

摘要
检测、预测和缓解交通拥堵旨在提高交通网络的服务水平。随着对更高分辨率的更大数据集的访问越来越多,深度学习与此类任务的相关性正在增加。近年来的几篇综合调查论文总结了深度学习在交通领域的应用。然而,交通网络的系统动态在非拥堵状态和拥堵状态之间存在很大差异,因此需要清楚地了解拥堵预测所面临的挑战。在本次综述中,我们展示了深度学习应用在与检测、预测和缓解拥堵相关任务中的当前状态。重复性和非重复性拥堵将单独讨论。我们的综述使我们发现了当前研究状态中固有的挑战和差距。最后,我们对未来的研究方向提出了一些建议,作为对已确定挑战的答案。
关键词:深度学习、交通、拥堵、重复性、非重复性、交通事故
1 引言
交通拥堵降低了道路网络的服务水平 (LOS)。LOS 的降低会给社会带来直接和间接的成本。已经进行了广泛的研究来估计拥堵对经济和整个社会的影响(Weisbrod 等人,2001 年, Litman,2016 年)。交通拥堵的第一个影响是工作时间的损失。Schrank等人(2012 年)估计,仅美国一年就因交通拥堵损失了 88 亿小时的工作时间。当时间作为一种商品的价值在紧急情况下急剧增加时,拥堵的不利影响会急剧上升。堵车会影响个人的行为。 Hennessy 和 Wiesenthal (1999)报告说,高度拥堵会导致司机的攻击性行为。这种攻击性可以表现为攻击性驾驶,从而增加发生事故的机会(Li等人, 2020a)。高度拥堵也会导致温室气体排放量增加(Barth 和 Boriboonsomsin,2009 年)。
就可处理性而言,拥堵预测是比非拥堵条件下的交通预测更困难的问题(Yu等人, 2017)。预警系统使交通管制员能够采取缓解措施。几十年来,交通数据收集所需的基础设施得到了改善。这一改进与计算资源可用性的提高相结合,使交通运输研究人员能够利用深度神经网络对该领域进行预测。在本次调查中,我们讨论了深度学习在检测、预测和缓解拥堵中的应用。我们研究了两种类型的拥堵的各个方面——重复性和非重复性。在本次调查结束时,我们确定了该领域研究现状的一些差距,并提出了未来的研究方向。
2 预备知识
本综述论文的目标受众是来自交通和深度学习两个背景的研究人员。本节介绍了预备知识并介绍整个综述中使用的术语。(略,详见原文)
3 以往的综述和本综述的组织
深度神经网络中的非线性激活函数可以捕捉交通数据中的非线性(Polson 和 Sokolov,2017)。如第 2.1 节所述,网络的深度使我们能够对数据中的高级特征进行建模。交通数据的特点是空间和时间的变化。两种专门的神经网络架构,CNN 和 RNN(也在 2.1 中讨论过)对于捕捉这些变化非常有帮助。 CNN 在建模空间相互依赖性时很有用,而 RNN 在建模数据时间变化时很有用。在我们的文献回顾过程中,我们发现大多数成功的交通预测神经网络架构都是使用 CNN 和 RNN 单元作为构建块设计的。
Wang (2019)等人对交通系统各个方面的深度神经网络进行了广泛的总结。它们使用深度神经网络涵盖了广泛的交通相关预测任务——交通信号识别、交通变量预测、拥堵识别和交通信号控制。Nguyen等人(2018 年)除了涵盖了上述任务外,还包括其他三个任务中,即出行需求预测、交通事故预测和驾驶员行为预测。Wang等人(2020a) 调查了深度学习在使用时空数据的各个领域(交通、人类流动、犯罪分析、神经科学和基于位置的社交网络)中的应用。他们的评论包括最近处理诸如交通变量预测、轨迹分类、轨迹预测和出行模式推断等任务的深度学习方法的论文。Wu等人(2020)对图神经网络 (GNN) 进行了分类调查,并强调了 GNN 在包括交通运输在内的不同领域应用。Xie等人(2020) 总结了将深度学习用于城市中最常见的流量类型的各种方法——人群流量、自行车流量和交通流量。
拥堵预测是指对即将发生拥堵时的交通状态变量进行预测。这是交通预测的一个特例。与交通预测相比,拥堵预测任务的相对困难可归因于超出最大流量点的交通动态不稳定性(Chung,2011)。这种较高的相对难度也很明显,因为典型的交通预测模型性能随着交通状态的接近而下降。与其他数据驱动方法相比,深度学习对拥堵预测的重要性还在于深度学习模型的稳定性相对较高(Yu等人, 2017)。据我们所知,不存在涵盖深度学习在拥堵相关任务中应用的全面调查论文。这篇调查论文试图弥合文献中的这一差距。我们讨论了深度学习在检测、预测和缓解两种类型的拥堵(重复性与非重复性)中的应用。拥堵预测部分没有区分重复性与非重复性情况,因为从交通图像中检测拥堵的深度学习模型可以检测这两种类型的拥堵。只要有可能,我们就试图从政策制定者的角度考虑挑战。纳入政策制定者的观点对于使研究成果可在现实世界环境中部署非常重要。当前调查的范围如图 8 所示。
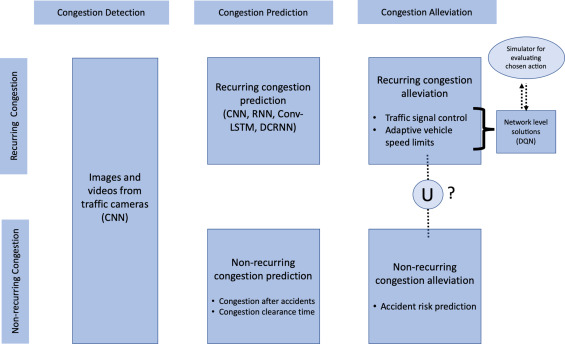
图 8. 显示调查各个部分的总体流程图。问号表示重复性与非重复性拥堵缓解之间的潜在联系。
深度学习架构关键设计方面和每篇论文中使用的数据集方面都已进行了总结,以便读者在处理类似数据集时可以参考这些论文。一些论文对他们的模型进行了广泛的敏感性分析。我们在每个小节末尾的摘要中复制并强调了关键见解。
本次调查涵盖的大多数研究论文发表于 2016 年至 2021 年期间。有时,为了简要讨论一些算法范式的背景,我们参考了过去的经典论文。
4 用于拥堵检测的深度学习
随着对新数据源的访问越来越多,正在探索自动检测交通拥堵的新机会。与其他两个部分不同,拥堵检测模型不区分重复性与非重复性拥堵。之所以如此,是因为拥堵检测模型总是检测这两种类型的拥堵,而不管它们背后的因果因素如何。相反,它们会根据所使用的数据源进行区分。检测这两种类型的拥堵最常用的来源是从交通摄像机获得的图像和视频。
无一例外,使用交通摄像头图像的好处是,所有车辆都被捕获在交通图像中。因此,不需要考虑渗透率(被跟踪车辆的百分比)等其他因素。随着道路上摄像机数量的增加,人类从图像中识别拥堵的认知负荷很高。为了减少认知负荷,深度学习已被广泛应用于交通图像拥堵的自动检测。众所周知,在计算机视觉 (CV) 任务中表现良好的深度学习模型已被用于检测交通拥堵。 CV 指的是从图像中提取有用信息的任务。
卷积神经网络 (CNN) 构成了用于图像分类任务的常用深度学习架构的模块。该领域的开创性工作有:AlexNet (Krizhevsky等人, 2012), InceptionNet (Szegedy等人, 2015), Resnet (He et al., 2016), R-CNN (Girshick et al., 2014), Mask-RCNN (He et al., 2017)、VGGNet (Simonyan and Zisserman, 2014) 和 YOLO (Redmon等人, 2016)。在 ImageNet (Lin等人, 2014) 和 COCO (Lin等人, 2014) 等大型图像数据集上预训练的深度神经网络很容易获得。当使用众所周知的架构进行交通图像分类时,三种方法是可能的。当手头数据集中可用的交通图像数量非常多(大约 10000 张图像)时,可以使用可用数据从头开始训练这些模型。当可用数据集较小时,将采用的深度学习模型的权重初始化为可用的预训练模型。第三种方法是保留预训练的模型,并按顺序添加另一个模块。当应用于图像时,深度学习模型可用于估计图像中的车辆总数,从而使我们能够估计交通密度。当应用于视频数据(一系列图像)时,深度学习模型可用于估计交通速度。
利用基于 CNN 的架构的两种变体(AlexNet 和 YOLO)(Chakraborty 等人,2018 年),对从美国爱荷华州 121 台摄像机在 6 个月内收集的交通图像,采用二进制分类来检测拥堵。将交通图像手动标记为拥堵和非拥堵标签是一项耗时的任务。因此,作者使用使用车辆环路检测器 (VLD) 获得的占用数据,根据占用情况将图像自动标记为两类(占用被标记为“拥堵”)。据报道,AlexNet 检测拥堵的准确率为 90.5% 和 YOLO 为 91.2%。Wang等人(2018) 比较了 AlexNet 和 VGGNet 的两种变体,以检测从中国陕西省的 100 多台摄像机获得的交通图像的拥堵情况。他们的数据集非常多样化——包括白天和夜间交通和不同天气条件的图像。他们的结果显示两种架构的性能相当(AlexNet 为 78%,VGGNet 为 81%)。他们报告说,由于神经网络的规模较小,AlexNet 的训练速度明显更快。他们使用了二进制分类(“jam”或“no jam”)。 Impedovo 等人(2019)比较了 YOLO 和 Mask-RCNN 在从两个交通图像数据源(GRAM 和 Trafficdb)获得的三个手动标记数据集上的性能。这三个数据集的图像质量各不相同——首先,包含 23435 张低分辨率 (480×320p) 的图像,其次,包含 7520 帧中等分辨率 (640×480p) 的图像,第三个包含 9390 帧高分辨率 (1280×720p) 的图像。他们分两步实现拥堵检测。第一步侧重于识别每帧中的车辆数量。在这一步中,Mask-RCNN 的准确率分别为 46%、89%、91%,而 YOLO 的准确率分别为 82%、86%、91%。 YOLO 的性能对图像质量有抵抗力,训练时间几乎是 Mask-RCNN 的一半。他们选择 YOLO 作为目标检测器模型,并将其输出作为第二步的输入。第二步,他们在 YOLO 的输出上使用 Resnet 来预测交通拥堵,作为一个多类分类任务(3 类)。报告的轻度、中度和重度拥堵准确率分别为 99.7%、97.2% 和 95.9%。
Kurniawan 等人(2018)使用了 CNN 模型。为了对在印度尼西亚雅加达获得的交通图像进行分类。使用 14 个摄像头位置,收集数据 15 天。他们使用手动将交通图像标记为“拥堵”和“未拥堵”类别。使用 10 倍交叉验证报告的平均准确率为 89.5%。 Rashmi 和 Shantala (2020) 研究了在流量高度异构时 YOLO 的性能。他们从印度卡纳塔克邦收集了一周的数据。他们使用在 COCO 数据集上预训练的 YOLO 模型进行迁移学习。在计算图像中的车辆时,YOLO 在公共汽车、汽车和摩托车方面表现良好(准确率在 92% 和 99% 之间),但在预测研究区域特定的交通方式时,性能下降到任何有用的水平以下。
摘要:我们观察到基于数据源的图像质量存在显着差异。这导致模型性能的差异。由于交通流的巨大异质性,从发展中国家获得的交通图像提出了一项重大挑战。数据集之间的另一个主要区别是,当存在替代数据源(例如 VLD)时,可以自动创建训练数据的标签,而不是手动标记。如果从交通摄像头获得的图像质量不高,可以使用基于深度学习的图像超分辨率进行改进。图像超分辨率是指提高输入图像分辨率的任务。基于深度学习的超分辨率已经在计算机视觉界得到了广泛的研究,但我们还没有看到它在提高交通图像质量方面的应用。Wang 等人(2020b)对图像超分辨率的深度学习应用进行了全面调查。改进摄像机拥堵检测的另一个潜在途径是基于深度学习的视频帧率增量(Jiang et al., 2018)。
5 用于拥堵预测的深度学习
5.1 用于重复性拥堵预测的深度学习
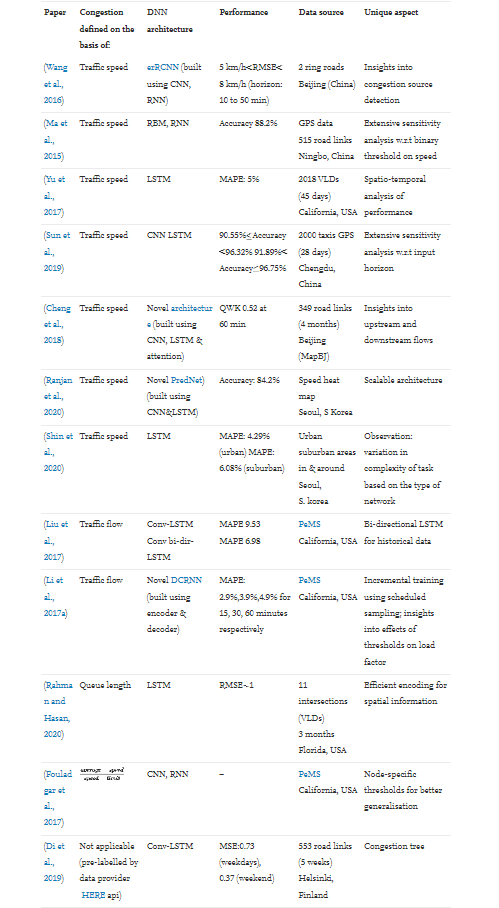
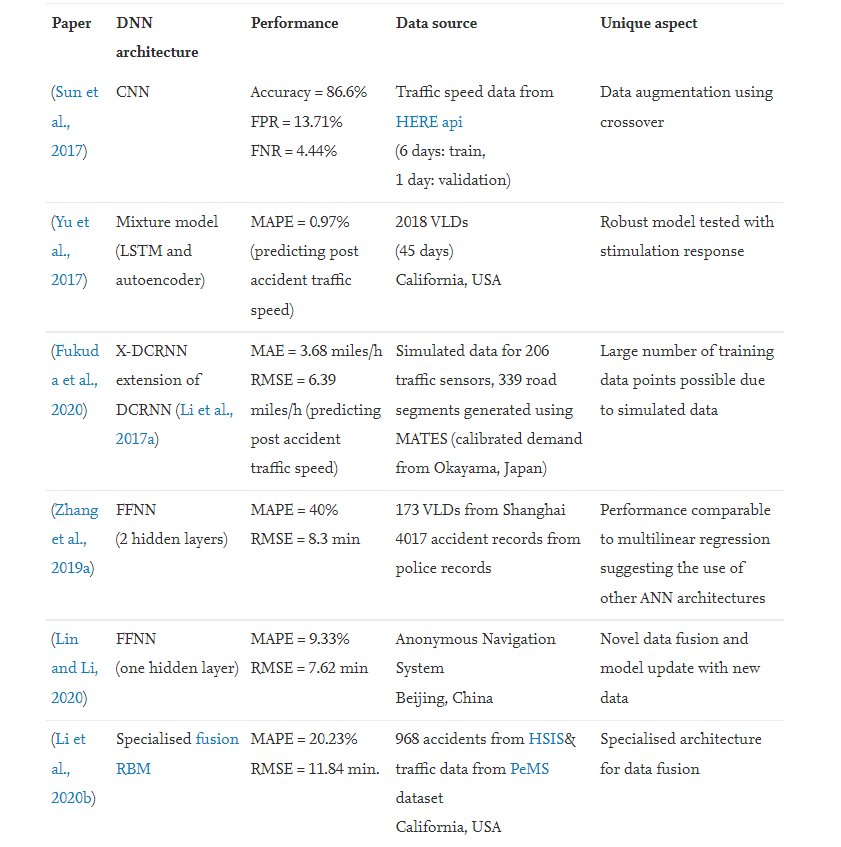
由于基础设施瓶颈不足以应对高峰需求,因此经常发生拥堵。根据定义,重复性拥堵发生在网络中熟悉的位置。根据这个定义,预测重复拥堵的具体任务是预测发生时间的每日变化和重复拥堵的严重程度。最常用的拥堵预测任务是二进制分类(“拥堵”或“无拥堵”)。一些论文将拥堵预测为多类分类任务(“轻”、“中”和“重”拥堵)。需要注意的是,本节中的一些论文并未预测交通拥堵,而是将短期交通预测作为回归任务(预测速度、密度、流量、队列长度等)。如果在交通状况接近拥堵时报告其模型性能稳定,则此类论文已被包括在内。对于此处列出的每篇论文,我们都报告了其绩效指标的关键方面以及敏感性分析的关键要点。本小节讨论的论文总结在表 1 中。
表1 总结了第 5.1 节中讨论的论文(用于重复拥堵预测的深度学习)
使用 LSTM 模型:Yu 等人(2017)使用了 LSTM 模型。 预测高峰时段的交通速度。他们使用来自美国加利福尼亚州车辆环路检测器 (VLD) 速度记录的公开可用的 Caltrans 数据集,并尝试预测每个传感器位置下一小时的交通速度。据报道,在预测高峰时段的交通速度时,他们的 LSTM 模型实现了 5% 的 MAPE。他们研究的一个重要观察结果是时间戳特征(一天中的时间和一周中的一天的编码值)显着提高了高峰时段的预测性能。这种合并时间戳的做法已在后来出现的论文中采用。在本文中,每个 VLD 都是单独建模的。在随后的论文中,研究人员开发了将空间信息整合到 LSTM 模型中的技术,因此提出了一个用于同时预测多个交叉口拥堵的单一模型。 Rahman 和 Hasan (2020) 使用 LSTM 模型通过有效地结合空间信息来预测交叉口的队列长度。为了预测下一个交通周期(红色信号)查询路口的队列长度,他们的模型将查询路口的队列长度和当前周期的两个上游路口的队列长度作为输入。然后他们尝试预测下一个周期的查询交叉点的队列长度。他们使用在佛罗里达州奥兰多市为期三个月的 11 个十字路口收集的 VLD 数据。在预测队列长度时,他们报告的平均 RMSE 接近 1(从他们的图中推断)。
比较 LSTM 和 CNN:Sun 等人(2019)介绍了卷积神经网络 (CNN) 和循环神经网络 (RNN) 在预测交通拥堵方面的性能比较。他们的数据集包括中国成都 2000 辆出租车的 28 天 GPS 轨迹。他们使用地图匹配将 GPS 轨迹映射到路段,并计算每个路段在 5 分钟时间段内的平均速度。然后,他们使用平均速度值根据平均交通速度定义四个拥堵级别。报告的最佳模型平均速度预测的 RMSE 为 3.96 km/h。然后针对预测的拥堵程度报告分类精度。他们得出的结论是,给定足够长的输入范围(90 分钟),CNN 模型的性能与循环网络模型一样好。我们认为这是一个重要的观察结果,原因有二。首先, CNN 模型的训练速度更快,因为它们通过构建以更有效的方式支持 GPU 并行化,如果在探索 LSTM 之前将 CNN 作为建模选项进行探索,则可以节省研究人员的时间。其次,由于 LSTM 在独立使用时通常用于捕获交通数据中的长期依赖关系,因此它们对于短期交通预测可能不是很有用。本小节以下的论文使用 CNN 和 RNN 的组合来设计专门的架构。
使用 LSTM 和 CNN 的组合:Liu 等人(2017) 提出了 Conv-LSTM,它由 CNN 和 LSTM 单元组成。卷积运算用于捕获空间相关性。卷积运算的输出用作 LSTM 单元的输入。在使用他们的 Conv-LSTM 模型来预测交通流量时,他们实现了 9.53% 的 MAPE。此外,它们还包括一个双向 LSTM 模块,以包含历史数据的影响并实现 6.98% 的较低 MAPE。据报道,性能在不同的交通流量水平上是稳定的,因此我们将他们的论文作为拥堵预测模型纳入其中。Ranjan 等人(2020)预测了 10、30 和 60 分钟三个城市范围内的交通热图。由于输入和输出热图具有相同的维度,因此他们提出了一种对称的 U 形架构,在两端(输入和输出端)都有 CNN 块。瓶颈层(最高深度)由四个 LSTM 单元组成,跳跃连接用于连接不同深度的 CNN 输出。提出的架构称为 PredNet。该数据集包含基于从韩国首尔收集的空间平均交通速度的交通热图。他们数据的时间分辨率为 5 分钟。拥堵被定义为基于交通平均速度的三级变量。他们报告说 PredNet 的性能随着输出范围长度的增加而稳定。在预测未来 60 分钟的拥堵时,PredNet 的平均准确率为 84.2%(相比之下,在相同数据上使用 Conv-LSTM 时为 75.67%)。据报道,与本段前面讨论的 Conv-LSTM 模型相比,PredNet 的训练速度要快得多(快 8 倍)。
特别关注路网异质性:一些论文强调了基于路网异质性的拥堵预测任务复杂度的差异。当尝试在网络的大部分区域进行多个时间步长的拥堵预测时,尤其会报告此类观察结果。 Shin 等人(2020) 使用三层 LSTM 网络来预测从韩国首尔及其周边地区的城市和郊区收集的数据中的拥堵程度。道路连接总数为 1630,数据以 5 分钟的分辨率收集了一个月。数据集丢失了 33% 的记录。为了处理丢失的数据,他们提出了一种基于趋势过滤的时空异常值检测和数据校正算法。该模型预测交通速度,根据当地政策制定机构推荐的阈值输出拥堵程度。该模型的性能在整个交通速度范围内都是稳定的,因此我们将他们的工作纳入到拥堵预测模型中。他们报告了该模型在预测首尔周围两种不同类型道路网络的交通速度时的差异(郊区的 MAPE 为 4.297%,城市道路的 MAPE 为 6.087%)。然而,与城市道路相比,一些郊区道路的平均绝对误差 (MAE) 更高(城市:2.54 公里/小时,郊区:2.78 公里/小时)。他们承认郊区道路的高 MAE 误差实际上具有误导性,因为郊区道路的平均速度更高。从他们的论文中得出的结论是,在应用深度学习来预测拥堵时,不同类型的道路呈现出不同的复杂性。
Cheng等人(2018)提出了一种使用 CNN、RNN 和注意力机制构建的专用架构来预测拥堵水平。他们的数据集称为 MapBJ,由 4 个月的数据组成,这些数据在北京的 349 个道路连接处以 5 分钟的时间分辨率收集。基于称为“限制级别”的速度限制标准化变量,每个道路连接都被标记为四个拥堵级别(流畅、缓慢、拥堵、极端拥堵)之一。没有给出“限制水平”的确切数学表示,但是,这个想法类似于使用由 (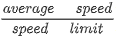
大规模循环拥堵预测(Congestion propagation) 拥堵传播可以理解为拥堵预测的一种特例。它研究的是网络中更大一部分拥堵的演变,而不是通常拥堵预测模型所涵盖的范围。拥堵传播可以和拥堵预测放在同一个标题下研究。然而,在本次调查的文献搜索过程中,我们发现,当使用深度学习模型预测整个网络的交通拥堵时,会遇到特殊的挑战。
Li 等人(2017a)提出了一种称为 DCRNN 的专门架构。为了预测几个时间步长(15 分钟、30 分钟和 1 小时)的交通流量。使用的数据集是 PeMS。该模型在高峰时段和不同流量水平下的性能没有变化,因此本文已作为拥堵预测模型包含在内。 DCRNN 由编码器和解码器组件组成。编码器将带有空间参数的交通流数据编码成图形并输出隐藏状态。解码器尝试使用编码器的隐藏状态概率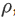
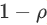
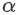
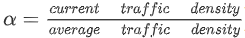
Ma 等人(2015) 使用受限玻尔兹曼机 (RBM) 与递归神经网络 (RNN) 模型相结合来预测拥堵的演变。该数据集包括在中国宁波 515 条道路上行驶的出租车的 GPS 轨迹。他们使用网络范围的流量速度阈值来确定预测的流量速度是否意味着拥堵。他们报告的平均准确率为 88.2%。他们的敏感性分析中一个有趣的观察是阈值的增加会降低模型的性能。他们假设这可能是由于当较高百分比的道路链接属于拥堵类别时,拥堵传播模式的波动较大。Fouladgar 等人(2017) 使用来自加利福尼亚的 PeMS 数据集,并提出了一个分布式网络,其中道路网络的每个交叉点都使用单独的深度学习模型进行建模。他们结合使用 CNN 和 RNN 架构来预测拥堵程度。为了二值化拥堵,他们引入了节点特定的阈值,而不是网络范围的通用阈值,从而使他们的模型与 (Ma 等人, 2015) 的模型相比更具表现力。节点特定的阈值是使用平均速度与速度限制的比率 (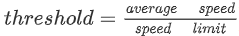

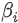
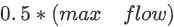
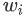
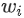
Wang等人(2016) 提出了 erRCNN,它是使用 CNN 单元和 RNN 单元构建的。在图 7 中,我们观察到当流量超过阈值时,速度-密度曲线变得分散,并观察到平均速度的突然变化。他们的 erRCNN 架构被证明可以处理这些突然的变化。纠错 RNN 允许在预测性能因流量状态变化而下降时更新模型。因此,该模型能够处理流数据。他们使用了从中国北京的两条主要环路收集的 GPS 数据集。报告的速度预测 RMSE 在预测范围为 10 分钟时的 5 km/h 和预测范围为 50 分钟时的 8 km/h 之间变化。此外,为了了解拥堵传播的来源,他们提出了一个称为分段重要性的度量标准。每个网段都会影响其他网段的流量。如果所讨论的道路有n个路段,则可以假设经过训练的 errRCNN 模型已经学习到了每个路段在 t+1 时刻的交通速度与每个路段的交通速度之间的映射。数学上,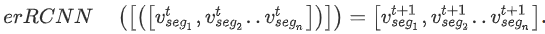
拥堵树的深度学习:历史上用于对拥堵传播进行建模的另一种流行方法利用了拥堵树的概念。已经尝试使用深度学习来模拟拥堵树的演变。当一个路段的拥堵导致相邻路段的拥堵累积时,就形成了拥堵树。可以通过去除它们之间的冗余来组合几个拥堵树。这就产生了拥堵图。Di等人(2019)通过组合拥堵树创建有向无环图(DAG)来消除拥堵树之间的冗余。然后将该 DAG 转换为拥堵级别的空间矩阵,矩阵的每个单元最多代表一个段。空间矩阵有助于保留路段之间的邻接信息。然后将这些空间矩阵 (SM) 的序列传递给 Conv-LSTM 模型,用于在下一个时间步预测 SM。预测的 SM 被转换回拥堵图,然后转换为拥堵树,然后可用于提供预测的拥堵演变的可视化表示。当使用 5 分钟的预测范围时,他们报告了工作日流量的均方误差 (MSE) 为 0.27,周末流量为 0.07。 15 分钟的 MSE 为 0.73(工作日)和 0.37(周末)。在他们的结果中,MSE 没有单位,因为它不是针对交通变量计算的,而是针对空间矩阵计算的。作为比较,当使用 5 分钟的预测范围时,LSTM 模型在工作日实现了 0.59 的 MSE,在周末实现了 0.32 的 MSE。
小结:在本小节中,讨论了深度学习在预测重复拥堵中的各个方面的应用。本小节的要点总结如下:
表1 总结了第5.1节(用于重复拥堵预测的深度学习)中讨论的论文。
-
我们观察到,在保持数据集和特定预测任务固定不变的情况下,很少有人尝试全面比较不同深度学习模型的性能。我们知道,深度学习模型的性能很大程度上取决于超参数的选择(例如隐藏层数、卷积数、学习率等)。当针对特定任务提出新的深度学习架构时,与以前使用的架构进行公平比较可能不可行。这背后的原因是深度学习模型的最佳性能涉及训练大量模型以确定最佳超参数集。因此,对之前的所有工作进行如此微调是不合理的。解决方案可能是为每个数据集建立公共基准,同时保持测试、训练、验证拆分固定。这种特定于数据集的基准在计算机视觉社区中广受欢迎。它们可能会显著减少复制先前论文结果的重复工作。这种基准的另一个好处是减少数据预处理的重复,因为它可能比训练深度神经网络本身更耗时。
-
特别是,在预测网络大部分时间步长的拥堵时,我们观察到一些论文中报告了广泛的敏感性分析,以揭示性能的时间和空间变化。突出这种性能差异导致未来的工作旨在改善深度学习模型的空间和时间泛化。我们相信这是一个很好的趋势,未来的研究应该包括更多这样的分析。它还有助于我们了解使用深度学习进行短期流量预测的局限性。根据此处介绍的论文,预测的最大时间范围似乎是 60 分钟。我们相信,未来增加预测范围的尝试将有助于获得对基于深度学习的交通拥堵预测解决方案的信任。
-
我们发现很少有论文提出深度学习模型,这些模型会随着新数据的到来而更新。这被称为在线学习。在线学习是一个框架,而不是一个模型。因此,理论上任何深度学习模型都可以集成到在线学习框架中,并且可以演示模型更新。到目前为止,它并不流行,因为研究人员不容易获得实时交通数据。即使流式传输新的流量数据不可用,仍然可以通过使用历史数据的时间拆分来展示在线学习能力,并在模型在越来越多的数据上进行训练时评估模型性能。
5.2.针对非重复性拥堵的深度学习
目前还不清楚非重复性拥堵背后的详细原因(McGroarty, 2010)。随着新数据源的可用以及新的相关性和因果关系的建立,新的原因也随之增加。一些经过充分调查的非重复性拥堵原因是交通事故、多变的天气条件、灾难和计划中的事件。在本次调查中,我们专注于预测事故造成的拥堵的深度学习应用。将重点放在事故上的三个原因。首先,在这个经过充分研究的原因列表中,交通事故是大部分非重复性拥堵背后的主要原因(Hallenbeck 等人,2003 年)。其次,深度学习已被广泛用于预测交通事故后的拥堵。第三,调查由其他原因(天气、计划事件和灾难)引起的交通拥堵最适合使用交通模拟器进行基于场景的研究。此类研究通常在规划阶段进行,因此使用交通模拟器的高计算时间并不构成挑战(Aljamal 等人,2018 年)。文献检索表明,在使用深度学习方法预测交通事故后的拥堵时,特定的深度学习任务存在很大差异。我们将研究分为以下两类:
• 事故后交通拥堵预测
• 事故后交通拥堵清除时间预测
本小节讨论的论文总结在表 2 中。
事故后交通拥堵预测:Sun 等人(2017)提出了一种基于 CNN 的架构来预测事故后的交通流量。从交通信息系统(HERE api)获得的交通速度数据被转换为交通热图图像。如果速度 (v) 小于 80 英里/小时,则将像素值设置为 ,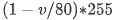
Yu 等人(2017)提出了一个混合模型,它有两个组件,一个由 LSTM 组成,另一个由自动编码器组成。事件数据被馈送到自动编码器,交通数据被馈送到 LSTM。最后,将两个组件的输出连接起来,并使用一个全连接层来输出每个传感器位置的交通速度。他们使用来自美国加利福尼亚州公开可用的 Caltrans 数据集的车辆环路检测器 (VLD) 速度记录。在预测 3 小时预测范围内的事后交通速度时,他们的模型实现了 0.97% 的 MAPE。相比之下,LSTM 模型的 MAPE 为 1.00%,三层前馈神经网络的 MAPE 为 3.65%。他们工作的一个有趣贡献是使用信号刺激来研究突然降低输入速度对模型响应的影响。他们报告说,当刺激仅持续很短的时间(<5 分钟)时,模型的响应保持不变,从而表明该模型对输入数据的微小波动具有鲁棒性。此外,他们报告说,当在高峰时段注入刺激时,模型响应会被放大。
Fukuda等人(2020) 提出了 X-DCRNN,它是 DCRNN 的扩展,以明确输入事件数据。他们的数据集是使用微观交通模拟器 MATES (Yoshimura, 2006) 上的模拟创建的。使用从当地交通部门获得的元数据校准交通需求。模拟器中的网络基于日本冈山市的中央商务区,由横跨 339 个路段的 206 个交通传感器组成,分布在 3 平方公里。他们的模型预测事故发生后的交通速度,并报告事故段和相应的下游段的错误。对于事故路段,报告的 MAE 为 0.74 英里/小时,RMSE 为 0.87 英里/小时。作为比较,在同一数据集上,DCRNN 模型实现了 1.97 英里/小时的 MAE 和 5.64 英里/小时的 RMSE。在预测紧邻下游路段的交通时,DCRNN 和 X-DCRNN 都达到了相似的性能水平。对于直接下游段,X-DCRNN 实现了 3.68 英里/小时的 MAE 和 6.39 英里/小时的 RMSE。作为比较,DCRNN 模型实现了 3.81 英里/小时的 MAE 和 6.33 英里/小时的 RMSE。
预测拥堵消除时间:拥堵消除时间是评估事故对交通拥堵影响的有用指标。事故发生后,由于受影响车道上的移动受限,交通流量减少。通常,流量最终会降低到最小值,然后恢复。在对拥堵消除时间进行建模时,这里介绍的大多数论文都关注从达到最大拥堵水平(最低流量)到流量恢复到事故前水平的时间之间的持续时间。 Zhang 等人(2019a)使用了具有两个隐藏层的 FFNN。他们使用从中国上海的 173 个车辆环路检测器 (VLD) 获得的平均速度和来自交警记录的事故数据来创建具有 9 个特征的输入向量。在预测拥堵清除时间时,他们的模型实现了 40% 的 MAPE 和 8.3 分钟的 RMSE。作为比较,多线性回归模型实现了 49.8% 的 MAPE 和 10.22 分钟的 RMSE。数据集中的事故记录总数为 4017 条。
Lin 和 Li(2020)利用了这样一种观点,即在事故后拥堵的情况下,无法立即获得有关事故的确切细节。当旁观者、相关方或应急响应人员评估损坏情况时,可以获得有关类型、位置、严重程度和受影响车道的更多信息。他们提出了一个能够随着新信息的到来更新预测的框架。他们将非重复拥堵预测定义为多类分类任务(5 类)。使用事故发生后达到的拥堵延迟指数 (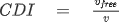
Li 等人(2020b)提出了一种称为融合 RBM 的架构,它是通过连接两组堆叠 RBM 的输出而创建的。他们模型的融合方面受到以下事实的启发:事故数据由分类变量组成,而交通数据是连续的。一个堆叠 RBM 单元将分类事故数据作为输入,而另一个堆叠 RBM 单元将连续数据作为输入。最后,将两个单元的输出连接起来并通过单个神经元,最终输出拥堵清除时间。使用 10 分钟增量(0-10、10-20 等)将预测的拥堵清除时间量化为 10 个级别。报告的 MAPE 为 20.23%,RMSE 为 11.84 分钟。他们使用了从加利福尼亚 (PeMS) 收集的交通数据和从高速公路安全信息系统 (HSIS) 收集的交通事故数据。他们数据集中的事故总数为 968 起,平均拥堵清除时间为 37 分钟。
小结:我们讨论了深度学习在预测事故后交通拥堵及其通行时间方面的应用。与重复拥堵预测的主要区别在于,必须融合来自多个来源的数据才能预测事故后的拥堵。这里介绍的每篇论文都以不同的方式处理数据融合的挑战,它们之间几乎没有达成共识。对来自多个来源的标准数据融合算法进行基准测试可能有助于为未来的研究人员提供有关最有效的交通数据融合技术的见解。数据融合已在物联网 (IOT) 社区中得到广泛研究。物联网研究的重点是不同设备之间的普遍通信,因此有效的数据融合得到了广泛的研究。交通研究人员可以从这些来源中汲取灵感,并探索使用有效数据融合技术改进事故后拥堵预测的可能性。Gao等人(2020)比较了不同深度学习架构的数据融合性能。他们调查中提出的大多数架构通常用于基于深度学习的拥堵预测任务,因此使用其中提出的见解会很有趣。预测事故后的交通拥堵也可以根据第 2.2 节中介绍的交通滞后曲线来理解。
表2 总结了第5.2节(用于非重复拥堵预测的深度学习)中讨论的论文。
6. 缓解拥堵的深度学习
拥堵缓解技术对于重复性和非重复性拥堵有很大不同。一方面,重复性拥堵是由于基础设施瓶颈不足以应对交通高峰需求造成的。因此,针对重复性拥堵的深度学习解决方案旨在通过以最佳方式分配需求来降低重复性拥堵的严重性。另一方面,非重复性拥堵主要是由于事故造成的。因此,缓解非重复性拥堵的深度学习应用旨在减少事故。深度学习已被广泛用于预测事故风险。预测的事故风险可用于提醒驾驶员或施加速度限制以减少事故。在本节的最后,我们讨论了减少重复性拥堵的努力与减少非重复性拥堵的努力之间的潜在联系。如前 5.1 节所述,非重复性拥堵的其他原因,如计划中的事件、恶劣天气和自然灾害,最适合使用交通模拟器进行基于场景的研究,因此,深度学习尚未广泛应用于非重复性拥堵由于这些原因。
6.1 用于缓解重复拥堵的深度学习
一旦拥堵预测模型预测出重复拥堵,就可以采取缓解措施来减少拥堵的累积。在网络层面,这可以通过控制供应参数来实现,例如十字路口的交通信号控制、匝道计量、实施限速限制和实施车道使用限制。在个人层面,这可以通过使用描述性、规范性或混合方法来实现。描述性方法包括向司机广播有关网络交通状况的重要信息,并帮助他们就行程开始时间和选择的路线做出明智的决定。规定性方法涉及对司机的具体行程建议(例如最佳开始时间和最佳路线选择)。混合方法使用描述性和规范性方法的组合。由于在这些方法中增加了人类行为建模层,描述性和规范性方法面临着重大挑战。在本次调查中,我们关注最近使用深度学习在网络层面缓解拥堵的研究。
使用需求方解决方案的挑战:使用描述性和规范性方法缓解拥堵时遇到的挑战在 Balakrishna 等人(2013)中进行了介绍。最大的挑战是信息从驾驶员流回网络。这些信息对于估计建议路线对道路的影响至关重要。他们强烈主张需要大规模跟踪数据。由于智能手机在城市地区的高普及率,这种实时交通信息越来越多地通过他们的手机传递给司机。然而,挑战来自描述性和规范性解决方案通常组合在一起的事实。当用户查询行车路线时,导航应用程序返回的首选路线会包含一些路线建议。这种个性化路线建议的最终目标尚不清楚,因为提供此类服务的公司将移动性作为一种服务提供,而算法细节是商业机密。 2018 年在美国进行的一项调查报告称,87% 的司机使用一些导航应用程序来获取行车路线建议(Manifest,2018 年)。谷歌地图发布的一份报告指出,每天有超过 10 亿公里的旅行使用他们的应用程序进行跟踪(Google,2020)。当这种个性化路线建议的覆盖范围和合规性增加时,它可能会改变交通系统中的用户平衡。由于私营部门的此类努力旨在将路线选择创建为一种服务,并且确切的方法作为商业机密被隐藏起来,因此很难估计与此类解决方案的公平性相关的潜在缺陷。在缺乏真实数据的情况下,研究人员使用经济工具来提高合规性,从而减轻对人类行为建模的任务。可以使用惩罚性措施或奖励来提高咨询措施的合规性。在这两种方法中哪一种被证明更有效,这是一个很难做出的选择。不同地理位置的惩罚措施的有效性相似,而基于奖励的措施的有效性差异很大(Tillema 等人, 2013, Li 等人, 2019)。两种常用的惩罚措施是拥堵收费和可交易代币。de Palma 等人(2018 年)提出了一种比较两种方法效果的方法,并强烈支持可交易代币。 de Palma 和 Lindsey(2011 年)讨论了使用新兴技术实现高效拥堵收费的各种方法。他们的建议之一是自动车牌识别 (ANPR)。深度学习已广泛应用于 ANPR。但是,本次调查未涵盖此应用程序。有兴趣的读者可以参考 Connie 等人,2018 年,Khan 和 Ullah,2019 年。Kyaw(2018 年)等人介绍了将 ANPR 应用于发展中国家所遇到的挑战。
网络层面的供给侧解决方案:我们专注于网络层面的缓解拥堵的深度学习应用。大多数此类工作都使用深度强化学习。如第 2.1 节所述,强化学习框架有四个主要组成部分:代理、动作、奖励和环境。策略的概念非常适合交通信号控制问题。可以通过优化奖励(例如网络中的最大累积流量)最小化的模型来找到最佳策略(例如,交叉路口不同方向的红灯和绿灯的顺序)。在最近的研究中,深度 Q 网络 (DQN) 被普遍使用,作者对调查此类解决方案的公平性方面越来越感兴趣。交通控制基础设施(例如交通信号或限速标志)被建模为代理。代理的选择决定了允许哪些操作。论文根据所选代理分为两个标题。
• 自适应交通信号控制(TSC)
• 可变限速控制(VSLC)
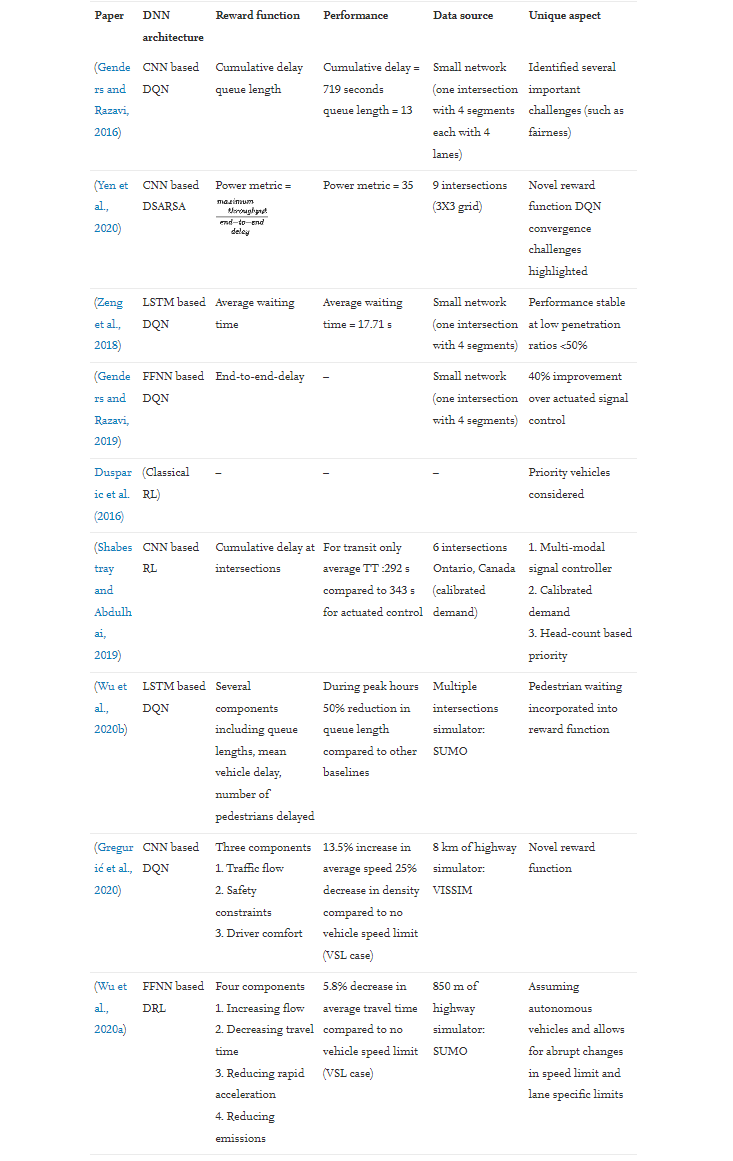
本小节中讨论的论文总结在表3
表3 总结了第6.1 节中讨论的论文(使用深度学习缓解经常性拥堵的供应侧解决方案)。
6.1.1.自适应交通信号控制 (TSC)
在 Genders 和 Razavi (2016) 中提出了基于 CNN 的 DQN,以便在交通模拟器中对信号控制代理进行建模。目标是通过优化这些代理的行为来最大化网络范围的吞吐量。他们根据三个参数分析模型的性能——累积延误、交叉路口的排队长度和平均行驶时间。他们为一个交叉口建模,该交叉口有四个路段,四个方向,每个路段有四个车道。车辆以 0 至 450 辆/小时的不同流速装载。左转和右转交通使用逆 Weibull 分布加载 (Rinne, 2008),而直通交通使用 Burr 分布加载 (Tadikamalla, 1980)。使用基于 CNN 的 DQN 来控制交通控制代理的动作,他们实现了 719 秒的累积延迟和 13 辆车的平均排队长度。作为比较,基于 FFNN 的具有一个隐藏层的 DQN 的平均队列长度为 33。他们强调了研究 DQN 优化策略的公平性方面的必要性。在没有模型的公平度量的情况下,算法可能会支持或不支持特定的流量移动。他们断言,最公平的策略可能不会产生最佳的流量吞吐量——因此,需要通过调整奖励函数来寻找两个目标之间的平衡。Yen等人(2020)试图通过在奖励函数中加入功率度量来解决这种目标差异。功率度量定义为最大吞吐量与端到端延迟的比值 (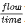
在这个方向上的另一个尝试是 Zeng 等人(2018) ,他们提出了使用基于 LSTM 的 DQN 的 DRQN(深度递归 Q 学习)。他们报告说,在由单个四向交叉口组成的合成网络上使用 DRQN 时,平均等待时间为 17.71 秒。用于装载车辆的分布是二项式的。基于 LSTM 的 DQN 的性能类似于 Genders 和 Razavi (2016) 中使用的基于 CNN 的 DQN。然而,当穿透率变化时,LSTM-DQN 模型的性能是稳定的。渗透率定义为道路上共享数据的车辆的百分比。当渗透率低于 0.5 时,基于 CNN 的模型表现不佳。在渗透率(意味着所有车辆的数据都可用)下,两种模型的性能相似。 Genders 和 Razavi (2019) 使用基于前馈神经网络 (FFNN) 的 DQN 来优化高峰时段的交通控制策略。与传统使用的交通信号控制驱动方法相比,他们报告说,使用由单个交叉口组成的合成网络,平均总车辆延误减少了约 40%(Newell,1989 年)。
本段讨论的大部分研究都使用交通模拟器来观察每个路口交通管制政策变化的影响。我们观察到 SUMO (Behrisch 等人, 2011) 是为此目的最常用的交通模拟器。 SUMO受欢迎的主要原因是它有一个python接口。 Python 是深度学习研究中最常用的语言,因此与 SUMO 的集成非常顺畅。
公平性是 TSC 基于深度学习的解决方案的一个重要因素,以确保交通规划者和政策制定者广泛接受此类解决方案。当考虑到优先车辆时,公平的重要性显著增加。优先车辆包括公共汽车等运输车辆和救护车等紧急交通工具。研究人员试图将公平约束纳入强化学习解决方案的奖励功能中。 Dusparic 等人(2016) 使用经典的(不使用神经网络)强化学习算法并修改了它们的奖励函数,以便在每次优先车辆在交叉路口排队时惩罚信号控制代理。深度学习社区采用了类似的惩罚措施,以证明基于深度学习的强化学习解决方案的公平性。Shabestray 和 Abdulhai (2019) 提出了一种使用 DQN 的多模式信号控制器,并分析了对各种交通方式的影响。与本小节中总结的其他研究不同,这是唯一一篇使用真实数据来校准交通需求的论文。他们使用商用交通模拟器 PARAMICS 对代表加拿大安大略省一个城市繁忙部分的 6 个十字路口的道路网络进行了建模。他们没有特别确定车辆的优先级,而是在他们的奖励功能中使用控制器的基于人的性能。这会自动优先考虑人数较多的车辆,这意味着公共汽车的优先级高于汽车;完全占用的总线比部分占用的总线具有更高的优先级。不利的一面是,当使用这种方法时,像救护车这样的高优先级但人数较少的车辆处于劣势。Wu等人(2020b)使用在 SUMO 中建模的具有多个交叉口的合成网络,并提出了一种基于 LSTM 的 DQN 来为车辆分配优先级,并将行人等待时间纳入其奖励函数中。这种在奖励函数中使用功率度量的概念受到无线网络文献的启发(Kleinrock,2018)。
6.1.2.可变速度限制控制 (VSLC)
与 TSC 类似,VSLC 方法旨在降低即将发生的交通拥堵的严重性。具体目标是最大化网络中的总流量,同时最小化平均行程时间。 VLSC 的强化学习框架的设计类似于 TSC。在这里,VSLC 标志被建模为采取行动的代理。 VSLC 代理允许的行为是在可变信息标牌 (VMS) 上张贴可变速度限制标志。微观交通模拟器用于评估 VSLC 代理所采取行动的效果。但是,TSC 和 VSLC 在现实世界中实现的潜力有很大不同。 VSLC 在现实世界中实施的挑战源于驱动程序可能缺乏合规性。因此,为了确保更高的合规性,在制定基于 VSLC 的解决方案时必须考虑驾驶员的舒适度。相比之下,在基于 TSC 的解决方案中,驾驶员合规性问题不大,因为在实践中,违反交通信号灯的情况远低于违反交通速度的情况(Wu 和 Hsu,2021 年)。此处总结的研究试图在使用深度强化学习模型找到最佳 VSLC 时结合驾驶员舒适度指标。
Gregurić 等人 2020 年)提出了一个基于 CNN 的三层 DQN 模型。他们的奖励函数是三个分量的加权和。第一个组件旨在增加交通流量。第二个组成部分通过对 VMS 发布的速度限制的变化幅度施加限制来确保安全。第三个组件通过最小化 VMS 发布的速度限制中的振荡来确保驾驶舒适性。他们的网络使用 VISSIM 微观交通模拟器进行建模,由 8 公里的高速公路和一个可变信息标志牌 (VMS) 组成。综合需求足以在网络上创建 20 分钟的模拟拥堵。使用他们的 DQN 模型,他们展示了平均速度提高了 13.5%,平均交通密度降低了 25%。Wu等人(2020a)考虑一个未来场景,其中联网和自动驾驶汽车无处不在。在这种情况下,高合规系数允许 VSLC 代理进行更多动态更改。他们通过应用车道特定的可变速度限制,提出了一个差分车速限制模型。他们训练了四种不同的模型以获得不同的奖励:增加流量、减少旅行时间、减少快速加速和减少排放。与以前的工作相比,本研究中使用的交通需求更加现实。该网络代表加利福尼亚州一条 850 米的主要高速公路,所使用的需求是使用该高速公路的可用数据进行校准的。交通方式构成为 85% 的乘用车和 15% 的公共汽车和卡车。与无 VSL 的情况相比,他们的 DVSL 模型平均旅行时间减少了 5.8%。他们使用 SUMO 作为他们的微观交通模拟器,并包含有关如何利用 SUMO 应用程序界面中的不同功能来实现奖励功能的各种组件的具体细节。
小结:我们讨论了深度学习在使用网络级流量控制来限制供应时的应用。我们观察到该领域当前研究状态的两个主要挑战,总结如下:
• 用于这些研究的道路网络的小规模和交通流的同质性对将研究作为部署选项进行验证提出了重大挑战。交通需求是使用数学分布而不是使用真实的交通需求来创建的。这里只有一篇论文使用真实数据来校准他们的需求。其次,DQN 模型的报告性能通常无法与现有的网络控制方法(如固定相变、驱动)进行比较。相反,使用不同神经网络架构的 DQN 之间的比较很常见。除非基于 DQN 的解决方案被证明比现有方法执行得更好,否则此类解决方案的实际部署可能会很困难。
• 另一个方面是缺乏用于管理旅行需求的基于深度学习的解决方案。大多数大规模解决方案由私营部门提供,学术研究受到数据可用性的限制。个人出行数据与其他来源融合时,可以揭示有关旅行者的大量信息,因此公众对共享数据的犹豫是有道理的。我们相信,在研究界广泛采用安全数据管道可能是在共享数据的用户中获得信任的重要一步。物联网 (IOT) 社区已经探索了隐私保护数据融合技术。 Ding 等人(2019)给出了总结。交通研究人员可以从这些来源中汲取灵感,并采用最佳实践来保护隐私。
6.2 用于缓解非重复性拥堵的深度学习
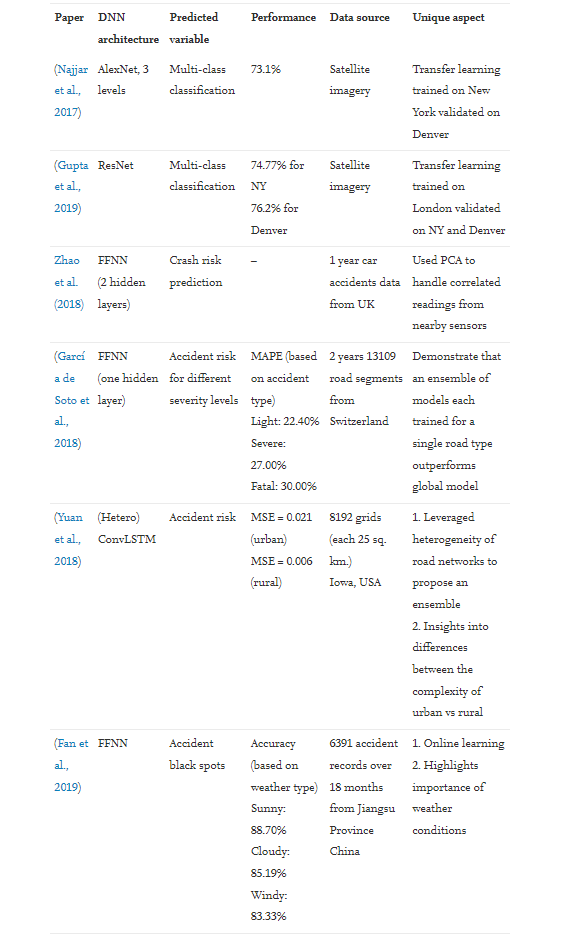
事故是非重复性拥堵的主要原因。因此,对短期事故风险的准确预测使我们能够主动提醒驾驶员注意相同的情况,并可能指示他们降低速度(Ren 等人,2018 年)。最近,深度学习已被广泛用于预测事故风险。为了进行事故风险预测,通常的做法是将研究区域划分为网格,然后预测每个网格中不同时间间隔的事故数量。事故风险预测可以设计为二元预测任务,其中训练深度学习模型来预测每个网格的标签(“高风险”或“低风险”)。它也可以设计为回归任务,训练深度学习模型以预测电网中潜在的事故数量。本小节讨论的论文总结在表 4 中。
展示迁移学习能力 Najjar 等人(2017) 使用卫星图像作为其模型的输入。他们使用类似于 AlexNet(图 2)的模型将事故风险预测为三个级别。 Gupta 等人, 2019, Najjar 等人, 2017 展示了用于事故风险预测任务的迁移学习能力。他们使用来自一个城市的数据训练他们的深度学习模型,并使用训练后的模型来预测不同城市(纽约到丹佛;伦敦到纽约)的事故风险。Gupta等人(2019 年)报告使用在伦敦数据上训练的模型分别预测纽约和丹佛的数据时,准确率分别为 74.77% 和 76.20%。同样,Najjar 等人(2017) 对来自纽约的数据进行了模型训练,并获得了 78.2% 的准确率。然后,他们在使用纽约的模型对丹佛的数据进行预测时报告了可比的性能 (73.1%)。
路网的空间相关性和异质性:路网特征、驾驶员行为和出行需求在空间上存在差异。一方面,这种空间异质性导致深度学习模型的预测性能存在空间差异。另一方面,它提供了利用从位于彼此附近的传感器收集的数据之间的高度相关性的机会。
Zhao 等人(2018)对交通和事故数据应用主成分分析 (PCA),然后使用具有两个隐藏层的前馈神经网络来预测碰撞风险。他们的数据基于英国一年的车祸记录。 PCA 用于识别数据集中不相关的组件。作者提倡使用 PCA,因为在运输数据集中,许多相关的传感器和车辆产生的数据在一定程度上是相关的。他们的实验结果表明,与不使用 PCA 相比,使用 PCA 时碰撞风险预测的准确性略有提高(1%)。
García de Soto等人(2018) 使用具有一个隐藏层的 FFNN 来预测事故风险。他们定义了三个级别的事故严重性,并预测了三个级别中每个级别的风险。他们的数据集基于来自瑞士 13109 个路段的 2 年交通和事故数据。每次事故的数据都被编码成 10 个特征并用作输入。他们的敏感性分析表明,如果针对不同的道路类型(例如高速公路和隧道)训练不同的 FFNN,则平均性能优于对整个网络使用单个 FFNN,道路类型作为输入之一。
Yuan 等人(2018)提出了 Hetero-ConvLSTM,顾名思义,它是 ConvLSTM (Xingjian 等人, 2015) 架构的扩展。作者承认道路网络的异构特征,因此,与以前的工作相比,利用它来产生更好的性能。他们为城市的不同部分训练不同的神经网络,然后创建一个集合来预测全市范围的事故风险。他们报告城市道路的 MSE 为 0.021,农村道路的 MSE 为 0.006。作为比较,LSTM 模型在农村和城市道路上分别达到了 0.187 和 0.042。他们的数据集由 8192 个网格组成,每个网格的面积为 5×5 25 平方公里。它包含来自美国爱荷华州各种来源(天气、交通、事故、卫星)的 8 年数据。其他研究已经考虑到空间异质性问题。一些例子是 Huang 等人(2019),他提出了一个分层融合网络来处理数据的时间和空间异质性,以及 Zhou 等人(2019),他们使用注意力模型优先加权网络相似性因素来预测每小时崩溃风险。 Gupta等人(2019) 使用注意力模型来处理空间异质性,并使用来自伦敦的交通数据报告准确率为 86.21%。
在线学习:Fan等人(2019) 提出了一种在线 FC 深度学习模型来预测事故黑点。他们报告了三种不同天气类型的准确率,即晴天、阴天和大风天的准确率分别为 88.70%、85.19% 和 83.33%。
表 4 总结了第 6.2 节(深度学习缓解非重复性拥堵)中讨论的论文。
6.3 非重复性和重复性拥堵缓解之间的潜在联系
“事故导致拥堵”的说法是直观且无可争议的,但反向因果关系尚未以普遍方式建立。 Retallack 和 Ostendorf (2019) 详细总结了当前对交通拥堵与事故之间关系的理解。他们报告说,研究人员在这个问题上远未达成共识,基于不同类型道路和不同研究国家的研究报告相互矛盾。然而,他们发现拥堵水平和事故之间的 U 形曲线似乎是最近工作中的常见观察结果,该工作使用了足够多的数据点(图 9)。 U 形曲线意味着非常高和非常低的交通密度水平会导致更多的事故。如果 U 形曲线可以在未来的研究中重现,这将对减少事故和拥堵的尝试产生深远的影响。如图 9 所示,这意味着减少事故的努力也会将拥堵减少到最大交通流量的水平(Pasidis,2019 年)。除了事故数量外,另一个需要考虑的重要因素是事故的严重程度。确定事故严重程度背后的因果关系是道路安全研究的主题,不在本次调查的范围内。感兴趣的读者可以参考(Wang 等人 ,2013)。
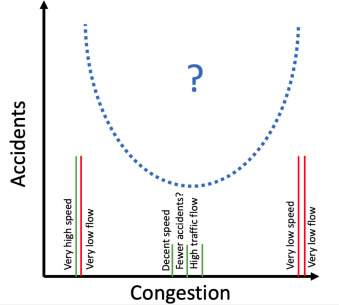
图 9. 事故与拥堵之间的假设 U 形曲线。在最近的研究中已经观察到了这样的曲线。
7 挑战和未来方向
7.1 挑战
在本节中,我们总结了在为本调查编写研究论文时明显的挑战。这些挑战已在特定部分的小结中详细讨论。
7.1.1 识别最先进的模型
为了建立最先进的模型,应该对相关工作进行公平的比较。可以通过一次仅使用一个参数比较性能来确保公平——同时保持所有其他参数不变。确保这种公平性在任何研究领域都是一项具有挑战性的任务。在这里,我们讨论了本调查中讨论的预测任务所特有的挑战。
1.基于不同流量变量的不同拥堵定义:如第 2.3 节所述,可以使用不同的流量变量来定义拥堵。由于这些变量之间缺乏统一的关系,变量选择的这种差异使得报告的预测性能之间的比较变得困难。
2.同一流量变量的不同量化:即使两篇研究论文使用相同的流量变量来定义拥堵,它们的量化也可能不同。例如,如果拥堵是根据速度定义的,一篇论文可能会呈现一个二元预测任务('jam' 或 'no jam'),而另一篇论文可能会呈现一个多级变量('low traffic'、'heavy traffic ','完全堵塞')。如果数据集是固定的,二元预测任务通常比多类预测任务更容易解决 (Allwein 等人, 2000)。
3.不同国家的数据分辨率不同:来自不同国家的研究人员可能从事相同的预测任务,但由于数据分辨率的差异,比较他们的性能水平可能是不公平的。这种分辨率差异可归因于数据收集所需的基础设施。从发达国家道路上的静态传感器收集的数据在空间和时间上可能具有更高的分辨率。数据分辨率的差异意味着手头预测任务的复杂性不同。数据分辨率的提高是否会使预测任务变得更容易或更困难,这是一个有趣的问题。这种预测任务相对难度的差异可以通过一个例子来更好地解释。让我们考虑两名研究人员 A 和 B 试图预测接下来 5 分钟的交通速度。 A 可以以 5 s 的分辨率访问历史交通速度数据,而 B 可以以 1 s 的分辨率访问历史交通速度数据。现在,如果 A 和 B 都尝试以 5 秒的分辨率预测交通速度,那么 B 的任务比 A 更容易——因为 B 有更多信息用于同一任务。然而,如果 A 和 B 都试图以与其输入数据相同的分辨率(A:5 s;B:1 s)来预测交通速度,那么评论谁的任务更容易变得具有挑战性。需要注意的是,一些数据源显著减少了数据分辨率差异的问题。使用分布式传感器收集的数据(例如 GPS 数据)在不同国家/地区具有相似的分辨率。 Ma 等人(2015 年)已经对预测任务的相对难度的这种差异进行了实证研究。
4.不同长度的预测范围:不同长度的预测范围导致预测任务的复杂程度不同。如 Yu 等人(2017)所述,当预测范围的长度增加时,大多数模型的性能都会下降。随着预测范围的增加,这种性能下降是整个研究的共同发现(Wang 等人,2016 年,Di 等人,2019 年)。我们想强调一个明显的事实,即预测范围的长度和预测任务的有用性成反比。
5.用于衡量绩效的不同指标:在比较不同的研究时,选择不同的绩效指标会带来困难。使用一个指标展示卓越的模型性能并不一定意味着使用其他一些指标时的卓越性能。拥堵预测任务是不平衡数据集的示例,因此分类任务最常见的指标(例如准确性)通常具有误导性。在这种情况下,只有在与携带补充信息(例如,误报率)的其他指标一起报告时,准确性才有意义。 Sokolova 和 Lapalme (2009) 对分类任务的指标选择进行了系统研究。
6.交通流异质性的差异:由于不同类型车辆的混合和驾驶行为的高度差异,交通流异质性在发展中国家很常见。相应地,当深度学习模型用于发展中国家的拥堵相关任务时,我们观察到模型性能的系统性下降。我们观察到这种趋势在每个拥堵检测、预测和缓解部分都是有效的。
最近尝试在各个领域定义和维护最先进的技术是 https://paperswithcode.com/sota。他们的网站为不同领域的不同任务提供排行榜,包括流量预测领域。这个门户在机器学习社区中逐渐流行起来。
7.1.2 缺乏在线学习
在线学习(通常称为持续学习)是指随着新数据的到来而更新模型的过程。在没有在线学习的情况下,研究人员会在尝试对系统的行为进行建模之前收集所有数据。然后,他们将数据点分成三部分——训练、验证和测试。该模型使用训练数据进行训练。为了调整超参数(例如神经网络中的层数),模型性能在验证数据上进行评估。最后,在整个训练过程完成后,在测试数据上评估模型性能。如果验证数据和测试数据的模型性能相似,则该模型可以很好地泛化。上述方法似乎符合机器学习的标准做法。然而,一个重要的警告是,原则上,测试数据的标签不仅对模型而且对建模者都是不可见的。当建模者事先可以获得测试数据时,需要格外小心以确保不会发生任何形式的目标泄漏。 Wujek 等人(2016) 总结了避免任何无意目标泄漏的最佳实践。
在线学习完全解决了这一挑战。此外,在线学习帮助我们更紧密地模拟现实世界的场景。在流量预测模型的实际部署中,测试数据只有在解决方案部署后才可用。但是,我们找不到很多使用具有在线学习能力的模型的研究论文示例。这可能是由于实时交通数据被转发给研究人员的安全和隐私问题。
7.2 结论和未来的研究方向
本小节强调了未来研究的可能方向。提出这些方向是为了应对上一小节中提出的挑战。在这里,我们强调了数据标准化的重要性、与其他工作领域的潜在协同作用以及基于模拟和深度学习方法在交通预测任务中的潜在协同作用。
7.2.1.标准化数据集和竞赛
深度学习的成功是优质数据如何改变工作领域的一个例子——最著名的例子是计算机视觉 (CV)。 CV 是指与从图像中提取信息有关的任务的总称。特定 CV 任务的一些示例是对象定位、图像分类和面部识别。考虑到一些限制,深度学习方法在 CV 任务上已经达到了接近人类的性能水平。 CV 研究的两个最大推动力是 ImageNet (Deng 等人, 2009) 数据集的发布及其在 Pascal 视觉对象识别中的使用 (Everingham 等人, 2010)。人们注意到,已经存在了几十年的深度神经网络在 ImageNet 上训练时开始表现得非常好。
对于交通拥堵预测领域,访问标准化数据集会出现几种新的可能性。首先,深度学习模型的性能随着优质数据量的增加而提高。其次,对公共数据库的访问可以让从业者以明确的方式建立最先进的技术。第三,它可以为迁移学习开辟道路,在这种情况下,在庞大的交通数据集上训练的深度神经网络可以很容易地应用于可能无法获得交通数据的新城市(Tan 等人, 2018)。除此之外,标准化还解决了上一小节中提到的训练-验证-测试拆分问题,因为参与比赛的个人看不到测试数据。
交通预测数据标准化的一些独家成就有(Snyder 和 Do,2019 年),(Wang 等人,2018 年,Cheng 等人,2018 年,Moosavi 等人,2019 年)。在“蒙特利尔理工学院智能交通和道路安全研究”网站上维护了最新的公开交通数据来源列表,但视频和图像构成了列表的大部分。流量预测任务在机器学习大会的竞赛赛道上也越来越受欢迎。最近的一些例子是 2020 年 NIPS 的 traffic4cast 比赛和 2020 年 CVPR 的 Night-owls 比赛。
7.2.2 其他领域的类似预测任务
使用机器学习进行互联网流量分类的论文在无线网络社区中已经流行了很长时间。无线网络中的一些预测任务类似于流量预测。来自无线网络领域的调查论文可能为交通研究人员提供了宝贵的想法。相关调查的一些例子包括(Mao 等人, 2018, Zhang 等人, 2019b, Nguyen and Armitage, 2008)。路由协议是交通网络中交通信号控制策略的对应物。因此,无协议无线路由类似于自适应信号控制。 Tang 等人(2017)讨论了使无线网络摆脱(固定)协议的问题。 Yu等人(2019)研究使用深度强化学习来处理无线网络中的异构性。类似地,无线网络的拥堵感知路由(Chen 等人, 2007)是交通中的拥堵缓解算法的对应物。天气预报是预测任务和数据集类似于交通的另一个领域。一个经典的例子是(Xingjian 等人, 2015),促使其在流量方面的大量应用(Wang 等人, 2020a)。
7.2.3 模型驱动和基于深度学习的方法之间的协同作用
深度神经网络具有很高的预测能力,与校准交通模拟器相比,可以更快、更轻松地进行训练。深度学习模型缺乏可解释性。当这两种方法结合使用时,深度学习研究人员可以利用交通模拟器固有的可解释性。这种协同作用已经在基于深度强化学习的交通信号控制方法中得到探索。一些研究人员使用微观交通模拟器来生成拥堵标签数据,从而解决类别不平衡问题。需要在这两种方法之间产生协同作用的方向上做出更多努力。
其他
这项工作是新加坡-ETH 中心 (SEC) 未来弹性系统项目的成果,该项目由新加坡总理办公室国家研究基金会在其卓越研究和科技企业 (CREATE) 计划下提供支持。


