

论文题目:COTS: Collaborative Two-Stream Vision-Language Pre-Training Model for Cross-Modal Retrieval 作者:卢浩宇,费楠益,霍宇琦,高一钊,卢志武,文继荣 通讯作者:卢志武
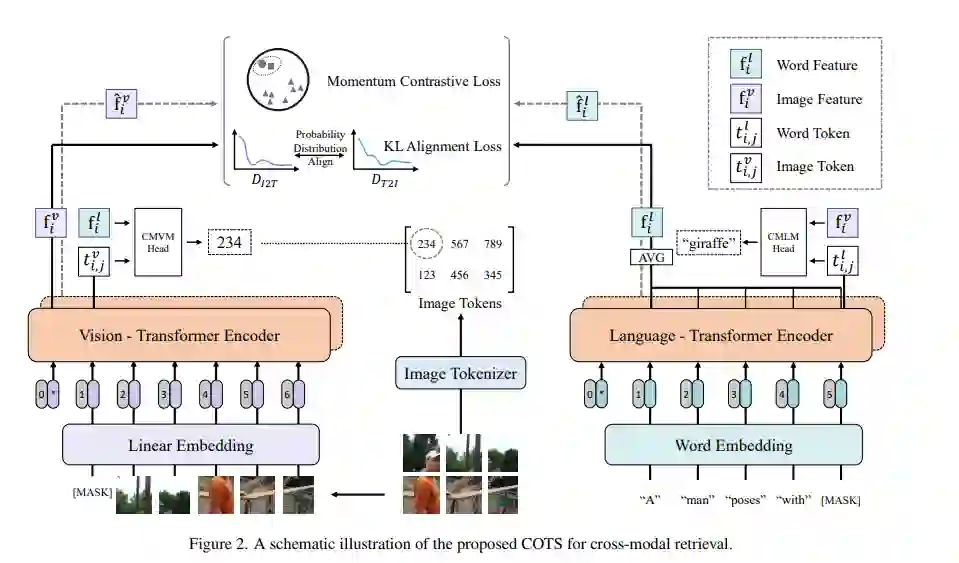
论文概述:大规模的单塔预训练模型,在跨模态检索中取得惊人的检索效果。遗憾的是,由于它们大多采用耗时的实参跨模态交互方式,检索效率非常低。最近,像CLIP和ALIGN这样具有高推理效率的双塔模型也表现出了良好的效果,然而,它们只考虑了模态之间的实例级对齐(因此仍有改进的余地)。为了克服这些限制,我们提出了一个新颖的协同式双塔视觉语言预训练模型,简称为COTS。总的来说,我们提出的COTS是通过加强模态间的交互来提高图像-文本检索效果的。除了通过动量对比学习进行实例级的对齐之外,我们还提出了两种额外的跨模态交互。(1) Token级的交互—在不使用实参交互模型的情况下,我们设计了一个遮蔽视觉语言建模(MVLM)的学习目标,其中变分自编码器用于视觉编码,可为每个图像生成视觉token级别的标记。(2) 任务级的交互—在文本到图像和图像到文本的检索任务之间设计了一个KL-对齐学习目标,其中每个任务的概率分布是用动量对比学习中的负样本队列计算的。在公平比较下,我们提出的COTS在所有双塔方法中取得了最好的结果,与最新的单塔方法相比,COTS表现出相当的能力(但推理速度快10,800倍)。同时,我们提出的COTS也适用于从文本到视频的检索,在广泛使用的MSR-VTT数据集上取得了目前最好的结果。
成为VIP会员查看完整内容
相关内容


相关VIP内容
相关资讯