资源 | FAIR & NYU开发XNLI语料库:15种语言(含低资源语言)
选自research.fb
作者:Alexis Conneau等
机器之心编译
参与:路、王淑婷
近日,FAIR 和纽约大学的研究者合作开发了一个新的自然语言推断语料库 XNLI,该语料库将 MultiNLI 的测试集和开发集扩展到 15 种语言,包括斯瓦西里语和乌尔都语等低资源语言。XNLI 是跨语言句子理解的基准,实际可用且具备一定难度,有助于带来更好的跨语言理解方法。
项目地址:https://github.com/facebookresearch/XNLI
很多 NLP 系统(如情感分析、主题分类、feed 排序)依赖在高资源语言中训练数据,却无法直接在测试时为其他语言进行预测。该问题在几乎所有涉及跨语言数据的行业应用中都会出现。
我们可以使用机器翻译将任意样本翻译成高资源语言,来缓解该问题。但是,在每个语言方向都构建一个机器翻译系统太昂贵,不是跨语言分类的最佳解决方案。跨语言编码器更便宜,也更优雅(见下图示例)。
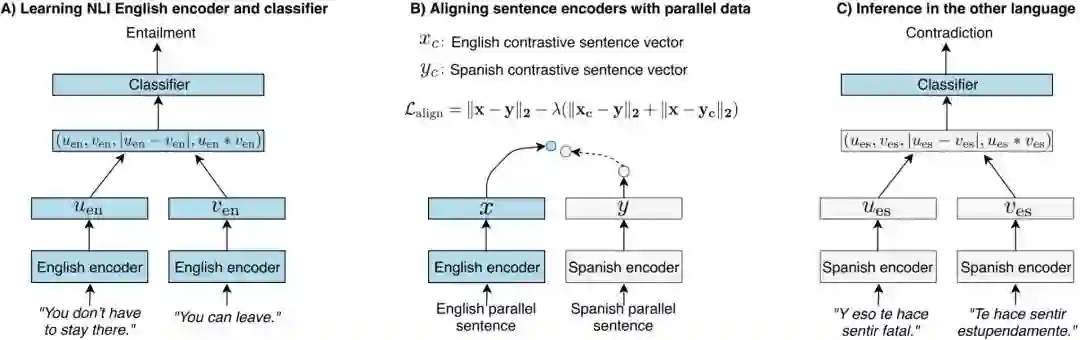
为了评估此类跨语言句子理解方法,来自 Facebook 和纽约大学的研究者创建了 XNLI,它是 SNLI/MultiNLI 语料库的扩展版,涉及 15 种语言。XNLI 提出了以下研究问题:在仅具备英语训练数据的情况下,我们如何在测试时对任意语言进行预测?
行业应用的常规任务可能不包括自然语言推断(natural language inference,NLI),但研究者认为 NLI 是评估跨语言句子表征的良好测试平台,XNLI 的更好方法能够带来更好的跨语言理解(crosslingual language understanding,XLU)方法。
XNLI 语料库
跨语言自然语言推断(XNLI)语料库是一个众包语料库,基于 MultiNLI 语料库收集了 5000 个测试对和 2500 个开发对。研究者使用文本蕴含标注这些句对,然后将这些句子翻译成 14 种语言:法语、西班牙语、德语、希腊语、保加利亚语、俄语、土耳其语、阿拉伯语、越南语、泰语、中文、印度语、斯瓦西里语和乌尔都语,这就有 11.25 万标注对了。每个 premise 可与 15 种语言中的对应假设相关,一共有超过 150 万组合。

该研究介绍了一个基准,即 XNLI 语料库,它将这些 NLI 语料库扩展到 15 种语言。XNLI 包括 7500 个人工标注开发和测试样本,格式为 NLI 三向分类,一共生成了 112500 个标注句对。这些语言涉及多个语系,包括斯瓦西里语和乌尔都语这两种低资源语言。
XNLI 语料库聚焦于开发数据和测试数据,因此构建它的目的是评估跨语言句子理解,其中模型必须在一种语言中训练,在其他不同的语言中测试。
研究者评估了多种自然语言推断的跨语言学习方法,训练数据是来自于公开语料库的平行数据。研究展示了平行数据有助于在多语言中对齐句子编码器,以使使用 English NLI 数据训练的分类器能够正确地分类其他语言的句对。尽管该对齐方法不敌该研究使用的机器翻译基线模型,但该对齐方案的性能也很有竞争力。
下载
XNLI 是一个 ZIP 文件,包含 JSON lines (jsonl) 和制表符分割文本 (txt) 两种格式的语料库。
英语训练数据地址:https://www.nyu.edu/projects/bowman/multinli/
XNLI 语料库下载地址:https://s3.amazonaws.com/xnli/XNLI-1.0.zip(17MB,ZIP)
XNLI 还可用作一万个句子的 15way 平行语料库,来构建或评估机器翻译系统。XNLI 为低资源语言(如斯瓦西里语和乌尔都语)提供额外的开放平行数据。
XNLI-15way 下载地址:https://s3.amazonaws.com/xnli/XNLI-15way.zip(12MB,ZIP)
论文:XNLI: Evaluating Cross-lingual Sentence Representations

论文地址:https://research.fb.com/wp-content/uploads/2018/10/XNLI-Evaluating-Cross-lingual-Sentence-Representations.pdf
摘要:当前最优的自然语言处理系统依赖标注数据来学习强大的模型。这些模型往往是在单语数据(通常是英语)上训练的,无法直接用于其他语言。由于收集每种语言的数据不切实际,因此研究者对跨语言理解(XLU)和低资源跨语言迁移的兴趣越来越大。本研究将 MultiNLI 的开发集和测试集扩展到 15 种语言(包括斯瓦西里语和乌尔都语等低资源语言),从而构建了一个 XLU 的评估集。我们希望该数据集,即 XNLI 能够提供信息量大的标准评估任务来促进跨语言句子理解的研究。此外,我们还提供了多个多语言句子理解的基线模型,其中两个基于机器翻译系统,还有两个使用平行数据来训练对齐多语言词袋模型和 LSTM 编码器。我们发现 XNLI 是一个实际且有难度的评估套件,在直接翻译测试数据任务上获得了可用基线模型中的最优表现。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


