赛尔原创 | AAAI 2019 Gaussian Transformer: 一种自然语言推理的轻量方法
论文名称:Gaussian Transformer: A Lightweight Approach for Natural Language Inference
论文作者:郭茂盛,张宇,刘挺
原创作者:哈工大 SCIR 博士生 郭茂盛
摘要
自然语言推理 (Natural Language Inference, NLI) 是一个活跃的研究领域,许多基于循环神经网络(RNNs),卷积神经网络(CNNs),self-attention 网络 (SANs) 的模型为此提出。尽管这些模型取得了不错的表现,但是基于 RNNs 的模型难以并行训练,基于 CNNs 的模型需要耗费大量的参数,基于 self-attention 的模型弱于捕获文本中的局部依赖。为了克服这个问题,我们向 self-attention 机制中引入高斯先验 (Gaussian prior) 来更好的建模句子的局部结构。接着,我们为 NLI 任务提出了一个高效的、不依赖循环或卷积的网络结构,名为 Gaussian Transformer。它由用于建模局部和全局依赖的编码模块,用于收集多步推理的高阶交互模块,以及一个参数轻量的对比模块组成。实验结果表明,我们的模型在SNLI 和 MultiNLI 数据集上取得了当时最高的成绩,同时大大减少了参数数量和训练时间。此外,在 HardNLI 数据集上的实验表明我们的方法较少受到标注的人工痕迹(Annotation artifacts) 影响。
1 引言
1.1 任务简介
自然语言推理 (Natural Language Inference, NLI) ,又叫文本蕴含识别 (Recognizing Textual Entailment, RTE), 研究的是文本间的语义推理关系, 具体来讲, 就是识别两句话之间的蕴含关系,例如,蕴含、矛盾、中性。形式上是,NLI 是一个本文对分类问题。
1.2 动机
这里简要介绍一下我们提出 Gaussian Self-attention 的动机。我们观察到,在句子中,与当前词的语义关联比较大的词往往出现在这个单词的周围, 但是普通的 Self-attention, 并没有有效地体现这一点。如图1所示,在句子 ”I bought a new book yesterday with a new friend in New York. ” 中,共出现了三个 ”new”,但对于当前词 book 来说,只有第一个new 才是有意义的。但是普通的 self-attention(在不使用 position-encoding 的情况下),却给这三个 ”new” 分配了同样大小的权重,如图1(a)所示。我们的想法是,应当鼓励 self-attention 给邻近的词更大的权重,为此,我们 在原始的权重上乘以一个按临近位置分布的高斯先验概率,如图 1(b),改变 self-attention 的权重分布,如图 1(c),从而更加有效地建模句子的局部结构。
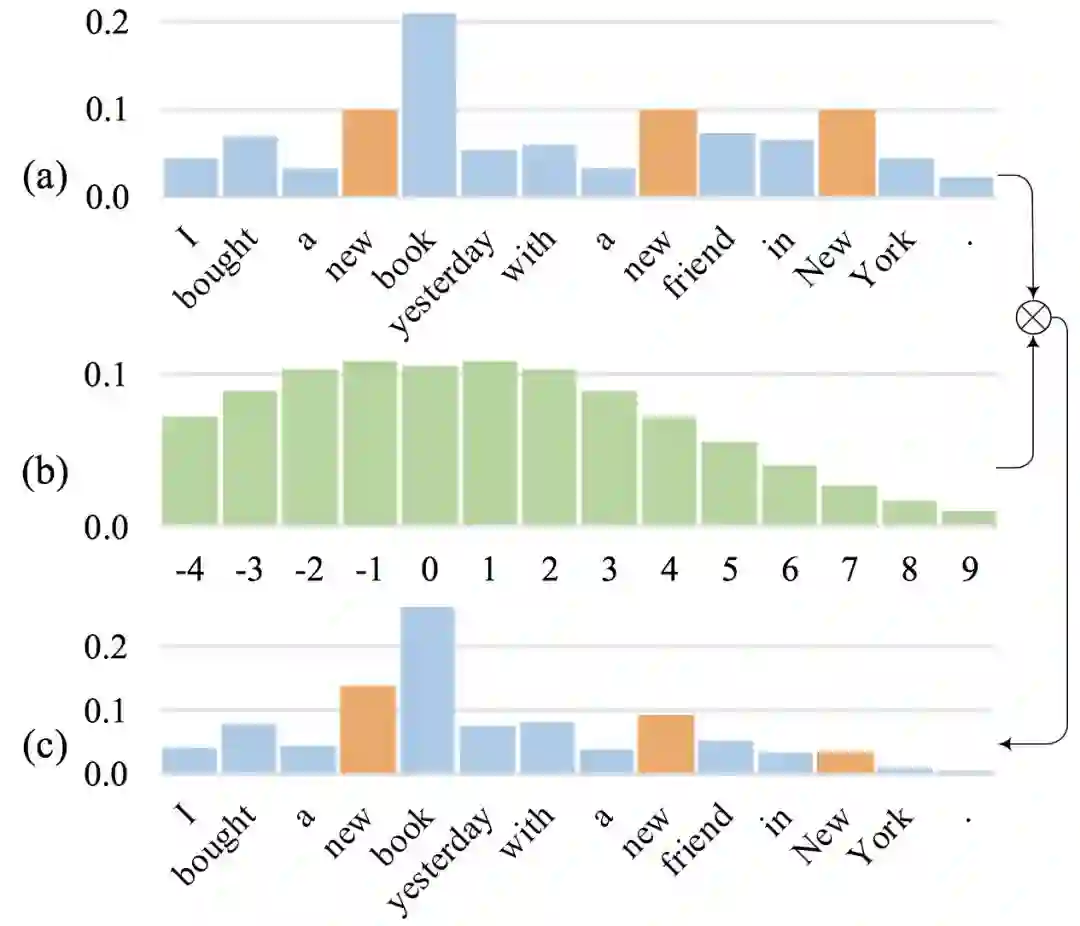
图 1. Gaussian self-attention 示例
事实上,RNNs 和 CNNs 能够自然而然地赋予临近的单词更大的权重,例如,RNNs 会倾向忘记远处的单词,CNNs 会忽略所有不在当前窗口内的单词。在这篇文章中,我们把 Gaussian self-attention 应用到了 Transformer 网络上, 并在自然语言推理 (Natural language Inference)这一任务上进行了验证,实验表明我们所提出的基于 Gaussian self-attention 的 Gaussian Transformer 效果优于许多较强的基线方法。同时,该方法也保留了原始 Transformer 的并行训练,参数较少的优点。
2 模型简介
在实现上, 我们可以通过一系列化简 (具体细节请参看我们的论文原文), 把 Gaussian self-attention 转化为 Transformer 中的一次矩阵加法操作, 如图 2 所示, 从而节省了运算量。 此外,我们发现,与使用原始的 Gaussian 分布作为先验概率相比,适当的抑制到单词自身的 attention可以对最终的实验结果有少许的提升,如图 3(b) 所示。
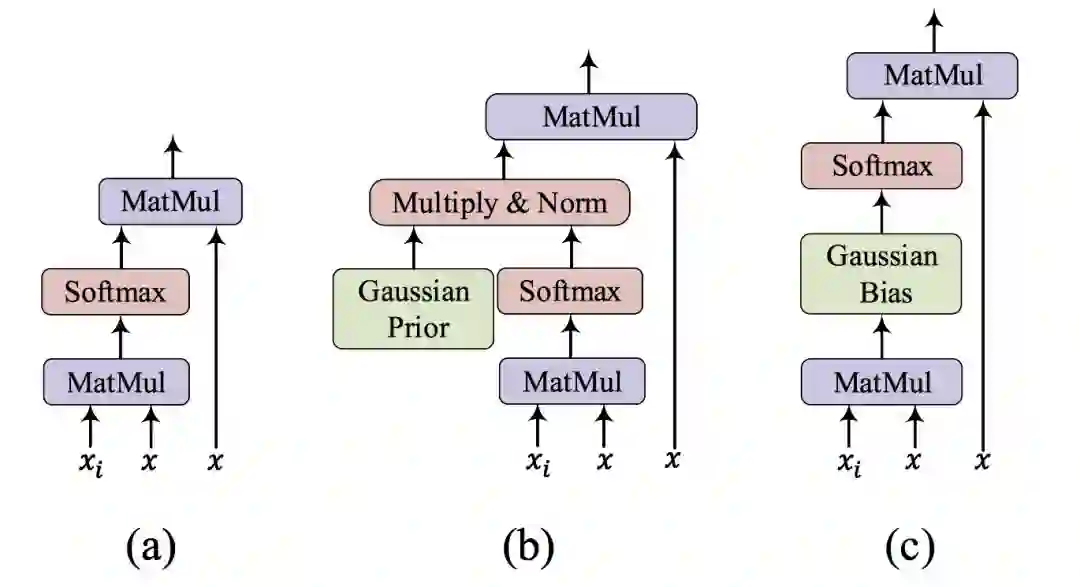
图 2. Attention 示例: (a) 原始的 dot-product attention;(b)&(c) Gaussian self-attention 的两种实现
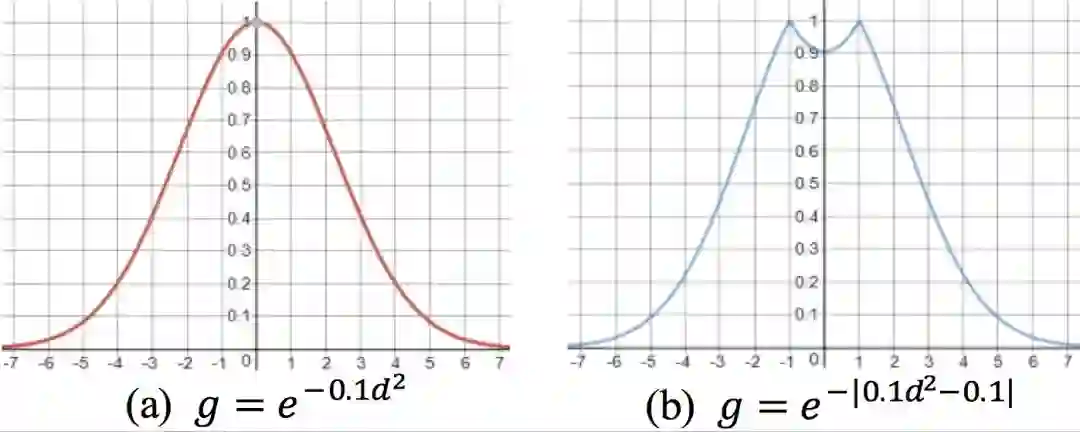
图 3. 先验概率示例: (a) 原始的 Gaussian prior;(b) 抑制到自身的 Gaussian prior 变种
图 4 展示了我们模型的整体框架。 如图所示, 模型自底向上大致分为四个部分:Embedding模块、编码 (Encoding) 模块、交互 (Interaction) 模块和对比 (Comparison) 模块。
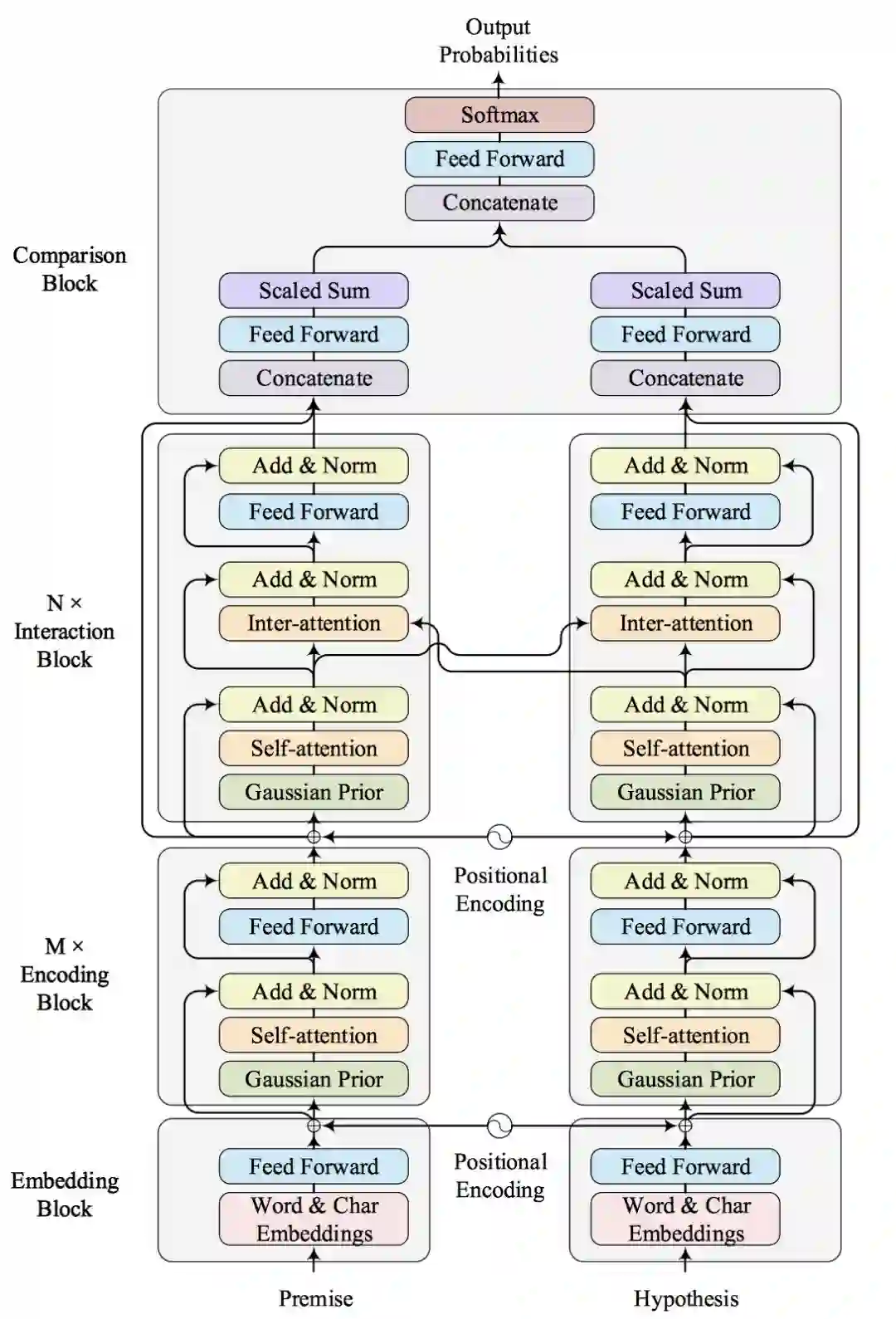
图 4. Gaussian Transformer 整体框架
Embedding 模块的作用是把自然语言文本转化为机器方便处理的向量化表示, 我们使用了单词和字符级别的 Embedding,以及 Positional Encoding。
Encoding 模块与原始的 Transformer 的 Encoder 非常类似,只是我们增加了前文引入的 Gaussian self-attention 以便更好的建模句子的局部结构。 但事实上, 句子中也存在长距离依赖, 仅仅建模句子的局部结构是不够的。为了捕获句子的全局信息,我们堆叠了 M 个 Encoding 模块。这种方式类似于多层的 CNNs 网络,层数较高的卷积层的 receptive field 要大于底层的卷积。
Interaction 模块用于捕获两个句子的交互信息。 这一部分与原始的 Transformer 的 Decoder 部分类似, 区别是我们去掉了 Positional Mask 和解码的部分。 通过堆叠 N 个 Interaction 模块,我们可以捕获高阶交互的信息。
Comparison 模块主要负责对比两个句子,分别从句子的 Encoding 和 Interaction 两个角度对比,这里我们没有使用以前模型中的复杂结构,从而节省了大量的参数。
3 实验与分析
3.1 实验结果
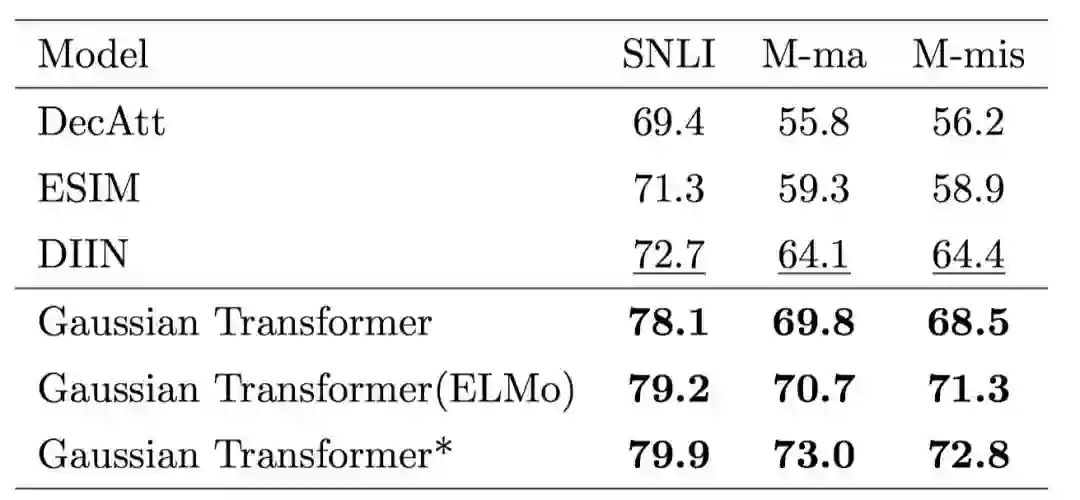
首先,我们验证各个模块的有效性,如图 5 所示,采用多层的 Encoding 模块和多层的 Interaction 模块的效果要优于使用单层的模型,证明了前面所提到的全局信息和高阶交互的有效性。其次,我们想要验证一下 Gaussian prior 的有效性。如表 1 所示,我们发现 Gaussian prior 及其变种的性能要优于其他诸如 Zipf prior 等方法,也要优于原始的 Transformer。最后, 我们在 SNLI、MultiNLI 和 HardNLI 的测试集上与其他前人的方法进行了横向比较。如表 2、 3、4、5 和 6 所示,我们的方法在 Accuracy、模型参数量、训练与预测一轮同样的数据的时间上都优于基线方法。
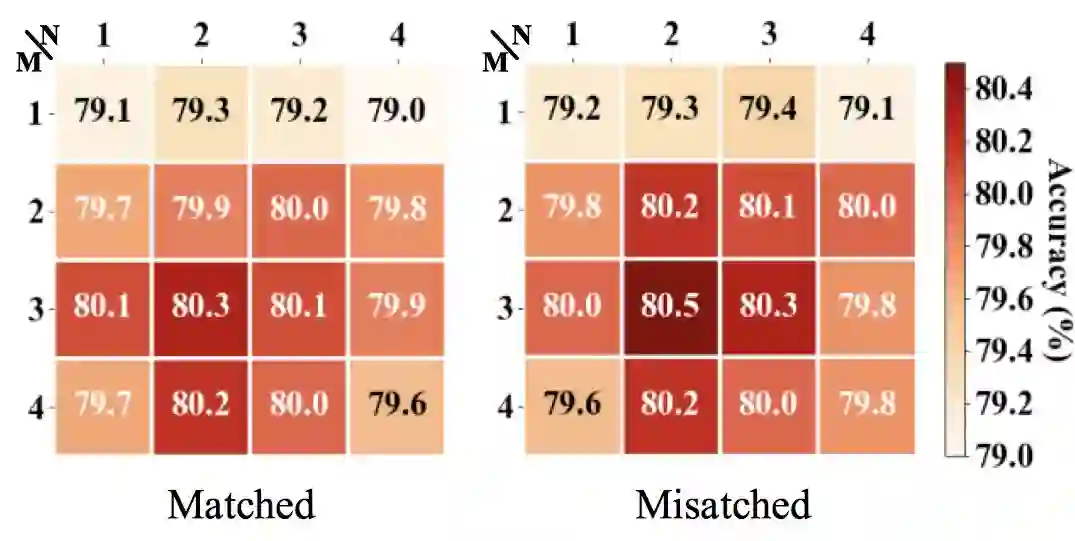
图 5. MultiNLI 开发集上的 Accuracy 热图。
表1. MultiNLI 开发集上各 Gaussian transformer 变种的 Accuracy
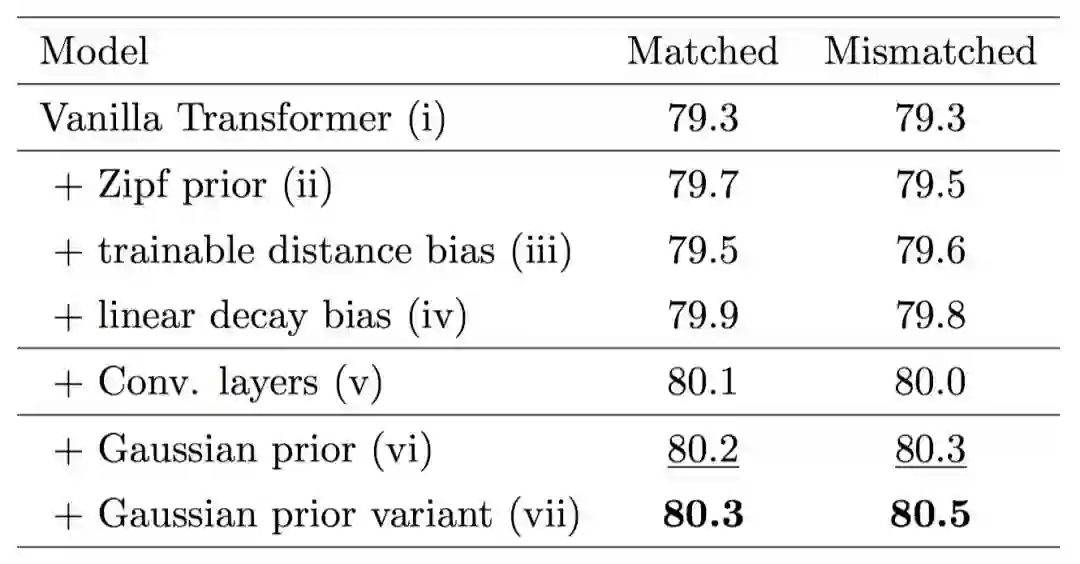
表2. SNLI 测试集上 Gaussian Transformer 与其他模型的横向比较
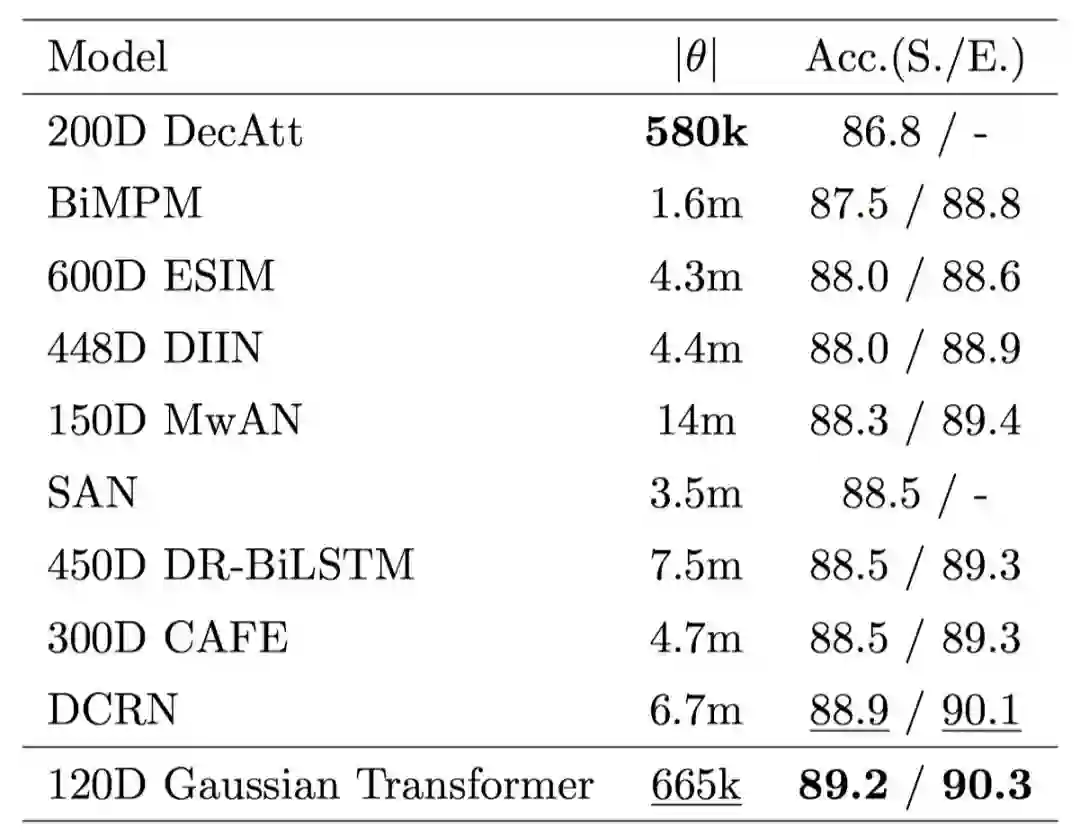
表3. MultiNLI 测试集上 Gaussian Transformer 与其他模型的横向比较
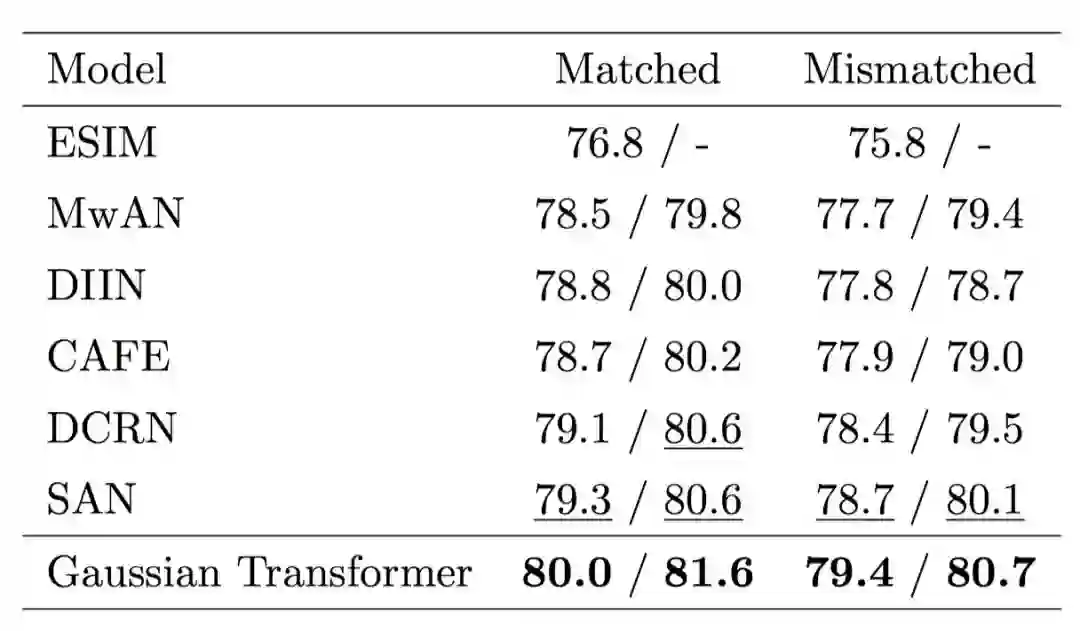
表4. 在 SNLI 数据集上训练或预测一轮所需的时间对比

表5. 当引入外部资源时,各个模型的性能比较
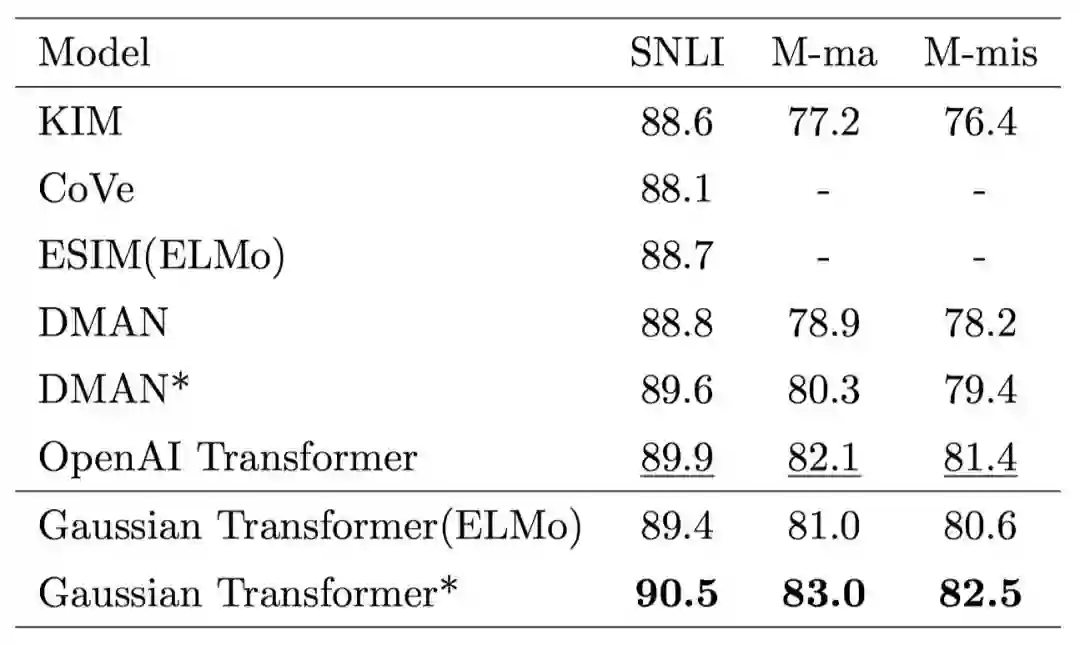
表6. HardNLI 上的对比结果
3.2 分析
Q: 原始的 Transformer 中已经有了 Positional encoding,已经能够捕获单词的位置信息,为什么还要用 Gaussian Prior ?
A: Positional Encoding 仅仅使模型具有了感知单词位置的能力;而 Gaussian Prior 告诉模型哪些单词更重要,即对于当前单词来说,临近的单词比遥远的单词更重要,这一先验来自于人的观察。
Q: 为什么 Gaussian Transformer 在时间和参数量上优于其他的方法?
A: Gaussian Transformer 没有循环和卷积结构,从而能够并行计算,同时我们在设计模型时,尽量保持模型简化,摒弃了以往方法中的复杂结构 (例如,在 Comparison block 中的简化),使我们的模型更加轻量。
4 结论
针对自然语言推理任务的前人工作的不足,我们提出了基于 Gaussian self-attention 的 Gaussian Transformer 模型。实验表明所提出的模型在若干自然语言推理任务上取得了State-of-the-Art的实验结果。
参考文献及其他未尽细节,请点击【阅读原文】参阅我们的论文原文。
本期责任编辑:张伟男
本期编辑:吴 洋
“哈工大SCIR”公众号
主编:车万翔
副主编: 张伟男,丁效
责任编辑: 张伟男,丁效,刘一佳,崔一鸣
编辑: 李家琦,吴洋,刘元兴,蔡碧波,孙卓,赖勇魁
长按下图并点击 “识别图中二维码”,即可关注哈尔滨工业大学社会计算与信息检索研究中心微信公共号:”哈工大SCIR” 。





