
摘要
人在环路是通过整合人类的知识和经验,以最小的代价训练出准确的预测模型。借助基于机器的方法,人类可以为机器学习应用提供训练数据,直接完成一些流水线中计算机难以完成的任务。在本文中,我们从数据的角度对现有的关于人在环路的研究进行了综述,并将其分为三大类: (1) 通过数据处理提高模型性能的工作,(2) 通过干预模型训练提高模型性能的工作,(3) 系统独立的人在环路的设计。通过以上分类,我们总结了该领域的主要方法,以及它们的技术优势/弱点,并在自然语言处理、计算机视觉等方面进行了简单的分类和讨论。此外,我们提供了一些开放的挑战和机会。本综述旨在为人在环路提供一个高层次的总结,并激发感兴趣的读者考虑设计有效的人在环路解决方案的方法。
https://arxiv.org/abs/2108.00941
引言
深度学习是人工智能的前沿,旨在更接近其主要目标——人工智能。深度学习已经在广泛的应用中取得了巨大的成功,如自然语言处理、语音识别、医疗应用、计算机视觉和智能交通系统[1,2,3,4]。深度学习的巨大成功归功于更大的模型[5]。这些模型的规模包含了数亿个参数。这些数以亿计的参数允许模型有更多的自由度,足以令人惊叹的描述能力。
但是,大量的参数需要大量的标签[6]的训练数据。通过数据标注提高模型性能有两个关键的挑战。一方面,数据增长速度远远落后于模型参数的增长速度,数据增长主要阻碍了模型的进一步发展。另一方面,新任务的出现远远超过了数据更新的速度,对所有样本进行注释非常费力。为了应对这一挑战,许多研究人员通过生成样本来构建新的数据集,从而加快了模型迭代,降低了数据标注的成本[7,8,9,10,11]。此外,许多研究人员使用预训练方法和迁移学习来解决这一挑战[12,13,14,15,16],如transformer[17,18]、BERT[19]和GPT[20]。这些工作取得了令人难以置信的成果。
然而,生成的数据仅用作初始化模型的基础数据。为了获得高精度的可用模型,往往需要对具体数据进行标注和更新。因此,一些基于弱监督的工作被提出[21,22,23,24]。一些研究人员提出使用少样本来促使模型从更少的样本中学习[25,26,27]。在学习框架中集成先验知识是处理稀疏数据的有效手段,因为学习者不需要从数据本身[28]中归纳知识。越来越多的研究人员开始尝试将训练前的知识纳入他们的学习框架[29,30,31,32]。作为代理,人类有着丰富的先验知识。如果机器可以学习人类的智慧和知识,它将有助于处理稀疏数据。特别是在临床诊断和训练数据缺乏等医学领域[33,34,35,36]。
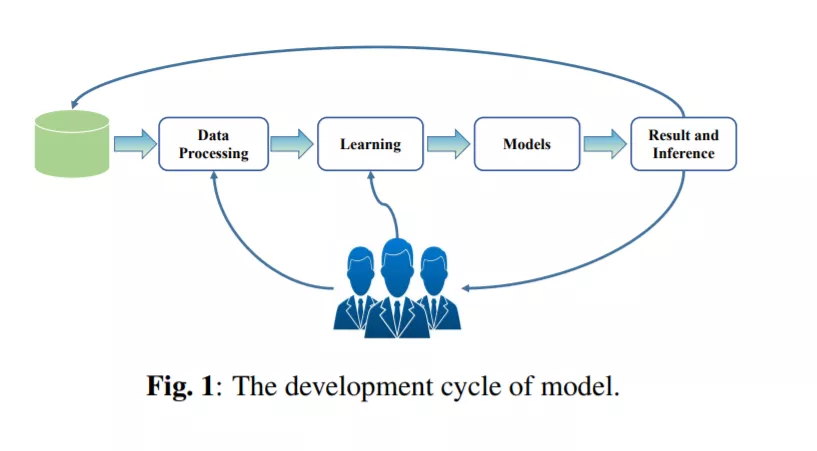
一些研究人员提出了一种名为“人在环路”(human-in- loop, HITL)的方法来解决这一挑战,该方法主要通过将人类知识纳入建模过程[37]来解决这些问题。如图1所示,human-in-the-loop(即“human-in-the-loop”和“machine learning”)是机器学习领域一个活跃的研究课题,近十年来发表了大量的论文。
如图2所示,传统的机器学习算法一般由[38]三部分组成。第一个是数据预处理,第二个是数据建模,最后一个是开发人员修改现有流程以提高性能。我们都知道,机器学习模型的性能和结果是不可预测的,这就导致了很大程度的不确定性,在人机交互的哪个部分能带来最好的学习效果。不同的研究者关注的是人工干预的不同部分。本文根据机器学习的处理方法对这些方法进行分类,分为数据预处理阶段和模型修改和训练阶段。此外,更多的研究集中在独立系统的设计上,以帮助完成模型的改进。因此,在本文中,我们首先从数据处理的角度讨论了提高模型性能的工作。接下来,我们讨论了通过干预模式训练提高模型性能的工作。最后,讨论了独立于系统的“人在环路”的设计。
