
论文题目:Has multimodal learning delivered universal intelligence in healthcare? A comprehensive survey
作者单位:新加坡国立大学、北京邮电大学、西北工业大学、西安交通大学、南洋理工大学
论文地址:点击访问

1 引言
人工智能的迅猛发展正在重塑智能健康和智能医疗的版图。多模态学习,作为一种关键的学习技术,因其能够整合互补数据、全面融合信息以及拥有巨大的应用前景而日益受到重视。众多研究者正聚焦于这一领域,开展广泛研究,并构建了众多智能系统。随之而来的一个问题是:多模态学习是否已经在医疗保健领域实现了通用智能?为了解答这一问题,本综述文章从三个独特的视角出发,进行了全面的分析。首先,文章综述了医学多模态学习的研究进展,涵盖了数据集、任务导向方法和通用基础模型三个方面。基于此,文章进一步探讨了五个核心问题,旨在探究先进技术在医疗保健领域的实际影响,从数据和技术层面到效果和挑战。结论是,目前的技术尚未在医疗领域实现通用智能,相关技术仍在不断发展中。最后,根据综述和讨论的结果,文章提出了十个潜在的研究方向,以推动多模态融合技术在医疗保健领域的发展,朝着实现通用智能的目标迈进。

从多模态数据、建模技术到下游任务的医疗多模态学习 2 面向医疗任务的方法归类
人工智能技术在医疗领域被广泛应用,本文介绍了六个方向上的相关工作:多模态图像融合、医学报告生成、医疗VQA、跨模态检索、文本增强图像处理、跨模态图像生成。
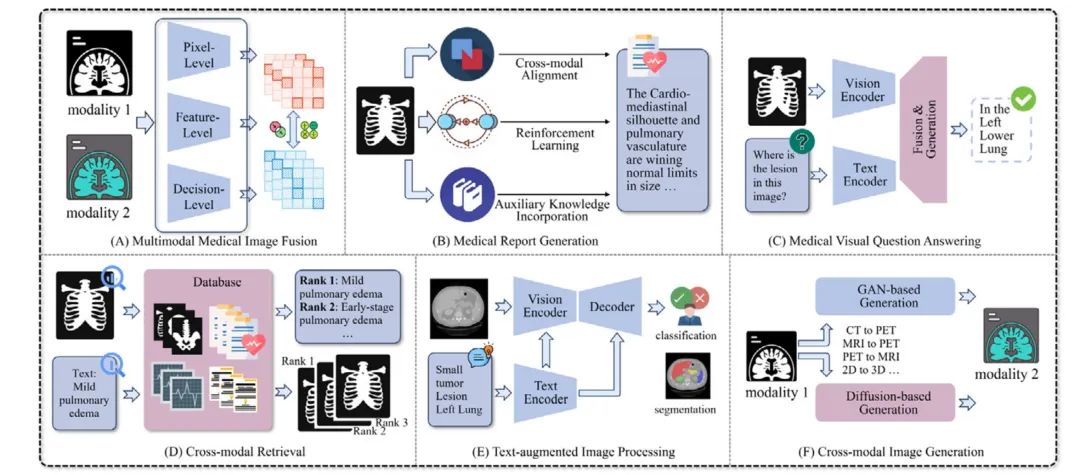
医疗多模态学习的主流应用方向
3 基于对比学习的医疗基础模型(CFMs)
鉴于医疗领域数据的内在稀有性、特异性和专业性,将大规模高质量的注释数据用于训练是具有挑战性和不切实际的。因此,许多研究引入了一些自监督策略来构建通用的基础模型(FMs),他们通常是指通过自监督学习对大规模数据进行预训练来获取广泛表示的一般知识模型。随后,可以通过微调使其适用于下游任务。FMs有以下几个关键特征:(1)在大规模通用数据集上进行预训练;(2)自监督学习策略,如对比学习和掩码语言建模;(3)通用知识表示,这意味着FM学习到一种通用的、独立于任务的知识表示,只需少量微调,即可应用于各种不同的下游任务。根据训练策略和应用,它们可以分为两类:对比FMs(CFMs)和多模态大语言模型(MLLMs)。CFM专注于通过联合优化图像编码器和文本编码器来学习一个共同的跨模态表示空间,以最大限度地提高正样本(图像-文本对)的相似性得分,并最小化负样本的相似性分数。医疗领域的典型CFMs如下表所示。
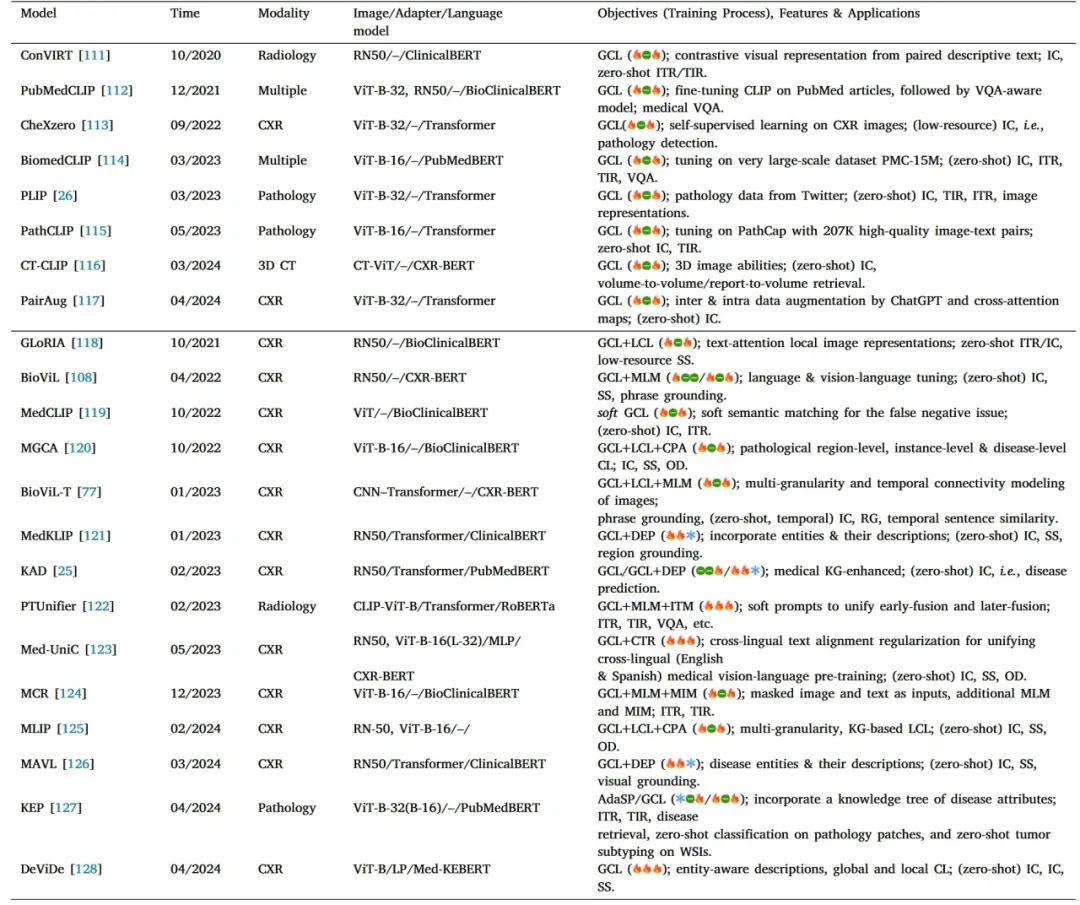
4 多模态医疗大语言模型
MLLM更侧重于对内在的跨模态关系进行建模,实现跨模态计算,并能够生成文本输出。受益于大模型(LLM)的快速发展,MLLM(也称为视觉语言模型VLMs),因其强大的表征能力和处理多模态数据的出色能力而受到研究人员的广泛关注。它们的总体建模目标是基于图像和之前的文本token进行下一个token预测。医疗领域典型的MLLMs如下表所示,文章从模态编码器和跨模态适配器、微调过程和技术细节、微调数据、评估基准、医疗MLLM应用五个方面展开介绍。
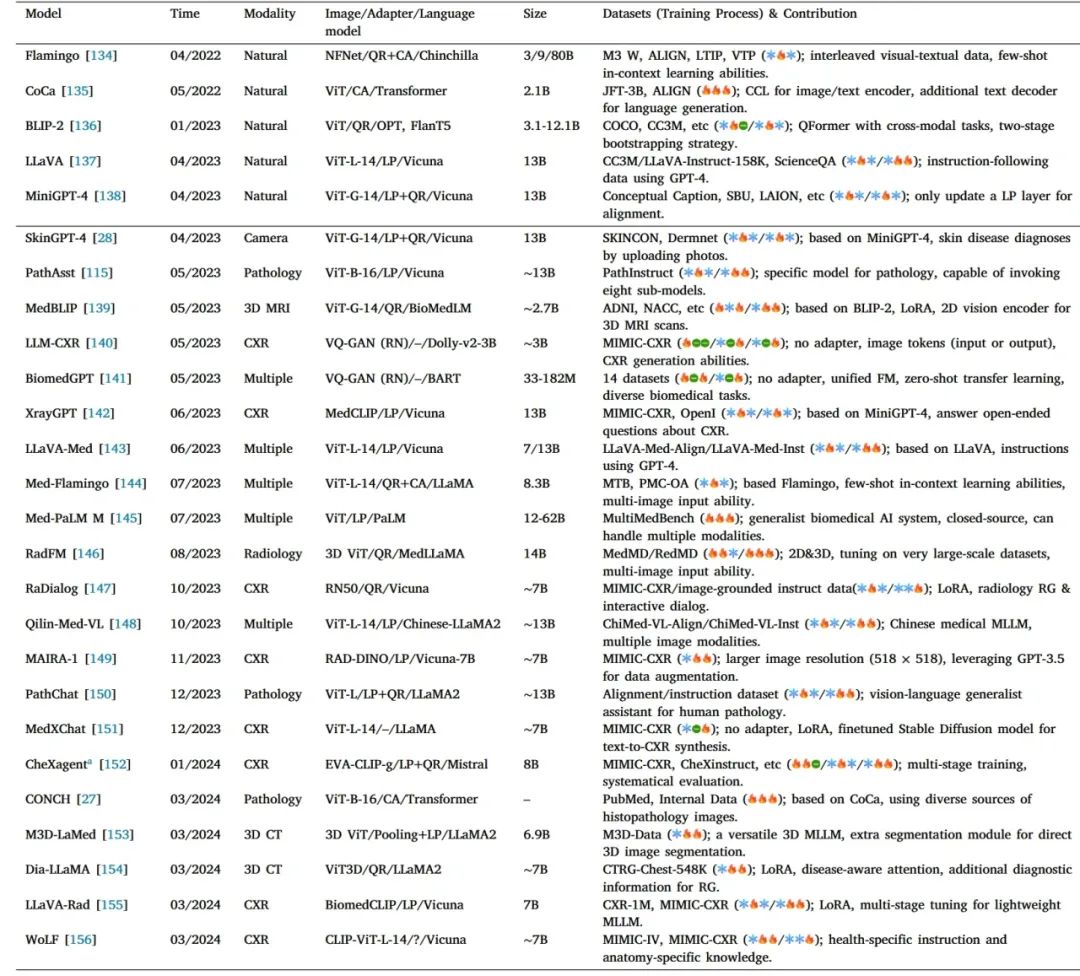
5 当前挑战问题
(1) 现有的多模式数据能否支持推进智能医疗?
- 缺乏综合性的、高质量的、细粒度的大规模数据集支撑。 (2) 任务导向的方法能有效地解决目标任务吗?
- 存在性能欠佳、鲁棒性不足、背景设定单一等问题。 (3) 基础模型如何为智能医疗做出贡献?
- 提供了多任务的统一解决框架,但也存在部署复杂、训练和推理效率低的问题;效果不佳。 (4) 当前的人工智能模型是否存在伦理问题?
- 医疗多模态模型可能存在偏见、伦理问题已经道德风险。 (5) 专业人士如何评估当前的多模态人工智能技术?
- 医疗专业人员对潜在的挑战(性能、鲁棒性、伦理问题等)表示担忧。
6 未来研究方向
根据医疗保健技术的进步和上述讨论,论文概述了以下潜在的未来方向:高质量和多样化的数据、包含更多类型的模态、细粒度和高分辨率的图像建模、有效和高效的知识融合、多模态输入和多模态输出、迈向统一模型、激发基础模型的全部潜力、全面和公正的评估协议、增强面向用户的透明度和可解释性、最大限度地降低道德风险。

