
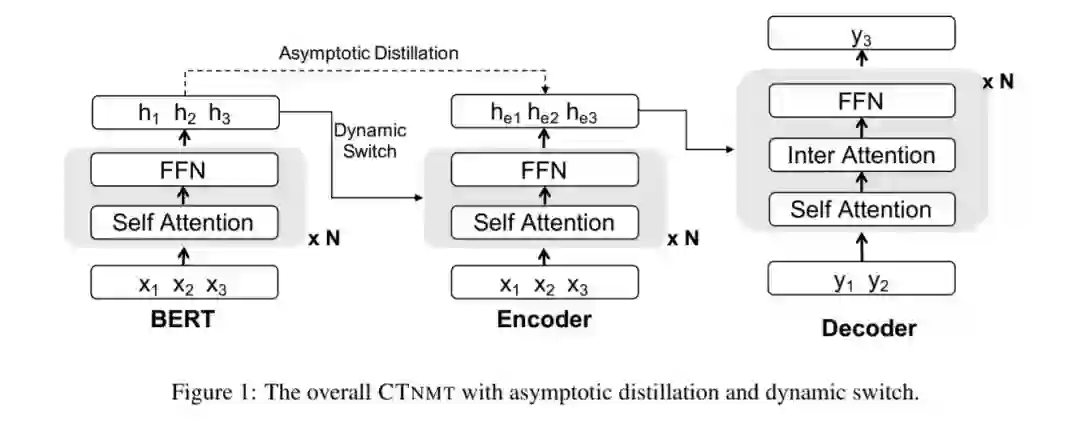
GPT-2和BERT证明了在各种自然语言处理任务中使用预训练语言模型(LMs)的有效性。然而,LM调优在应用于资源丰富的任务时常常会出现灾难性的遗忘。在这项工作中,我们介绍了一个协调的训练框架(\方法),这是把预训练的LMs集成到神经机器翻译(NMT)的关键。我们提出的Cnmt包括三种技术: a)渐近精馏,以确保NMT模型能够保留预先训练好的知识; b)动态切换门,避免对预先训练知识的灾难性遗忘 ;c)根据预定策略调整学习进度的策略。我们在机器翻译方面的实验表明,WMT14的英德语言对中,“方法”最多可获得3个BLEU分数,甚至超过了之前最先进的训练前辅助NMT的1.4个BLEU分数。而对于包含4000万对句子的大型WMT14英法任务,我们的基本模型仍然比最先进的Transformer大模型提高了1个以上的BLEU分数。
成为VIP会员查看完整内容
相关内容

专知会员服务
36+阅读 · 2020年4月14日
专知会员服务
32+阅读 · 2020年2月21日
Arxiv
7+阅读 · 2019年9月17日
Arxiv
4+阅读 · 2018年1月11日

相关VIP内容
专知会员服务
36+阅读 · 2020年4月14日
专知会员服务
32+阅读 · 2020年2月21日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年9月17日
Arxiv
4+阅读 · 2018年1月11日