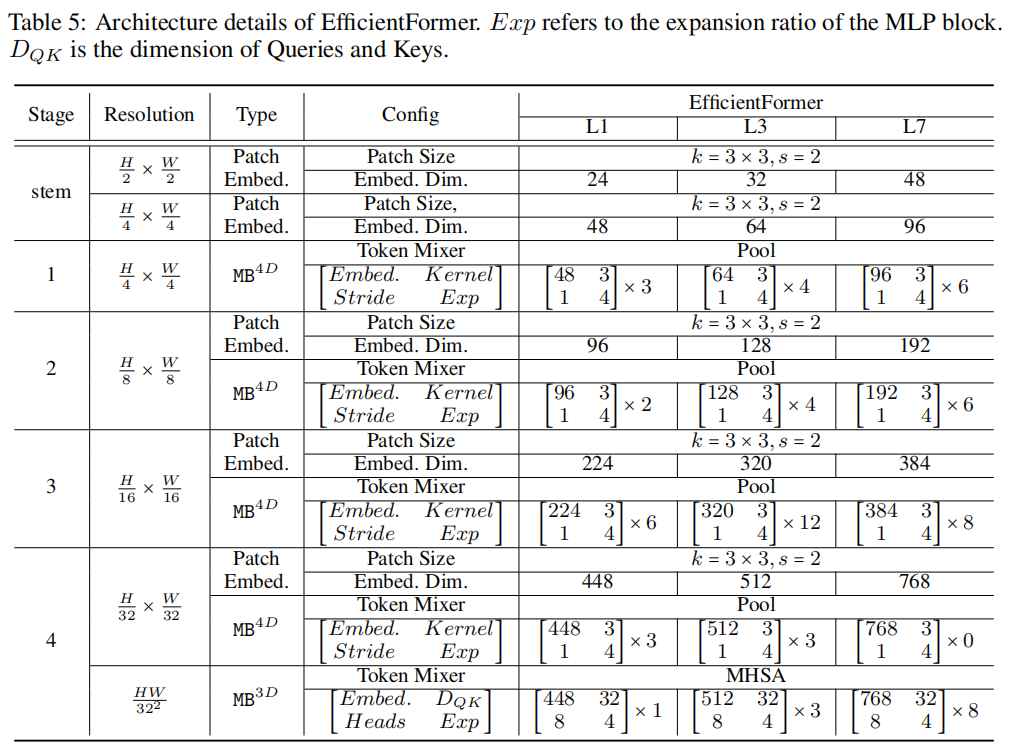
4实验
4.1 分类实验
4.2 目标检测与语义分割
上面论文和代码下载
后台回复:EfficientFormer,即可下载上面的论文
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号


整理不易,请点赞和在看
