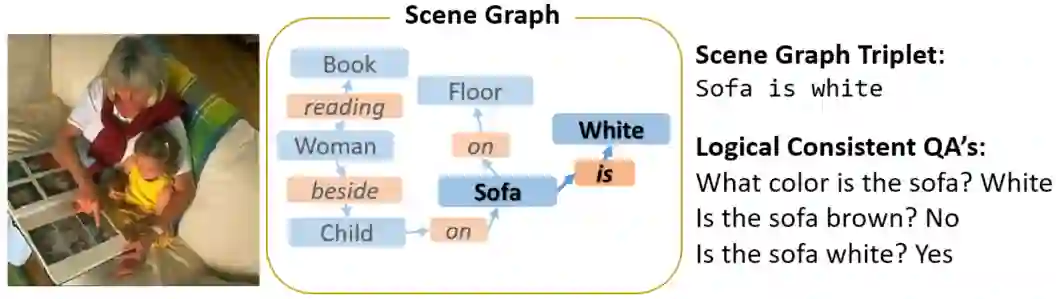
While models for Visual Question Answering (VQA) have steadily improved over the years, interacting with one quickly reveals that these models lack consistency. For instance, if a model answers "red" to "What color is the balloon?", it might answer "no" if asked, "Is the balloon red?". These responses violate simple notions of entailment and raise questions about how effectively VQA models ground language. In this work, we introduce a dataset, ConVQA, and metrics that enable quantitative evaluation of consistency in VQA. For a given observable fact in an image (e.g. the balloon's color), we generate a set of logically consistent question-answer (QA) pairs (e.g. Is the balloon red?) and also collect a human-annotated set of common-sense based consistent QA pairs (e.g. Is the balloon the same color as tomato sauce?). Further, we propose a consistency-improving data augmentation module, a Consistency Teacher Module (CTM). CTM automatically generates entailed (or similar-intent) questions for a source QA pair and fine-tunes the VQA model if the VQA's answer to the entailed question is consistent with the source QA pair. We demonstrate that our CTM-based training improves the consistency of VQA models on the ConVQA datasets and is a strong baseline for further research.
翻译:虽然视觉问答模型(VQA)多年来不断改善,但与一个快速互动的模型显示这些模型缺乏一致性。例如,如果一个模型回答“红”到“气球是什么颜色”?如果问“气球是红色吗?”,它可能会回答“否” 。这些答复违反了简单的要求概念,并提出了关于VQA模型地面语言如何有效的问题。在这项工作中,我们引入了一个数据集、ConVQA和能够对VQA一致性进行定量评估的衡量标准。对于一个图像(例如气球的颜色)中特定可见的事实,我们产生一套逻辑上一致的问答对(QA)配对(例如气球是红色吗?),它也可能回答“否” 。这些答复违反了简单的要求概念概念,并提出了关于VQA模型的一致性模型,如果我们CA对数据库的精确性要求我们的数据和CA的精确性答案是源。