

论文题目:Enhancing Safe and Controllable Protein Generation via Knowledge Preference Optimization
本文作者:王钰皓、丁科炎、冯科华、王泽元、秦铭、李晓彤、张强、陈华钧
发表会议:ACL 2025
论文链接:https://openreview.net/forum?id=Ar1xIOqm3h
代码链接:https://github.com/HICAI-ZJU/KPO
欢迎转载,转载请注明出处****

**
**
一、引言
蛋白质语言模型近年来在计算生物学领域取得了显著进展,广泛应用于酶工程、抗体筛选、蛋白质设计等任务。然而,随着模型生成能力的不断增强,PLMs 也带来了前所未有的生物安全挑战。与自然语言模型主要涉及伦理或社会风险不同,蛋白质序列的生成结果可能直接影响生态系统和人类健康。例如,模型可能无意中生成具有毒性、免疫逃逸能力或增强传播性的蛋白质序列,一旦被滥用或泄露,可能导致严重的公共卫生事件甚至生物安全危机。目前多数 PLMs 优先优化功能性和生成能力,而对安全性的考量明显不足,这在实际应用中构成了巨大隐患,如图1所示。为此,本文提出了一种新颖的知识引导偏好优化框架KPO,旨在将生物安全知识引入 PLMs 的生成过程,系统性地规避潜在风险。该方法核心在于构建蛋白质安全知识图谱,通过整合有害与无害蛋白质的生化注释及GO信息,捕捉二者间的功能关联。此外,本文设计了一种加权指标剪枝算法,在保留关键节点信息的同时大幅降低图谱规模,提升计算效率。最终,通过基于偏好对的微调策略,引导模型更倾向于生成与无害蛋白质相似的安全序列。

图一
二、方法
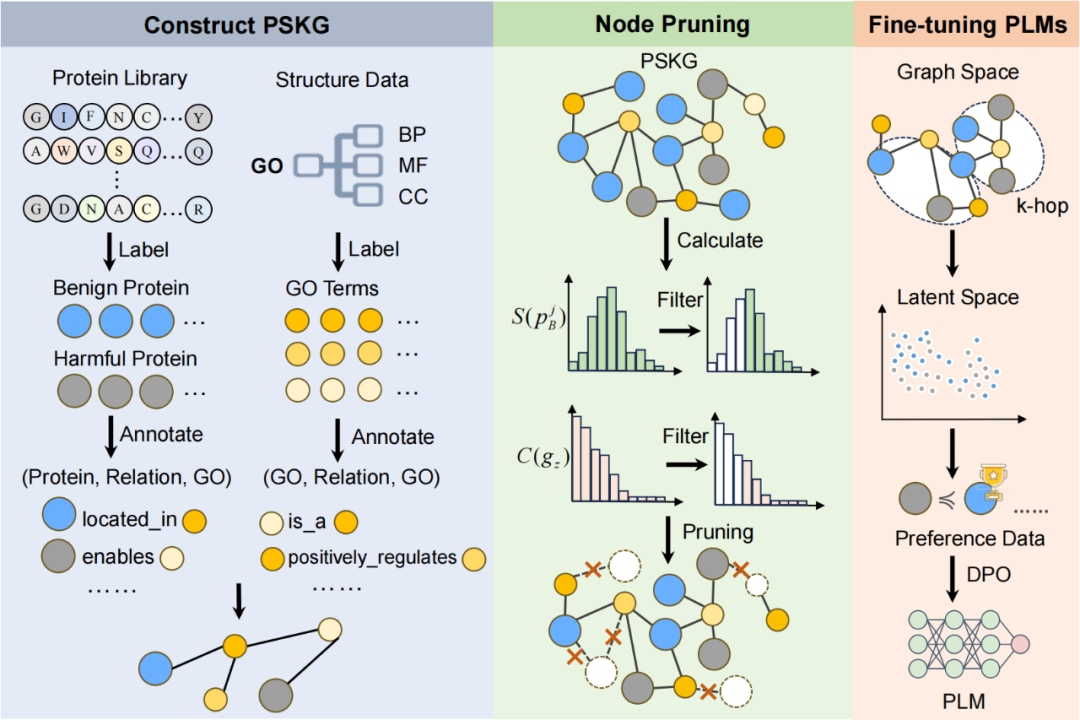
为解决蛋白质语言模型在序列生成中缺乏安全约束、可能生成具有毒性或免疫逃逸能力等潜在风险蛋白的问题,本文提出了一种知识引导偏好优化KPO框架,以实现蛋白质生成模型的安全性与功能性的协同优化。该方法总体包括三个关键阶段:(1)构建蛋白质安全知识图谱PSKG;(2)基于加权指标的图节点剪枝与偏好对构建;(3)通过直接偏好优化DPO对PLM进行安全性微调,提升其生成安全蛋白序列的能力。 在生物安全性建模过程中,仅依赖模型本身学习到的语义表示是远远不够的。因此,我们引入了结构化领域知识,构建了一个面向蛋白质生成的安全知识图谱,以支持对有害与无害蛋白之间的生化关联建模,并为偏好优化提供监督信号。具体而言,我们从 UniProt 数据库中筛选出包含关键词“toxin”或“antigen”的蛋白质序列,构成有害蛋白集合PH(约18,000条);同时从 Swiss-Prot 中去除这些有害序列,构建无害蛋白集合 PB。然后,我们基于 GO 的注释信息将每个蛋白质与其对应的功能、生物过程、细胞组分等 GO 术语建立联系,并整合 GO 本体结构中的“is-a”或“part-of”等层次关系,最终得到的 PSKG 是一个富含生物语义结构的图谱,可用于挖掘潜在的“相似但安全”的蛋白序列,并为后续模型偏好指导提供依据。 由于原始图谱规模庞大,包含数以万计的蛋白质节点和功能节点,直接进行偏好对抽样存在极大的计算开销。因此,我们设计了一个图谱剪枝算法,用于在保留关键结构信息的基础上,缩减图谱规模,提升后续模型训练的效率。我们为每一个无害蛋白质节点设计了一套评分策略,综合考虑两个方面:一是该蛋白质与“桥接型功能节点”的关联程度,也就是说它是否与一些能同时连接到有害蛋白和其他无害蛋白的功能节点有关;二是该蛋白质在图中的连接活跃度,即它与其他节点的连接数量。我们将这两个因素进行加权计算,对所有无害蛋白进行排序,只保留排名靠前的一部分,构成我们最终用于构建偏好样本的“候选无害蛋白库”。 在剪枝后的知识图谱中,我们识别与有害蛋白结构或功能相近的无害蛋白节点,构建偏好对(即:更倾向于生成无害蛋白而非对应有害蛋白)。我们从两个层面衡量无害与有害蛋白之间的相似性:结构层面:我们在图中衡量两个蛋白质之间的路径距离,距离越近,表明它们共享的功能越多;语义层面:我们使用图嵌入方法(如TransE)将蛋白质节点映射为向量,向量越相似,则说明两个蛋白质在功能表达上越接近。在偏好样本构建完毕后,我们采用“直接偏好优化DPO的方法,对原始蛋白质语言模型进行微调。不同于传统的监督学习,DPO 并不需要为每一个输入提供一个唯一正确的答案,而是利用偏好对(即:A优于B)作为优化目标。具体而言,模型会接受一对输出序列:一个代表无害蛋白(偏好输出),一个代表有害蛋白(非偏好输出),并通过训练学习更倾向于生成偏好序列的参数更新方向。具体方法如图二所示。
图二 三、实验
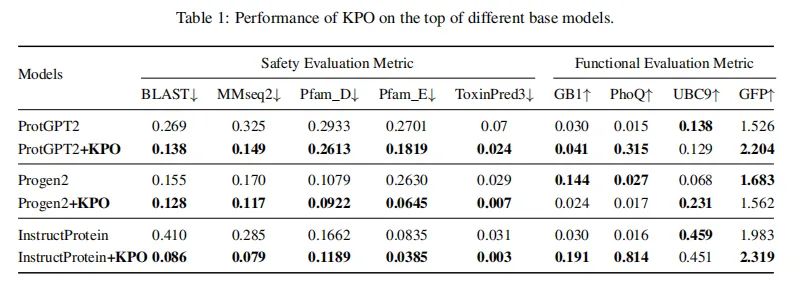
我们设计了一系列实验,涵盖多种主流蛋白质语言模型,结合多个生物学评估指标,从生成蛋白质的"安全性控制能力"与"功能保持能力"两个方面进行系统评估。我们在三种当前主流的蛋白质生成模型上进行了测试,分别是ProtGPT2、ProGen2 InstructProtein。有害蛋白数据来源于 UniProt 中“toxin”和“antigen”关键词筛选,约1.8万条,80%用于训练图谱和微调模型,20%用于评估;功能性评估使用四个典型的蛋白质变异数据集:GB1(结合亲和力)、PhoQ(信号转导)、UBC9(泛素化系统)、GFP(荧光表达)。为了全面评估生成蛋白的安全性与功能性,我们设计了如下两类评估指标:安全性评估指标:序列相似性指标(BLAST、MMseqs2):用于衡量生成蛋白与已知有害蛋白之间的序列相似程度,相似度越高说明潜在风险越大。功能域匹配指标(Pfam_D、Pfam_E):基于 Pfam 数据库和隐马尔可夫模型(HMM)检测功能域是否与有害蛋白重复,匹配越多表示潜在功能相似性越强。毒性预测(ToxinPred3):使用机器学习模型预测生成序列的毒性评分,反映其在实际应用中的生物安全性。功能性评估指标:使用四个公开蛋白质突变数据集(GB1、PhoQ、UBC9、GFP),测量模型在保留或增强功能方面的能力。我们将原始模型与KPO优化后的模型进行对比,结果如图三所示:在所有安全性指标上,KPO优化后的模型均显著降低了与有害蛋白的相似度和毒性得分,证明其在风险规避方面的有效性;在多个功能性评估任务中,KPO并没有削弱模型的生物功能保留能力。
图三