TopFormer:打造Arm端实时分割与检测模型,完美超越MobileNet!

极市导读
在本文中,作者提出了一种移动端友好的架构,名为Token Pyramid Vision Transformer。实验结果表明,TopFormer在多个语义分割数据集上显著优于基于CNN和ViT的网络,并在准确性和实时性之间取得了良好的权衡。>>加入极市CV技术交流群,走在计算机视觉的最前沿

虽然ViT在计算机视觉方面取得了巨大的成功,但巨大的计算成本阻碍了它们在密集的预测任务上的应用,如在移动设备上的语义分割。
在本文中,作者提出了一种移动端友好的架构,名为Token Pyramid Vision Transformer(
TopFormer)。所提出的最优算法以不同尺度的Token作为输入,产生尺度感知的语义特征,然后将其注入到相应的Token中,以增强表征。
实验结果表明,
TopFormer在多个语义分割数据集上显著优于基于CNN和ViT的网络,并在准确性和实时性之间取得了良好的权衡。在ADE20K数据集上,TopFormer的mIoU比MobileNetV3的延迟更高5%。此外,TopFormer的小版本在基于ARM的移动设备上实现实时推理,具有竞争性的结果。
开源地址:https://github.com/hustvl/TopFormer
1 背景
为了使ViT适应各种密集的预测任务,最近的ViTs,如PVT、CvT、LeViT以及MobileViT都采用了分层结构,类似的操作也用于卷积神经网络(CNNs),如AlexNet和ResNet。这些ViTs将全局自注意力及其变体应用到高分辨率Token上,由于Token数量的二次复杂度,这带来了巨大的计算成本。
为了提高效率,最近的一些工作,如Swin-Transformer、Shuffle-Transformer、Twins和HR-Former,都在计算在局部/窗口区域内的自注意力。然而,窗口分区在移动设备上是非常耗时的。此外,Token slimming和Mobile-Former通过减少Token的数量而降低了计算能力,但也牺牲了它们的精度。
在这些ViTs中,MobileViT和Mobile-Former是专门为移动设备设计的。它们都结合了CNN和ViT的优势。在图像分类方面,MobileViT比与参数数量相似的MobileNets具有更好的性能。Mobile-Former在比MobileNets更少的FLOPs的情况下取得了更好的性能。然而,与MobileNets相比,它们在移动设备上的实际延迟方面并没有显示出优势。这提出了一个问题:是否有可能设计出移动友好型网络,在移动语义分割任务上获得更好的性能?
MobileViT和Mobile-Former的启发,作者也利用了CNN和ViT的优势。构建了一个基于CNN的模块,称为Token Pyramid Module,用于处理高分辨率图像,以快速生成局部特征金字塔。考虑到在移动设备上非常有限的计算能力,在这里使用一些堆叠的轻量级MobileNetV2 Block和Fast Down-Sampling策略来构建一个Token Pyramid。
为了获得丰富的语义和较大的感受野,作者还构建了一个基于ViT的模块,即Semantics Extractor,并将Token作为输入。为了进一步降低计算成本,使用Average Pooling Operator将Token减少到一个非常小的数字,例如,输入大小的1/(64×64)。
与ViT不同,T2T-ViT和LeViT使用嵌入层的最后一个输出作为输入Token,而TopFormer将来自不同尺度(阶段)的Token池化到非常小的数字(分辨率),并沿着通道维度进行拼接。然后,新的Token被输入到Transformer Block中以产生全局语义。由于Transformer Block中的残差连接学习到的语义与Token的尺度有关,因此该模块被表示为Scale-aware Global Semantics。
为了获得密集预测任务的强大层次特征,将尺度感知的全局语义通过不同尺度的Token通道进行分割,然后将标度感知的全局语义与相应的Token融合,以增强表示。增强的Token被用作分割Head的输入。
为了证明方法的有效性,在具有挑战性的分割数据集上进行了实验:ADE20K,Pascal上下文和COCOStuff。并测试了硬件上的延迟,即一个现成的基于Arm的计算核心。
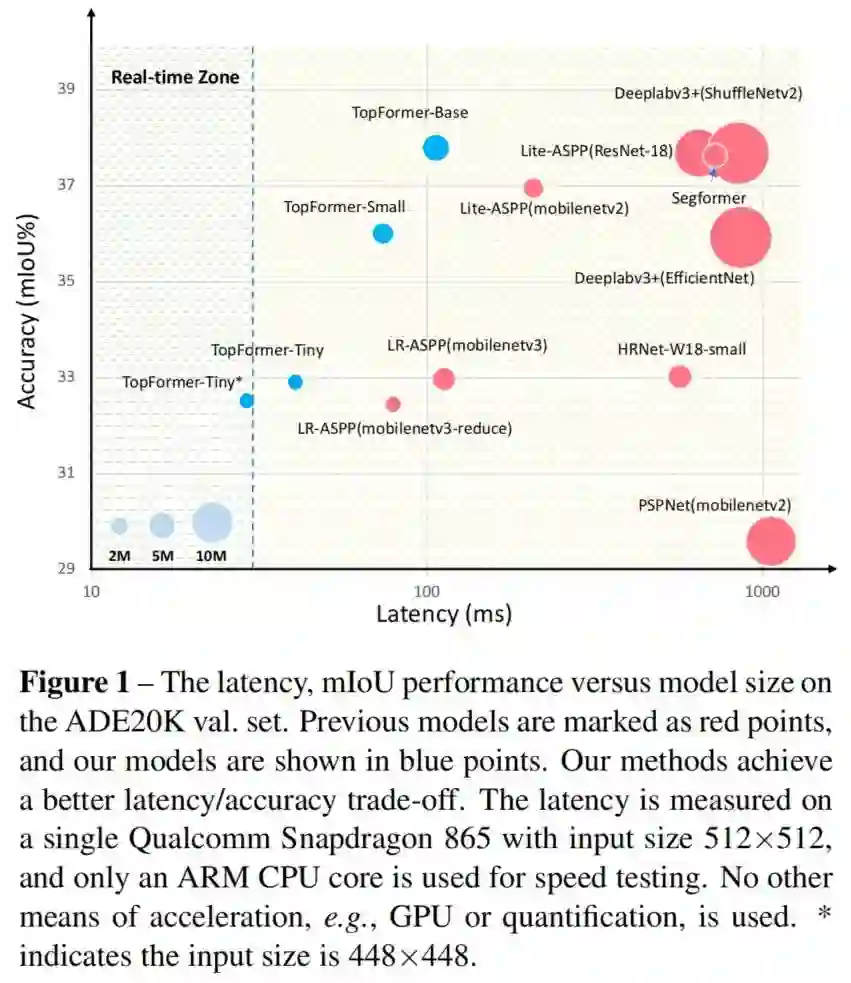
如图1所示,TopFormer比延迟较低的MobileNets获得了更好的结果。为了证明方法的泛化性,还在COCO数据集上进行了目标检测实验。
综上所述,本文的贡献如下:
-
所提出的最优预测算法以不同尺度的 Token作为输入,并将Token池化到非常小的尺寸,以获得计算代价非常轻的Scale-aware Global Semantics; -
所提出的 Semantics Injection Module可以将Scale-aware Global Semantics注入到相应的Token中,构建强大的层次特征; -
与 MobileNetV3相比,TopFormer可以实现5%的mIoU提升,在ADE20K数据集上基于Arm的移动设备上的延迟更低。TopFormer-Tiny可以在基于Arm的移动设备上进行实时分割。
2 相关工作
2.1 轻量化Vision Transformers
其实以及有很多工作对Vision Transformers结构在图像识别中的应用进行了探索。ViT是第一个将纯Transformer应用于图像分类的工作,实现了最先进的性能。随后,DeiT引入了基于Token的蒸馏,以减少训练Transformer所需的数据量。T2T-ViT通过递归地将相邻Token聚合为一个Token来减少Token长度。Swin-Transformer在每个局部窗口内计算自注意力,带来了输入Token数量的线性计算复杂度。然而,这些Vision Transformers和后续工作往往是大量的参数和沉重的计算复杂度。
为了构建一个轻量级的Vision Transformer,LeViT设计了一个混合架构,使用堆叠的标准卷积层和stride=2来减少Token的数量,然后附加一个改进的Vision Transformer来提取语义。在分类任务中,LeViT在CPU上的性能明显优于EfficientNet。
MobileViT也采用了相同的策略,并使用MobilenetV2 Block而不是标准的卷积层来对特征图进行降采样。Mobile-Former采用并行结构与双向桥,利用了MobileNet和Transformer的优势。然而,有研究表明MobileViT和其他ViT-based的网络在移动设备上明显慢于MobileNets。
对于分割任务,输入的图像总是高分辨率的。因此,ViT-based网络比MobileNets的执行速度更具挑战性。本文中的目标是设计一个轻量级的视Vision Transformer,同时改模型可以超过MobileNets,以实现实时的分割任务。
2.2 高效的卷积神经网络
对在移动和嵌入式设备上部署视觉模型的需求不断增加,鼓励了对高效卷积神经网络设计的研究。MobileNet提出了一种inverted bottleneck的结构,该结构主要是叠加了Depth-wise和Point-wise卷积。IGCNet和ShuffleNet使用通道Shuffle/Permutation操作,为多个组卷积层进行跨Group信息流。GhostNet使用更简单的操作符,即Depth-wise卷积,来生成更多的特性。AdderNet利用add来替换大量的乘法。MobileNeXt翻转了反向残差块的结构,并呈现了一个连接高维表示的构建块。EfficientNet和TinyNet研究了深度、宽度和分辨率的复合尺度。
2.3 移动端语义分割
最精确的分割网络通常需要数十亿个FLOPs的计算,这可能会超过移动设备和嵌入式设备的计算能力。为了加快分割速度和降低计算成本,ICNet使用多尺度图像作为输入,并使用级联网络来提高计算效率。DFANet利用一个轻量级的Backbone来加速其网络,并提出了一种跨级特征聚合来提高精度。SwiftNet使用横向连接作为经济有效的解决方案,在保持速度的同时恢复预测分辨率。BiSeNet引入了Spatial path和Semantic path来减少计算。AlignSeg和SFNet对齐了来自相邻level的特征映射,并使用特征金字塔框架进一步增强了特征映射。ESPNets通过将标准卷积分解为Point-wise convolution和Spatial pyramid of dilated convolution来节省计算。
3 本文方法
TopFormer的整体网络架构如图2所示。网络由几个部分组成:
-
Token Pyramid Module -
Semantics Extractor -
Semantics Injection Module -
Segmentation Head
Token Pyramid Module将一个图像作为输入,并生成Token Pyramid。
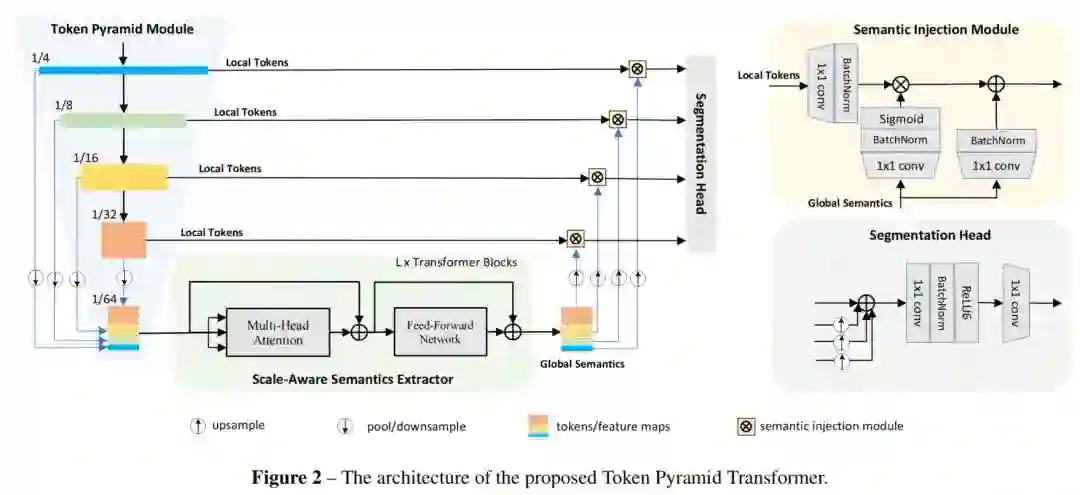
3.1 Token Pyramid Module
受MobileNets的启发,所提出的Token Pyramid Module由堆叠的MobileNet blocks组成。与MobileNets不同,Token Pyramid Module的目标并不是获得丰富的语义和较大的感受野,而是使用更少的块来构建Token Pyramid。
如图2所示,把一个图像作为输入,其中3,H,W分别表示RGB通道,高度,宽度;
Token Pyramid Module:
-
首先,通过一些 MobileNetV2 Block产生一系列Token,N表示Scale的数量。 -
然后,将 Token平均池化到目标大小,例如, 。 -
最后,将来自不同尺度的 Token沿着通道维度连接起来,产生新的Token。新的Token将被输入Vision Transformer,以产生具有尺度感知的语义特征。
由于新的Token的数量较小,因此即使新的Token具有较大的通道,Vision Transformer也可以以非常低的计算成本运行。
3.2 Scale-aware Semantics Extractor
Scale-aware Semantics Extractor由几个堆叠的Transformer Block组成。Transformer Block数为L。
-
Transformer Block由Multi-head Attention module、FFN和残差连接组成。 -
为了保持 Token的空间形状和减少重塑的数量,这里将线性层替换为1×1的卷积层。 -
此外,在ViT中,所有的非线性激活都是 ReLU6,而不是GELU。
对于Multi-head Attention module,遵循LeViT的配置,将key K和query Q的Head尺寸设置为D=16,value V的head 设置为2D=32通道。在计算Attention Map和输出时,减少K和Q的通道将降低计算成本。同时,还去掉了Layer Normalization Layer,并向每个卷积添加了Batch Normalization。在推理过程中,Batch Normalization可以与前面的卷积融合。
对于FFN,通过在2个1×1卷积层之间插入一个Depth-wise卷积,来增强Vision Transformer的局部连接。将FFN的扩展系数设为2,以降低计算成本。Transformer Block的数量是L。
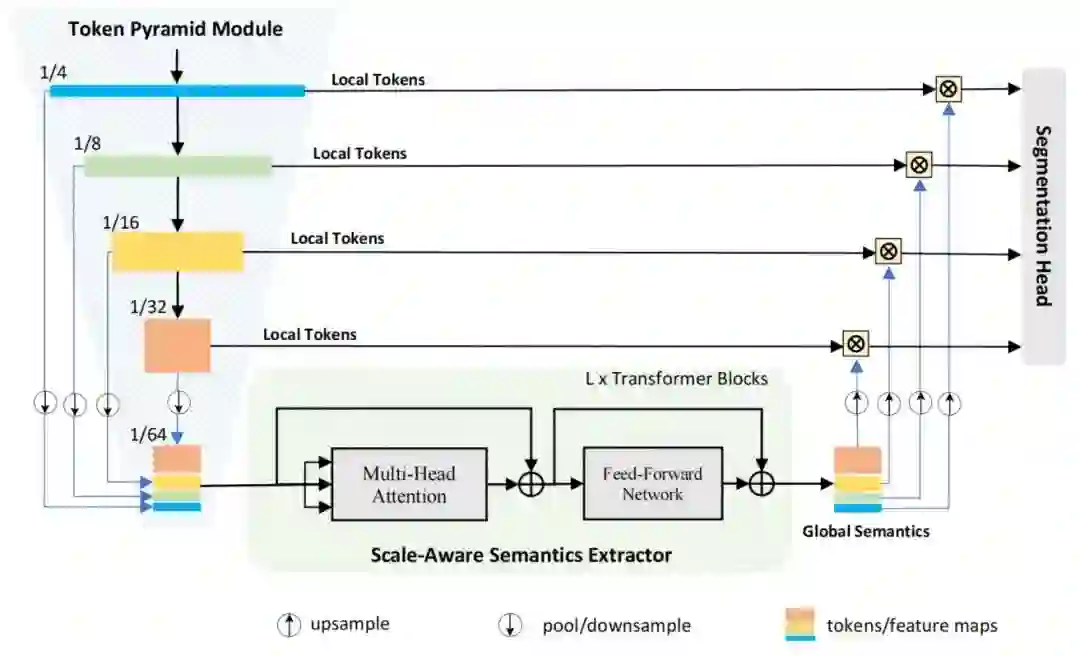
如图3所示,Vision Transformer将来自不同尺度的Token作为输入。为了进一步减少计算量,使用平均池化操作将不同尺度的Token数量减少到输入大小的
。来自不同尺度的集合Token具有相同的分辨率,它们被连接在一起作为Vision Transformer的输入。Vision Transformer可以获得全图像的感受野和丰富的语义。
更具体地说,全局自注意力在空间维度的Token之间交换信息。1×1卷积层将在来自不同尺度的Token之间交换信息。在每个Transformer Block中,在交换来自所有尺度的Token信息后学习残差映射,然后将残差映射添加到Token中,以增强表示和语义。最后,在通过几个Transformer Block后,获得了尺度感知语义。
3.3 Semantics Injection Module and Segmentation Head
在获得尺度感知语义, 直接将它们与其他 Token 相加。然而, 在 Token 和尺 度感知语义之间存在着显著的语义差距。为此, 引入了 Semantics Injection Module 来缓 解在融合这些 Token 之前的语义差距。
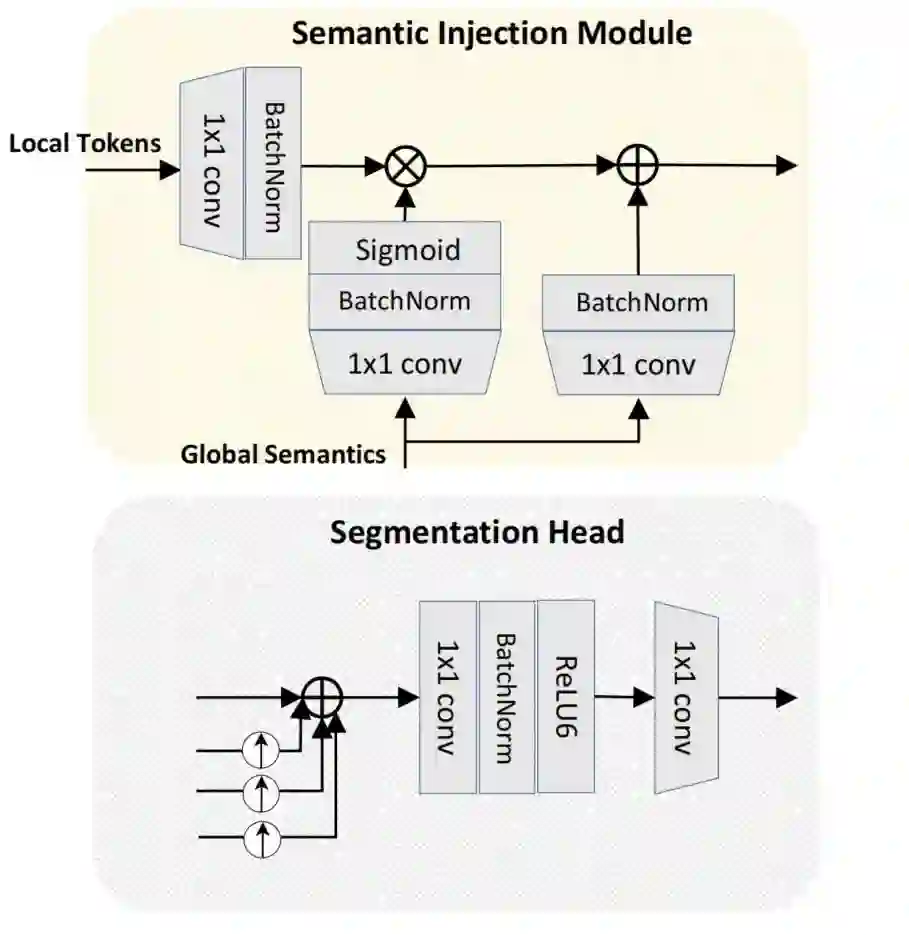
如图4所示,
Semantics Injection Module(SIM)以Token Pyramid Module的局部Token和Vision Transformer的全局语义作为输入。
局部
Token通过1×1卷积层,然后进行批归一化,生成要注入的特征。
全局语义输入
1×1卷积层+批归一化层+sigmoid层产生语义权重,同时全局语义也通过1×1卷积层+批归一化。
这3个输出的大小相同。然后,通过阿达玛生产将全局语义注入到局部标记中,并在注入后添加全局语义和特征。几个sim的输出共享相同的通道数,记为M。经过Semantics Injection Module后,来自不同尺度的增强Token同时捕获了丰富的空间信息和语义信息,这对语义分割至关重要。此外,Semantics Injection Module还缓解了Token之间的语义差距。所提出的Segmentation Head首先将低分辨率Token上采样到与高分辨率Token相同的大小,并按元素方式对所有尺度的Token进行sum up。最后,将该特征通过2个卷积层,生成最终的分割图。
3.4 架构及其变体
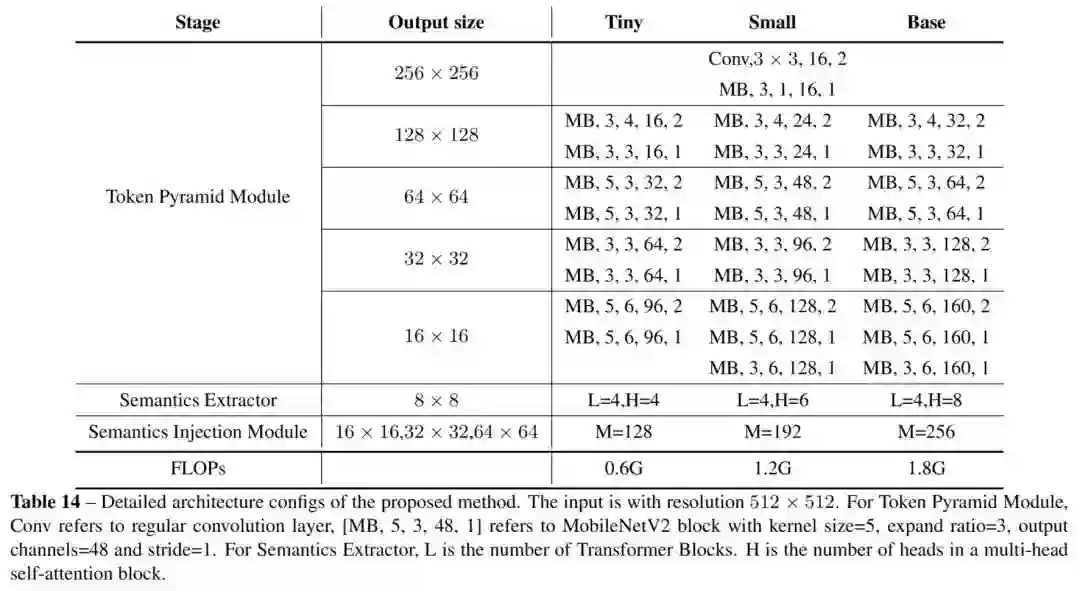
为了定制各种复杂的网络,作者设计了TopFormer-Tiny (TopFormer-T)和TopFormer-Small(TopFormer-S)和TopFormer-Base(TopFormer-Base)。
下表给出了Base、Small以及Tiny模型的尺寸和FLOPs。Base、Small以及Tiny模型在每个Multi-Head self-attention module中分别有8、6和4个Head,以M=256、M=192和M=128为目标通道数。各个版本的模型配置如下:
4 实验
4.1 消融实验
1、Token Pyramid的影响
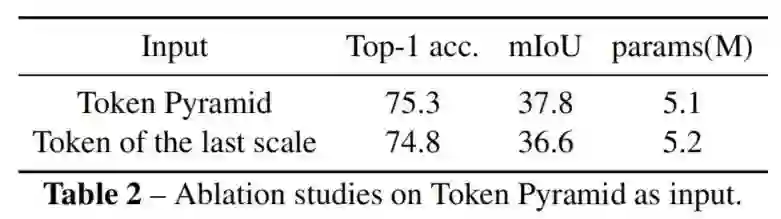
如表所示,将来自不同尺度的堆叠Token作为语义提取器的输入,并将最后一个Token分别作为语义提取器的输入。为了公平的比较,附加了一个1×1卷积层来扩展与堆叠的Token一样的通道。实验结果证明了使用Token Pyramid作为输入的有效性。
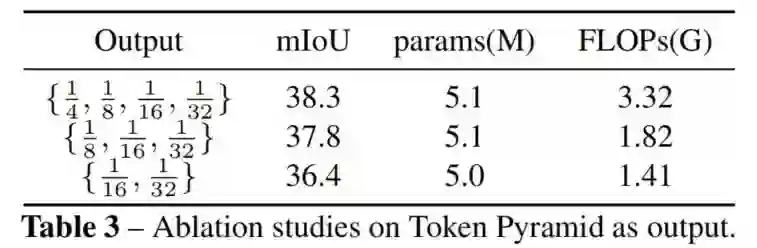
如表3所示,使用{1/4,1/8,1/16,1/32}的Token可以在最重的计算下获得最佳性能。使用{1/16,1/32}的Token在最轻的计算下获得较差的性能。为了在精度和计算成本之间实现良好的权衡,作者选择在所有其他实验中使用{1/8,1/16,1/32}的Token。
2、Scale-aware Semantics Extractor的影响
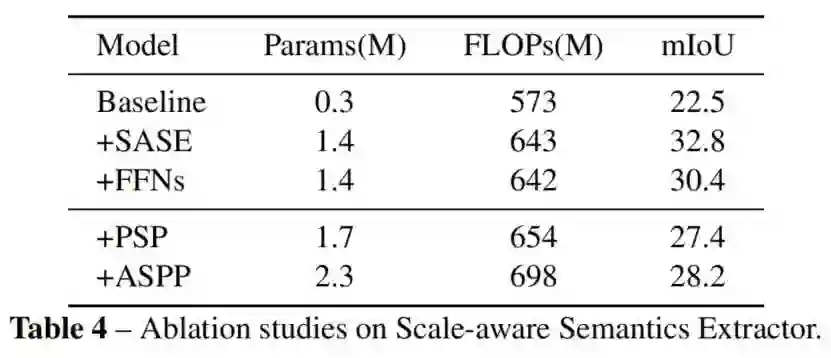
结果如表所示。在这里使用不带SASE的Topformer作为基线。加入SASE将带来约10%的mIoU收益,这是一个显著的改善。为了验证Transformer Block中的多头自注意力模块(MHSA),删除了所有的MHSA模块,并添加了更多的ffn,以进行公平的比较。结果表明,在精心的架构设计下是一个高效有效的模块中MHSA可以获得约2.4%的mIoU收益。同时,将SASE与流行的上下文模型进行了比较,如ASPP和PPM。
如表4所示,“+SASE”比“+PSP”和“+ASPP”可以以更低的计算成本获得更好的性能。实验结果表明,SASE更适合用于移动设备。
3、Semantic Injection Module和Segmentation Head的影响
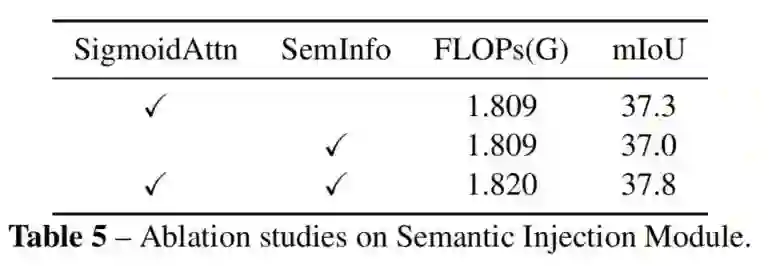
如表所示,将局部Token与Sigmoid层之后的语义相乘,表示为“SigmoidAttn”。将语义提取器中的语义添加到相应的局部Token中,称为“SemInfo”。与“SigmoidAttn”和“SemInfo”相比,同时添加“SigmoidAttn”和“SemInfo”通过一点额外的计算可以带来很大的改进。
在这里还讨论了Segmentation Head的设计。将特征传递到Semantic Injection Module后,输出的层次特征具有较强的语义和丰富的空间细节。提出的Segmentation Head简单地将它们相加,然后使用2个1×1卷积层来预测分割图。

作者还设计了另外2个分割头,如图所示。Sum Head等同于只在SIM中添加SemInfo。Concat Head使用1×1卷积层来减少SIM输出的通道,然后将特征拼接在一起。
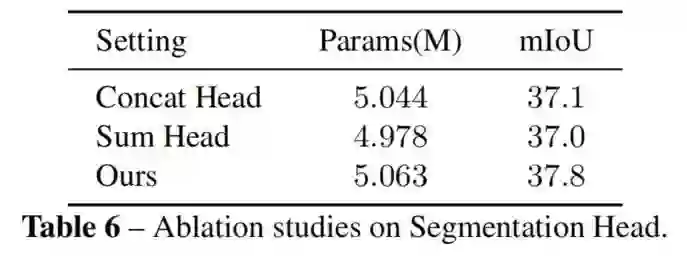
如表所示,与Concat head和Sum head相比,目前的Segmentation Head可以取得更好的性能。
4、SIM宽度的影响
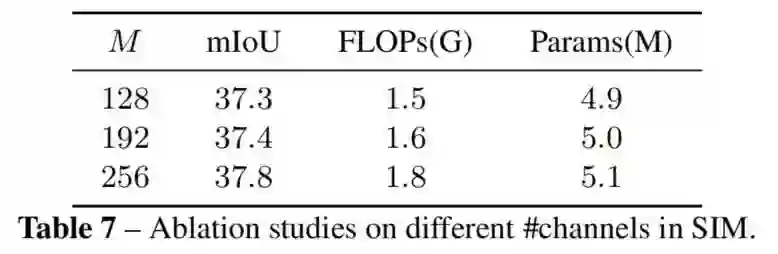
如表所示,M=256,192,128通过非常接近的计算实现了类似的性能。因此,在tiny, small和base模型中分别设置M=128,192,256。
5、output stride的影响
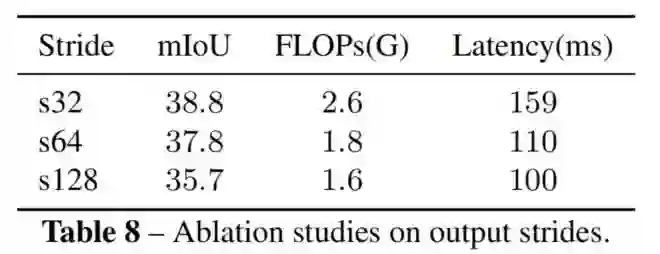
不同分辨率的结果如表所示。s32、s64、s128表示集合分辨率为输入大小的 、 。考虑到计算量和精度的权衡性, 选择s64作为语义提取器的输入 Token 的输出 stride。
6、参数量与实时性
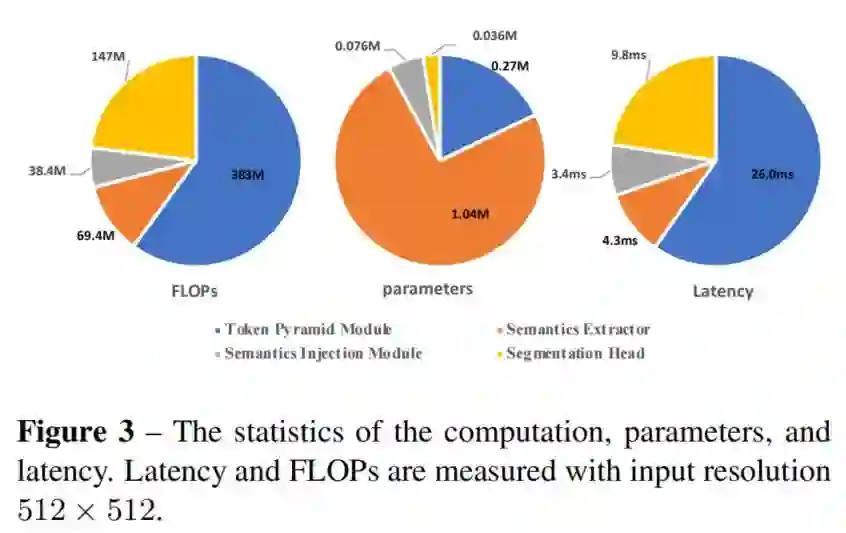
如图所示,虽然语义提取器具有大部分参数(74%),但语义提取器的FLOPs和实际延迟相对较低(约10%)。
4.2 图像分类
为了进行公平的比较,作者还使用了ImageNet的预训练参数作为初始化。如图所示,提出的TopFormer的分类架构,将平均池化层和线性层附加到全局语义上,以生成类分数。
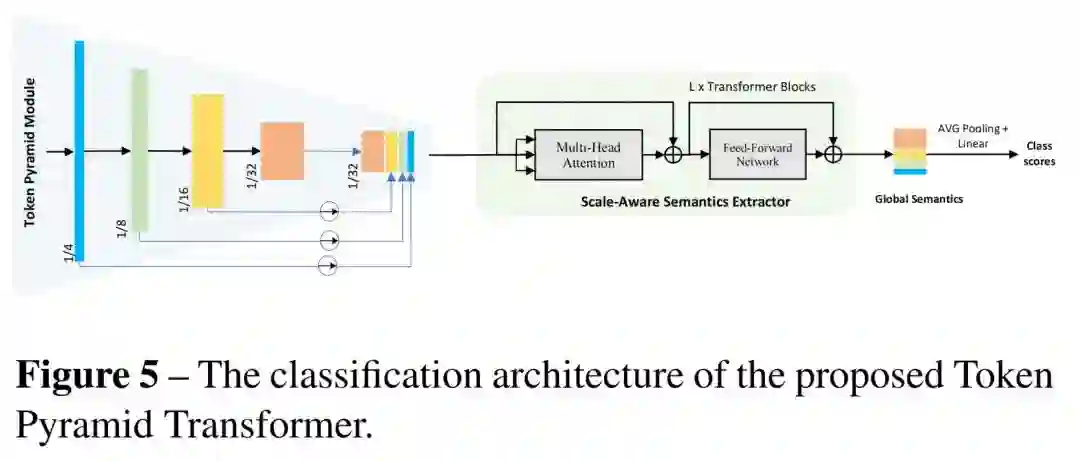
由于输入图像的分辨率较小(224×224),这里将语义提取器的输入Token的目标分辨率设置为输入大小的
。

4.3 语义分割
1、ADE20K

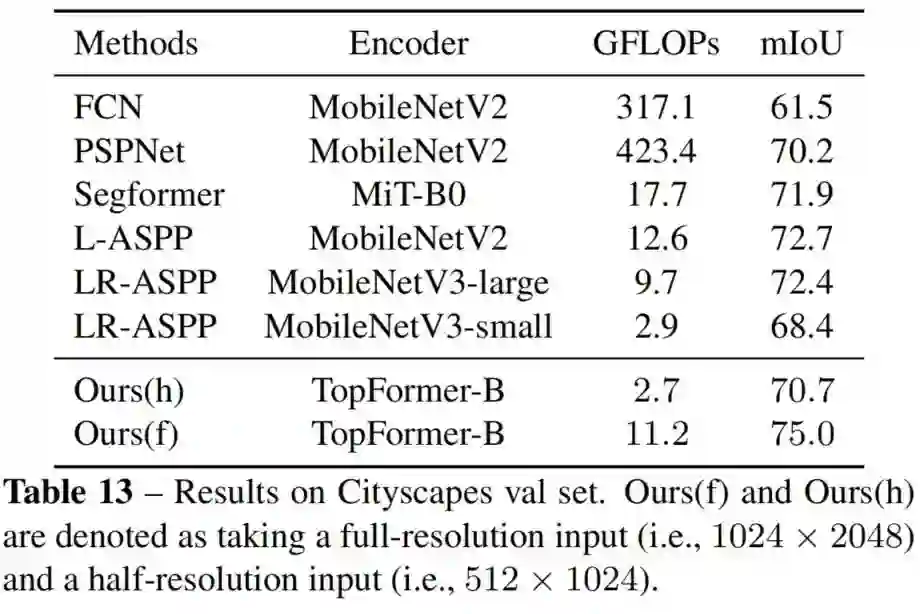
2、Cityscapes
3、可视化结果

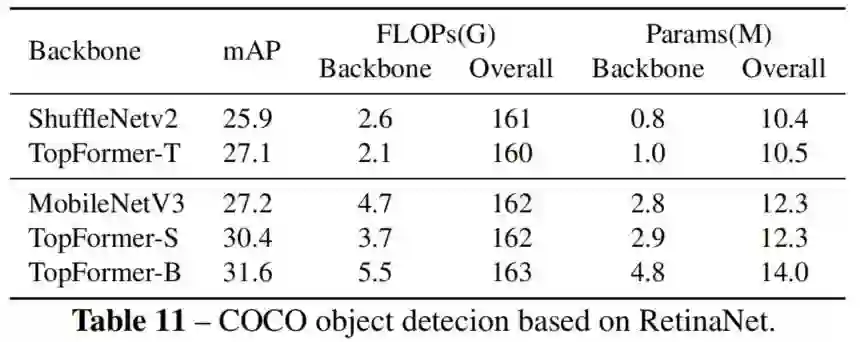
4.4 目标检测
参考
[1].TopFormer:Token Pyramid Transformer for Mobile Semantic Segmentation
公众号后台回复“数据集”获取30+深度学习数据集下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~



