把Transformer结构剪成ResNet结构!新的MSA和卷积操作之间的权重共享方案

极市导读
本文提出了一种新的 MSA 和卷积操作之间的权重共享方案,该方案允许在单路径框架中将所有候选NAS操作编码到MSA层中。然后,将搜索问题转换为寻找MSA参数的子集,从而显著降低搜索成本。>>加入极市CV技术交流群,走在计算机视觉的最前沿

Vision Transformers(ViTs)在各种计算机视觉任务中取得了非常不错的性能。然而,使用multi-head self-attention(MSA)建模全局关联会带来2个问题:大量的计算资源消耗和缺乏作用于局部特征建模的内在归纳偏差。
目标比较一致的解决方案是通过基于神经架构搜索(NAS)的剪枝方法,寻找是否用类似卷积的归纳偏差来替换一些MSA层,这些归纳偏差具有比较高计算效率。然而,将MSA和不同的卷积操作保持为独立的可训练路径,会导致昂贵的搜索成本和具有挑战性的优化。
相反,本文提出了一种新的MSA和卷积操作之间的权重共享方案,并将搜索问题转换为在每个MSA层中寻找参数子集。权重共享方案进一步允许设计一种Single-Path Vision Transformer剪枝方法(SPViT),在给定目标效率约束的情况下,快速将预训练的vit剪枝成精确而紧凑的混合模型,并显著降低搜索成本。在两个具有代表性的ViT模型上进行了大量的实验,表明本文的方法实现了良好的精度-效率平衡。

论文地址:https://arxiv.org/abs/2111.11802
github地址:https://github.com/zhuang-group/SPViT
1 简介
Vision Transformers吸引了大量的研究,并成为各种图像识别任务的Backbone之一,如分类、分割和检测。
但MSA引入的ViT的两个局限性已经被认识到。首先,MSA层的一个众所周知的问题是二次时间和内存复杂性,这阻碍了vit的大规模开发和部署,特别是对于长序列的建模。为此,人们已经做出了许多努力来开发高效的Transformer,例如采用修剪方法来修剪不太重要的ViT组件。
另一个基本问题是MSA层缺乏用于编码局部信息的归纳偏差,这对于处理low-level特征(如边缘和形状)至关重要。为了解决这个问题,现有技术在ViT中插入卷积层来引入归纳偏差,例如,在ViT编码器之前或MSA层之前的内部引入前馈网络层(FFNs)。
解决这两个问题的一个统一解决方案是使用NAS剪枝方法搜索出卷积替换部分MSA层。因此,可以消除一些昂贵的MSA层,以显著提高ViT模型的效率,同时添加适当的局部性,而不需要启发式。
最近,一些单次NAS方法建议将候选MSA和卷积操作分别包含到搜索空间中,其中每个操作都被表述为一个单独的可训练路径(参见图1(a))。然而,由于在搜索过程中,每一层的所有候选操作都需要独立维护和更新,因此这些多路径方法会带来昂贵的搜索成本和具有挑战性的优化。
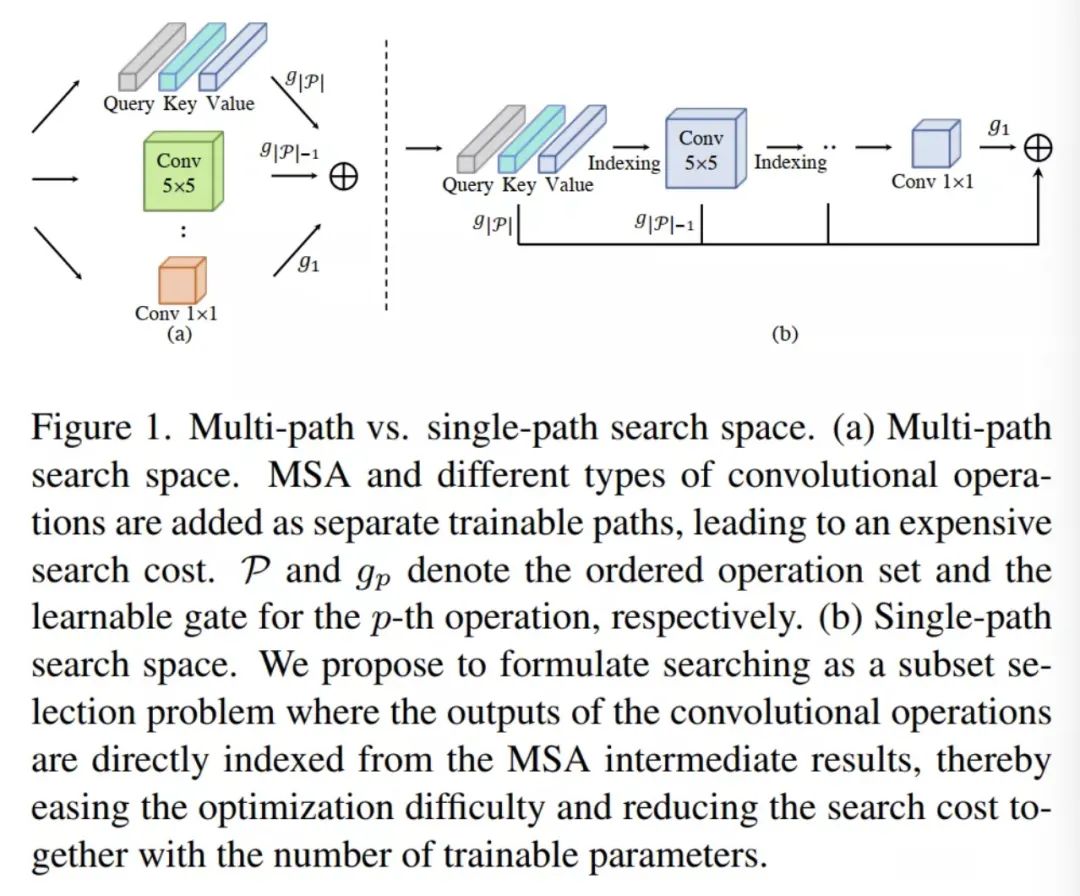
为了解决这一局限性,本文提出了一种新的Single-Path Vision Transformer剪枝方法,称为SPViT;SPViT以低搜索成本和高准确率将预训练的 ViT 剪枝到紧凑的模型中。
具体来说,由于观察到MSA层具有建模局部特征的能力,并且 MSA Head 有时会关注局部特征,作者开发了 MSA 和卷积操作之间的权重共享方案。因此,可以利用预训练的MSA参数获得较好的卷积核权值初始化,并在搜索过程中通过索引MSA中间结果轻松地得到卷积运算的输出。
通过进一步将所有候选操作封装到每个层的单个MSA中形成了如图1(b)所示的单路径搜索方案。不需要像在多路径方法中那样选择不同的操作,相反,这里将搜索问题定义为在每个MSA层中寻找权重子集,从而在选择卷积层时将MSA剪枝到卷积层。
此外,考虑到FFN层消耗了很大比例的计算,例如当使用DeiT处理224×224图像时,17.5G的Mult-Adds中FFN占有11.1G,作者提出了一种简单而有效的方法来搜索细粒度的MLP扩展比率,为每个FFN层定制隐藏维度的数量。具体来说,SPViT使用可学习门来确定每个FFN隐藏维度的重要性,然后去掉不太重要的维度。
本文的主要贡献:
-
提出了一种新的 MSA 和卷积操作之间的权重共享方案,该方案允许在单路径框架中将所有候选NAS操作编码到MSA层中。然后,将搜索问题转换为寻找MSA参数的子集,从而显著降低搜索成本; -
在单路径方案的基础上,提出了SPViT,它可以自动将昂贵的全局MSA操作精简为轻量化的局部卷积操作,并在期望的效率约束下搜索细粒度的MLP扩展比; -
在CIFAR-100和ImageNet-1k实验表明SPViT能够显著降低搜索成本,同时性能优于Baseline方法。作者还对搜索的体系结构进行了一些有趣的观察,揭示了ViT的architecture preferences。
2 相关工作
2.1 Transformer剪枝
Transformer通常有昂贵的计算成本。为了减少这种成本,模型剪枝是产生高效Transformer的主要方法之一。现有的Transformer剪枝技术大致可以分为module剪枝和token剪枝。
module剪枝对不显著的Transformer modules进行修剪,如MSA层中的heads、linear projections通道和权重神经元。
最近,有学者提出动态识别和修剪不太重要的token特征维度。Chen等人在lottery ticket假设下提出了Transformer参数的prune-and-grow方法。
token剪枝侧重于修剪不太重要的token,如DynamicViT分层地修剪冗余token,从而在分类任务中实现FLOPs减少。然而,随着一些token的消除,将token剪枝方法应用于密集预测任务是一个挑战,如分割。
本文工作旨在对modules进行剪枝,但与之前的工作不同的是,本文着重于对MSA层中多余的全局关联进行剪枝。并没有以多路径的方式将卷积和MSA独立地添加到搜索空间中,而是考虑了这两种操作之间的内在关系,并将MSA层剪成卷积层,这允许以低搜索成本快速部署高效的Transformer模型。
2.2 卷积 vs 自注意力
本文工作是由最近探索卷积和自注意力层的性质的研究推动的。例如,卷积层在提取带有卷积归纳偏差的局部纹理线索方面表现出很强的能力。另一方面,自注意力层倾向于通过建模全局相关性来强调物体形状。
为了使用这两种操作的优点,有一种方法独立对待卷积层和自注意力层,并形成混合模型;例如,在ViTt中插入卷积层或将自注意力叠加在CNN之上。另一项工作探讨了两种操作之间的内在关系。其中,有研究表明,具有可学习的二次位置编码和丰富的Head数量的自注意力层可以表示任何卷积层。ConViT将soft inductive bias作为自注意力层的部分注意力得分,Transformed CNN学习将预处理卷积层转换为自注意力层。
本文的方法也属于后一种工作的范围。与之前的工作相比,针对MSA层强大的表达能力,作者提出了一种新的权重共享方案,表明MSA操作参数子集可以表达卷积操作。权重共享方案能够在单路径框架中将所有候选NAS操作编码到MSA层中,以降低搜索成本。作者还进一步设计SPViT来自动有效地将MSA操作精简为轻量级的卷积操作,同时享受局部性的好处。
3 本文方法
3.1 MSA和卷积运算之间的权重共享
1、回顾卷积和自注意力机制
权重共享方案是指在不同的操作之间共享一个参数子集。该方案的有效性已经被广泛的NAS方法所证明,例如,在候选卷积操作之间共享权重大大降低了搜索成本。在本文中提出了一种新的MSA和卷积运算之间的权重共享方案。
卷积层是CNNs的基本构建模块。设 和 特征, 卷积的为kernel-size为 , 其中 和 分别为空间宽度、高度、 输入维数和输出维数。标准卷积层将局部感受野中的特性进行聚合, 这些聚合的特 征被定义为:
形式上, 设 为特征宽度和高度的索引集, 处的标准卷积层的输出可以表示为:
Transformers以MSA层为主要构件。然而, MSA层的感受野更大, 覆盖了整个序 列, 而不是只聚合邻近的特征。将Eq.(1)中的输入X作为 维度嵌入的集合, 并让 作为任何关键特征嵌入的索引,可以定义 处MSA层的输出为:
式中,
, 为 MSA层的Head的数量。给定第h个head 的 输出维度为 , 定义 和 学习value、query和 key 线性投影。因此, 表示第 个 head的注attention map, 在 和 的索引下, 成为一个标量。为了简单起见,省略了MSA层中的位置编码,以及卷积和MSA层中伴随可学习投影的所有可学习偏置项。
MSA层的计算复杂度为 。在这种情况下, 当建模高分 辨率特征 , 新二次项建模全局相关性主导计算,计算复杂度也会随 之剧增。同时, 在标准卷积层输出具有相同宽度和高度的特征映射时, 卷积层的计 算复杂度仍然为 。
2、权重共享方案
首先,由于卷积运算只处理局部区域内的特征,因此在用MSA参数表示卷积运算时,每次嵌入时,将非局部相关的注意力分数固定为0,将局部相关的注意力分数固定为1。
代回式(2),得到:
在这里, 使用 来表示Eq.(3)中具有局部性限制的输出。在Eq.(4)中, 强 制MSA操作的head只关注以 为中心的大小为 的局部窗口内的位置。
其次, 可以进一步将MSA操作参数配置为卷积内核。一种方法是定义一个bijective 映射 , 它将选定的head子集 中的head分配到局部窗口中的特 定位置 。
然后可以用 带入h, 即
在Eq.(5)中, 每个head都关注局部窗口中的某个位置。然而, 许多ViT变体都有 , 如DeiT-Ti和DeiT-S, 这将限制权重分配方案仅适用于大型架构。此外, 在MSA层中, 不同的head倾向于关注不同的区域, 因此, 定义子集 和映射 来 识别最适合局部位置的head是很重要的。为了使权重分配方案适用于一般ViT架 构, 并减轻定义 和 的困难, 作者使用可学习参数 和softmax函数 将MSA集合到卷积kernel位置:
where
.
在这种情况下, 具有缩放因子 的MSA head集合学会关注局部 窗口 内预定义的位置。通过在z上使用softmax函数来确保head集合保持原来的比例。
然后, 通过将 替换为 并应用结合律, 可以将 剖分成Eq.(6)中的卷积核:
相反, 出于复杂性考虑, 选择bottleneck卷积运算并进行修改:
where
注意, 在这种形式下, 卷积运算 的输出维数 , 通过 将 投影回 。可以很容易地发现, Eq.(7) 中的 和Eq.(10)中的 都不大于 , 即head的 尺寸。但前者的计算复杂度为 , 后者的计算复杂度为 。由于 , 因此选择使用bottleneck卷积来获得更好的效率。
进一步添加BN和ReLU, 得到由 和 表示的kernel size为 的bottleneck卷积运算:
3、Remark
提出的权重共享方案鼓励MSA操作的head不仅建模全局区域,同时学习集合来处理局部区域特征。对这种方法的直观认识主要来自两个方面。
-
首先,局部区域确实是全局区域的一部分,因此MSA head集合自然具有处理局部区域的能力。 -
其次,由于ViT编码器中的一些head经常关注query像素周围的局部区域,用这些head表示卷积操作的行为可能会得到合理的输出。然而,考虑到不同的ViT模型添加locality的最佳位置可能有所不同,因此引入SPViT,它自动学习选择最优操作。
3.2 Single-path ViT剪枝
在权重共享方案的基础上进一步提出SPViT,通过自动将部分MSA层裁剪为卷积层,得到最优的精度-效率权衡的架构。此外,还研究了控制FFN层中隐藏维度数量的细粒度MLP扩展比率。
1、Search formulation
搜索MSA和卷积层
第一步:在ViT中寻找最优的位置将MSA层剪成卷积层。具体来说,在每个ViT块中,将每个原始的MSA层替换为一个Unified MSA(UMSA)层,该层通过3.1节描述的权重共享方案同时获得MSA的输出和卷积操作。
然后,定义一系列可学习的二进制门对应的操作,以编码体系结构配置。为此,在UMSA层中,当进行MSA操作时,可以根据Eq.(8)对V进行索引和缩放,直接得到预定义核的卷积输出,而不需要将每个候选卷积操作保持为单独的路径。
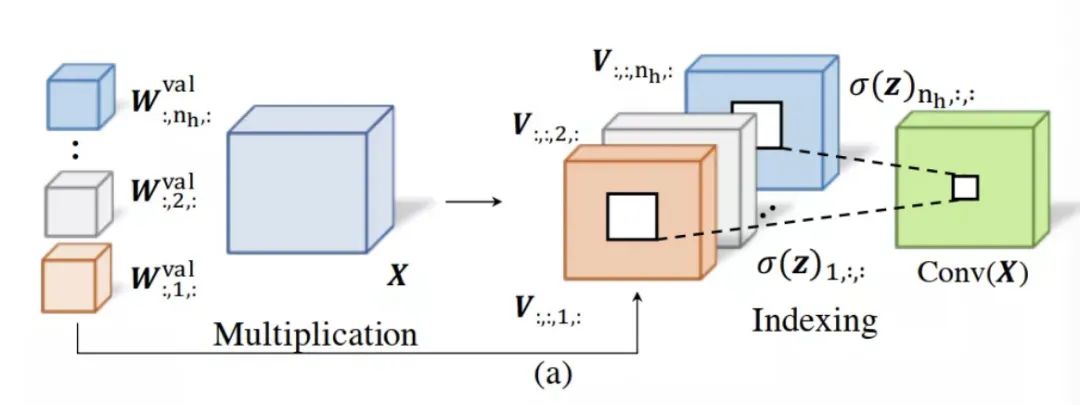
这个过程如图2(a)所示,然后通过Eq.(12)得到卷积运算输出BConvk(X)。
通过这种方法可以以较低的计算成本得到了BConv卷积和MSA的输出。
根据计算复杂度由低到高的顺序可以将BConv卷积和MSA表示为一个有序集P,其中|P| = |K|+1。
第二步: 定义一系列二进制门来编码操作选择。对于任何具有指数 的操 作, gateg 从具有可学习参数 的伯努利分布中采样, 该分布可以通过梯度自动优化。
具体来说, 使用 确定选择第p个操作的likehood:
出于效率考虑, 在每个层中只选择一个操作。通过这种方式, 强制每个UMSA层最 多有一个打开的gate, 将 替换为 :
式(14)本质上说明, 一旦选择了一个更复杂的门 , 所有不那么复杂的门都将关闭。因此, UMSA层的输出可以表示为:
其中 是第 个操作的输出。然后, 每个UMSA层后面跟着残差连接和层归一 化, 就像ViT做的那样。所有门关闭时采用shortcut操作。因此, UMSA搜索空间包 括3种类型的候选操作:ShortCut、不同kernel size的BConv卷积以及MSA。
2.搜索细粒度的MLP扩展率
MLP扩展率控制FFN层的隐藏尺寸数量。之前的工作将MLP扩展率的搜索空间定义 为一个粗粒度值列表, 例如 。相反, 给定预训练模型定义的MLP扩展率 , 首次尝试通过一个简单但有效的Unified FFN(UFFN)层搜索每个FFN层的细粒度 扩展率 。给定输入特征X, FFN层的输出可以表示为:
这里用 和 来表示预定义的 FFN 层的 MLP 扩展率和 隐层维数。 和 映射到 , 后者将通道维数映射回 。GeLU激活被添加在2个可学习的全连接预测之间。
与式 (13)一样, 通过编码具有二进制门的FFN隐层维配置来寻找细粒度的MLP扩展率。通过在搜索过程中对每个隐藏维度应用二进位门, 定义UFFN层输出为:
这可以删除不重要的隐藏维度。
class UnifiedMlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None,
act_layer=nn.GELU, drop=0., theta=0., ffn_indicators=None):
super().__init__()
self.in_features = in_features
out_features = out_features or in_features
self.hidden_features = hidden_features = hidden_features or in_features
self.act = act_layer()
self.drop = nn.Dropout(drop)
if ffn_indicators is None:
self.fc1 = nn.Linear(in_features, hidden_features)
self.fc2 = nn.Linear(hidden_features, out_features)
# Threshold parameters
self.register_parameter('ffn_thresholds', nn.Parameter(torch.tensor([theta] * hidden_features)))
# The indicators
self.register_buffer('assigned_indicator_index', nn.Parameter(torch.zeros(hidden_features)))
self.fine_tuning = False
else:
self.fc1 = nn.Linear(in_features, ffn_indicators.nonzero().shape[0])
self.fc2 = nn.Linear(ffn_indicators.nonzero().shape[0], out_features)
self.fine_tuning = True
def forward(self, x):
if not self.fine_tuning:
return self.search_forward(x)
else:
return self.finetune_forward(x)
def search_forward(self, x):
ffn_probs = F.sigmoid(self.ffn_thresholds)
if self.training:
ffn_indicators = bernoulli_sample(ffn_probs)
else:
ffn_indicators = (ffn_probs > 0.5).float()
x = self.fc1(x)
x = self.act(x)
x = ffn_indicators.unsqueeze(0).unsqueeze(0) * x
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
# We derive the FFN indicators by expectation, and
# ffn_indicators are kept to calculate complexity loss
self.ffn_indicators = (ffn_probs > 0.5).float() - torch.sigmoid(
ffn_probs - 0.5).detach() + torch.sigmoid(ffn_probs - 0.5)
self.register_buffer('assigned_indicator_index', self.ffn_indicators)
return x, torch.sum(self.ffn_indicators)
def finetune_forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x, None
3.搜索目标
为了获得具有理想效率约束的架构, 利用辅助计算复杂度损失来优化网络。具体地 说, 定义了一个查找表, 其中包含候选操作和模块的计算复杂性。计算代价 定义为:
其中 为当前网络计算复杂度, 为目标复杂度。最后, 将总体搜索目标定 义为 为超参数, 用来平衡 和交叉熵损失 。
2、Fine-tuning
在微调过程中,使之前3.2.1节中的随机二进制门具有确定性,即:
通过应用Eq.(14), 得到 , 并在微调过程中在UMSA层中最多选择一个操作。输 出可以表示为:
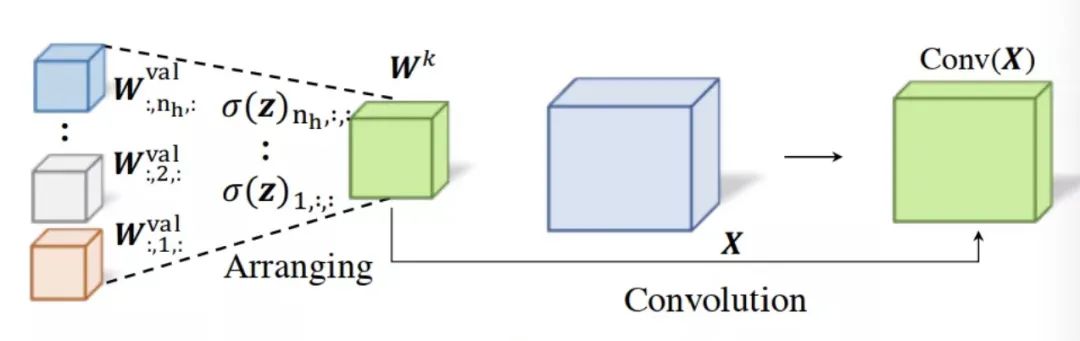
如果选择的操作是bottleneck convolution, 可以将训练良好的 配置为一个卷 积kernel, 以寻求高效的硬件实现, 如Eq.(10)所示, 如图2(b) 所示。结合Eq. (12), 可以将微调时的bottleneck convolution定义为:
类似地, 对于UFFN层, 可以自动找到隐藏维度T的子集, 该子集表示选定的隐藏维 度。因此, 为 , 微调时的UFFN层输出可由 。在微调期间, 将目标损失设置为 。
4 实验
4.1 主要结果
在表1和表2中,通过比较SPViT和Baseline方法来验证方法的有效性。
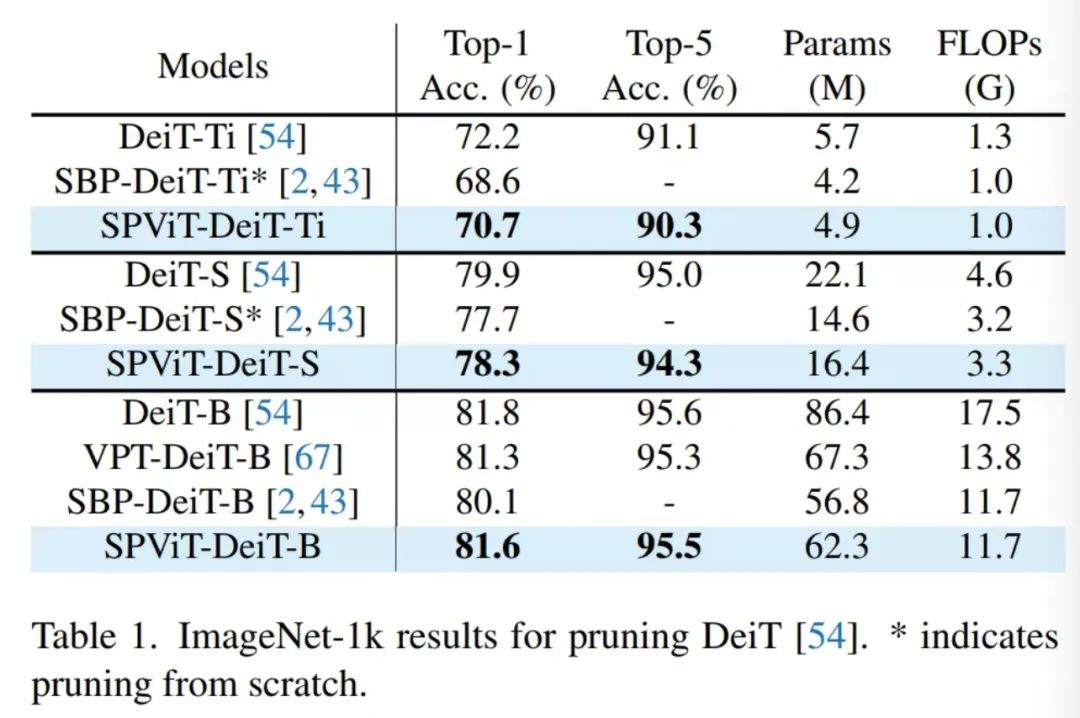
在表1中,可以观察到SPViT将密集的DeiT模型精简为紧凑的模型,节省20%以上的FLOPs,并具有竞争的Top-1和Top-5精度。例如,SPViT-DeiT-B实现了33.5%的FLOPs节省,而只有0.2%的Top-1精度性能下降。还注意到,SPViT在Top-1和Top-5精度方面始终优于Baseline剪枝方法。请注意,尽管SBP方法从零开始删除DeiT模型,而SPViT从预训练的权重中删除,但SBP的训练周期(600个周期)比SPViT(130个周期)长得多。
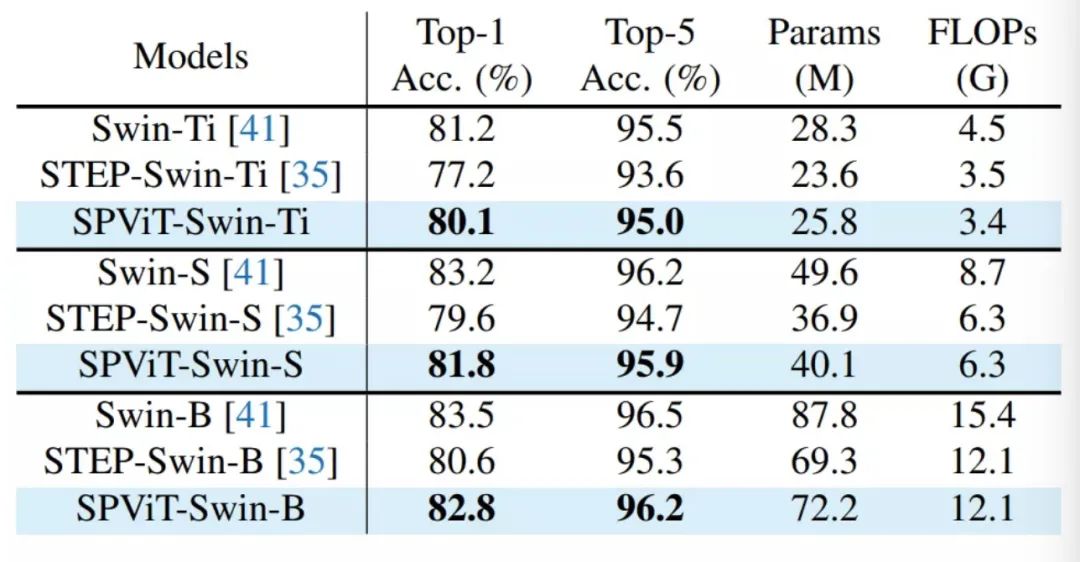
在对相对紧凑的层次ViT模型进行剪枝时,从表2中可以看出,SPViT在剪枝20%以上时也取得了显著的性能。例如,SPViT-Swin-B实现了3.3G次浮点数节省,但Top-1精度仅下降0.7%,比STEP-Swin-B高出2.2%。
4.2 观察架构搜索
在搜索过程中,SPViT可以在期望的效率约束下自动找到性能良好的架构。在这里,展示了在逐步减少目标FLOPs时,在标准vit和分层vit上使用SPViT搜索架构的经验观察。
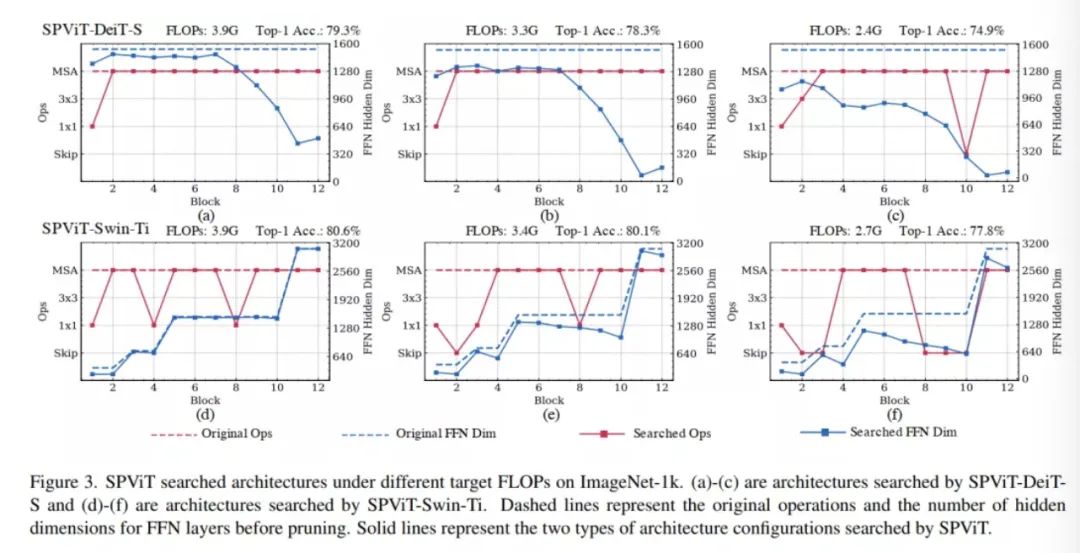
在图3中,可视化了SPViTDeiT-S在3.9G、3.2G和2.4G FLOPs下的搜索架构,Top-1准确率分别为79.3%、78.3%和74.9%;SPViT-SwinTi在3.9G、3.4G和2.7G FLOPs下,Top-1准确率分别为80.6%、80.1%和77.8%。
Locality is encouraged in shallow blocks.
如图3(a)-(f)所示,SPViT-DeiT-S和SPViT-Swin-Ti学习将浅层MSA层修剪成Bottleneck卷积层或skip-connections(在SPViT-DeiT-S的前两个块和SPViT-SwinTi的前三个块中)。
这一观测结果表明浅层MSA层包含更多多余的全局相关性。还可以看到,最后两个块仍然是所有模型的MSA层,这表明了深层全局操作的重要性。更多关于预训练的MSA层的注意力图模式的分析可以在补充材料中找到。
Last few FFN layers have more redundancy in standard ViTs.
对于预训练的DeiT模型,MLP膨胀率在所有块上设置为相同的。如图3(a)-(c)所示,对于SPViT-DeiT-S设置,网络优先删除最后几个块中的隐藏维度。由于在FFN层中隐藏维度的数量越高,意味着容量越大,反之亦然,作者推测,由于在标准vit中处理的注意力map的多样性较少,最后几个FFN层需要的容量比其他层更少。
Shallower FFN layers within each stage require higher capacity in hierarchical ViTs.
不同于标准ViT, Swin模型采用分层架构,将块划分为几个阶段。在每个阶段的开始,输入token被合并到更高的嵌入维度中。如图3(d)-(f)所示,在同一阶段,较浅的层保留了更多的隐藏维度。作者推测,对token合并引起的特性空间上的变化进行建模,需要为分层ViT提供更高的容量。
4.3 消融实验
1、Single-path vs. multi-path search
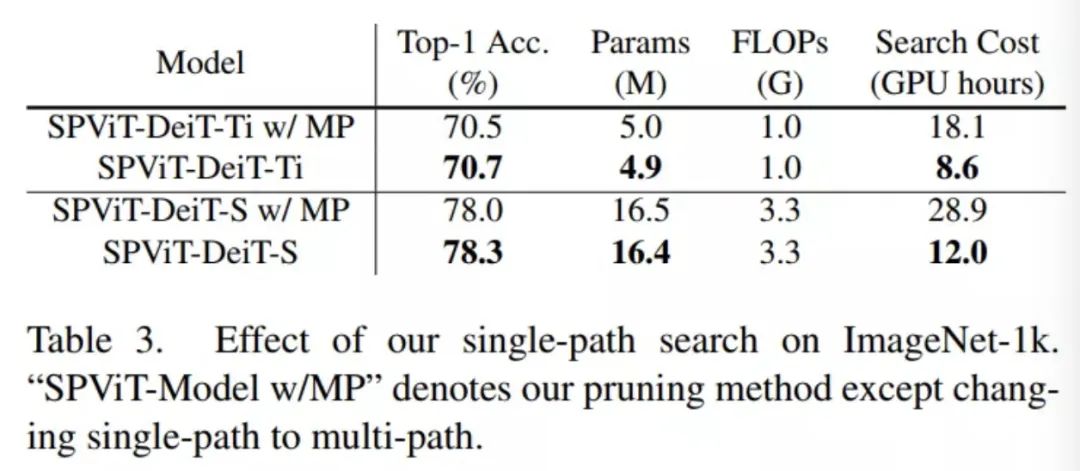
在表3中,通过比较SPViT和多路径搜索来研究单路径搜索的有效性。具体来说,在多路径实现中,在搜索前随机初始化候选BConv卷积操作的权值,并保持其他组件与单路径版本相同。可以观察到,在计算复杂度相同的情况下,与多路径搜索相比,单路径公式具有更高的性能、更少的参数和更低的搜索成本。例如,SPViT-DeiT-S比多路径对等物的Top-1准确率高出0.3%,并降低了超过50%的搜索成本。
2、Effect of the search strategy 图片

为了验证搜索策略的有效性,在表4中将本文方法与CIFAR-100上随机搜索的架构进行了比较。具体来说,在搜索空间中随机抽样10个具有计算复杂度的架构,然后对这些架构进行微调。将SPViT与实现最高Top-1精度的架构进行了比较。观察到,在类似的flop和参数下,SPViT在Top-1和Top-5准确率方面比随机搜索对手高出约1.3%和0.6%。显著的性能增益证明了搜索策略的有效性。
3、Pruning proportions for MSA and FFN layers
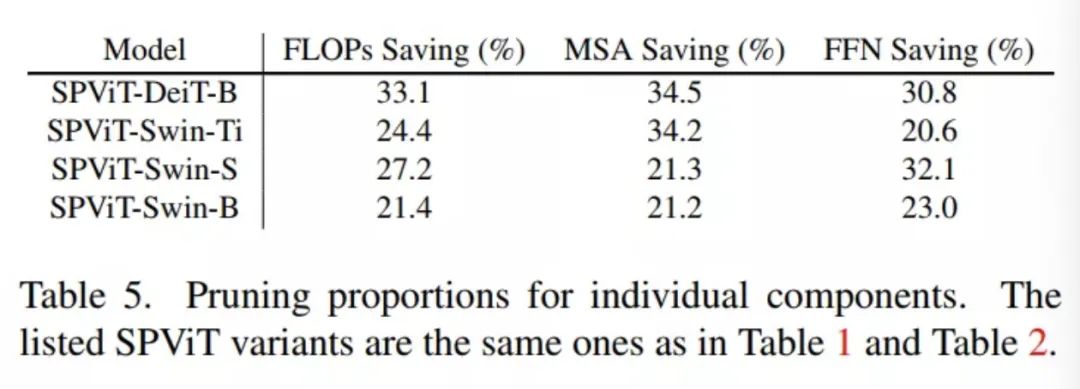
在表5中调查了MSA和FFN层的剪枝比例。可以看到,不同模型的剪枝比例不同,SPViT-DeiT-B对MSA层的剪枝比例较高,而SPViT-Swin-B对FFN层的剪枝比例较高。结果表明,在给定目标效率约束的情况下,SPViT可以灵活地为不同密集模型定制合适的剪枝比例。
参考
[1].Pruning Self-attentions into Convolutional Layers in Single Path


# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~




