NIPS 2018 | MIT等提出NS-VQA:结合深度学习与符号推理的视觉问答
选自arXiv
作者:Kexin Yi、Jiajun Wu、Chuang Gan、Antonio Torralba、Pushmeet Kohli、Joshua B. Tenenbaum
机器之心编译
参与:panda
视觉问答是人工智能领域的一大重要研究问题,可帮助开发能遵照人类口语指令执行任务的程序或机器人等应用。MIT、哈佛等机构合作的一项研究提出了一种神经符号视觉问答(NS-VQA)系统,将深度表征学习与符号程序执行结合到了一起。该研究的论文已被 NIPS 2018 接收。
论文地址:https://arxiv.org/pdf/1810.02338.pdf

我们将两种强大的技术思想结合到了一起:用于视觉识别和语言理解的深度表征学习,以及用于推理的符号程序执行。我们的神经符号视觉问答(NS-VQA)系统首先会根据图像恢复一个结构化的场景表征,并会根据问题恢复一个程序轨迹。然后它会在这个场景表征上执行该程序以得到答案。将符号结构整合成先验知识具有三大独特的好处。第一,在符号空间上执行程序对长程序轨迹而言更加稳健;我们的模型可以更好地解决复杂的推理任务,能在 CLEVR 数据集上达到 99.8% 的准确度。第二,这样的模型在数据和内存上更加高效:在少量训练数据上学习之后能取得优良的表现;它还能将图像编码成紧凑的表征,所需的存储空间会比现有的离线问答方法更少。第三,符号程序执行能为推理过程提供完整的透明度;因此我们能够实现对每个执行步骤的解读和诊断。
引言
对于图 1 中的图像和问题,我们可以立即识别出其中的物体和它们的属性,解析复杂的问题,并利用这样的知识来推理和回答这些问题。我们也能清楚地解释我们推理得到这些答案的方式。现在请想象你正站在这些场景前,闭着眼睛,只能通过触摸的方式构建你的场景表征。毫不意外,没有视觉的推理依然毫不费力。对于人类而言,推理是完全可解释的,而且并不一定涉及视觉感知。

图 1:人类推理是可解读和可解耦的:我们首先会通过视觉感知获取抽象的场景知识,然后会在此之上执行逻辑推理。这能够在丰富的视觉背景中实现组分式的、准确的和可泛化的推理。
深度表征学习的进步和大规模数据集的发展 [Malinowski and Fritz, 2014, Antol et al., 2015] 催生了很多用于视觉问答(VQA)的开创性方法,这些方法大都是以端到端的方式训练的 [Yang et al., 2016]。但是,创新的完全基于神经网络的方法往往在高难度的推理任务上表现不佳。尤其值得一提的是,一项近期研究 [Johnson et al., 2017a] 设计了一个新的 VQA 数据集 CLEVR,其中每张图像都带有由程序生成的复杂多变的组分式问题,该研究也表明之前最佳的 VQA 模型的表现并不好。
之后,Johnson et al. [2017b] 表明可以通过将预先的人类语言知识连接进来作为程序,从而帮助机器学习推理。具体而言,他们的模型集成了一个程序生成器,其可推理一个问题的底层程序和一个学习后的基于注意的执行器,该执行器可在输入图像上运行这个程序。
这样的组合能在 CLEVR 数据集上实现非常好的表现,而且能够足够好地泛化用于 CLEVR-Humans——这个数据集包含与 CLEVR 一样的图像但搭配的问题是人类提出的。但是,他们的模型仍然有两个局限:第一,训练程序生成器需要很多有标注的示例;第二,基于注意的神经执行器的行为难以解释。相对而言,即使仅有少量有标签的实例,我们人类也可以在 CLEVR 和 CLEVR-Humans 上执行推理,而且我们也能清楚地解释我们的推理方式。
在这篇论文中,我们在学习 vs. 建模方面更进了一步,提出了一种用于视觉问答的神经符号方法(NS-VQA),该方法完全将视觉及语言的理解和推理分开了。我们使用神经网络作为解析工具——根据图像推断结构化的基于目标的场景表征,根据问题生成程序。然后我们集成一个符号程序执行器作为神经解析器的补充,这个执行器可在场景表征上运行生成的程序以得到答案。
深度认知模块和符号程序执行器的组合具有三大独特的优势。第一,符号表征的使用能提供对长的复杂程序轨迹的稳健性。它还能减少对训练数据的需求。在 CLEVR 数据集上,我们的方法在有 270 个程序标注加 4000 张图像的问题上进行了训练,能够实现高达 99.8% 的接近完美的准确度。
第二,我们的推理模块和视觉场景表征都是轻量级的,仅需要最少量的计算和内存成本。尤其值得一提的是,我们的紧凑型结构化图像表征在推理过程中所需的存储空间要少得多,相比于其它当前最佳的算法,内存成本能降低 99%。
第三,符号场景表征和程序轨迹的使用能迫使模型准确地基于问题恢复底层的程序。结合完全透明且可解读的符号表征的本质,可以对推理过程进行一步步地分析和诊断。
方法
我们的 NS-VQA 模型有三个组件:场景解析器(去渲染器/de-renderer)、问题解析器(程序生成器)和程序执行器。给定一个图像-问题对,场景解析器会去除图像的渲染效果,得到结构化的场景表征(图 2-I),问题解析器会基于问题生成层次化的程序(图 2-II),程序执行器会在结构化的表征上运行程序从而得到答案(图 2-III)。
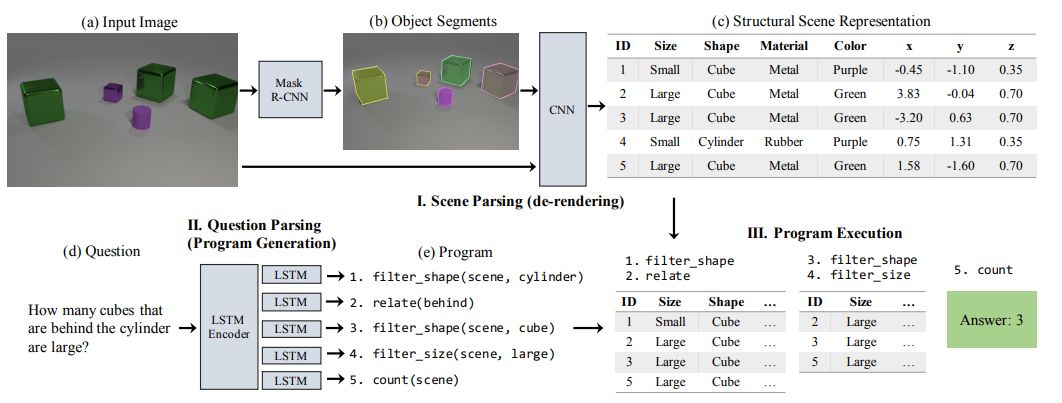
图 2:我们的模型有三个组件:一是场景解析器(去渲染器),它的功能是分割输入图像(a-b)并将其恢复成一个结构化的场景表征(c);二是问题解析器(程序生成器),其可将自然语言的问题(d)转换成程序(e);三是在结构化场景表征上运行程序以得到答案的程序执行器。
我们的场景解析器能够恢复图像中场景的结构化的和解耦的表征(图 2a),基于此我们可以执行完全可解释的符号推理。这个解析器采用了一种两步式的基于分割的方法来进行去渲染:它首先会生成一些分割提议(图 2b);对于每个分割,都会对物体及其属性进行分类。最终得到的结构化的场景表征是解耦的、紧凑的和丰富的(图 2c)。
问题解析器将自然语言的输入问题(图 2d)映射成一个隐含程序(图 2e)。这个程序有层次化的函数模块,其中每个模块都能在场景表征上实现独立操作。使用层次化的程序作为我们的推理骨干能够自然地提供组合性和泛化能力。
程序执行器能够基于问题解析器的输出序列,将这些函数模块应用到输入图像的抽象式场景表征上,从而生成最终答案(图 2-III)。在整个执行过程中,这个可执行的程序会在其输入上执行单纯的符号运算,而且其在程序序列方面是完全确定性的、解耦的和可解释的。
评估
研究表明我们的解耦的结构化场景表征和符号执行引擎具有以下优势。首先,我们的模型可以基于少量训练数据进行学习,并且其表现也优于当前最佳的方法,同时还能准确地恢复隐含程序。第二,我们的模型能够很好地泛化用于其它问题类型、属性组合和视觉环境。
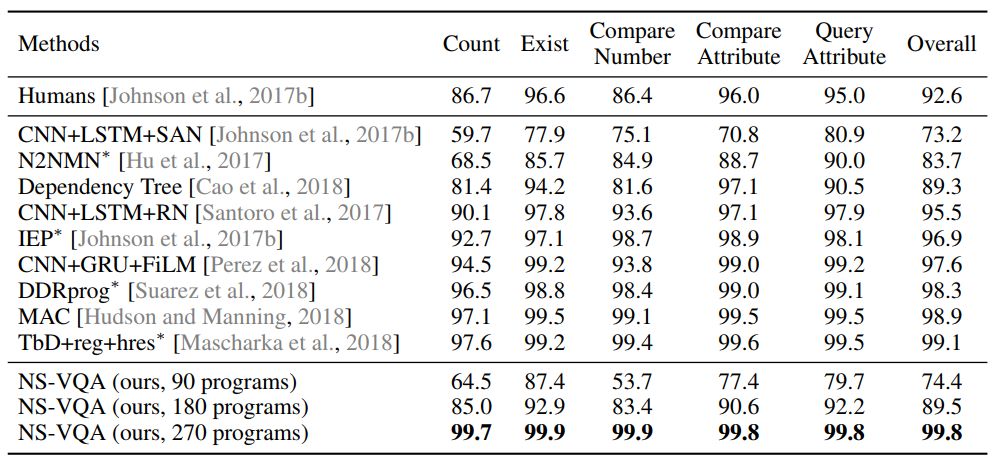
表 1:我们的模型(NS-VQA)在 CLEVR 上的表现优于当前最佳的方法并且达到了接近完美的问答准确度。用于预训练我们的模型的问题-程序对是从该数据集的 90 个问题系列中均匀选取的:90、180、270 programs 分别对应于从每个问题系列取 1、2、3 个样本。(*):在所有程序标注上训练得到(700K)。

图 3:在 CLEVR 上的定性分析结果。蓝色表示正确的程序模块和答案;红色表示错误的。相比于 IEP 基准,我们的模型能够稳健地恢复正确的程序。
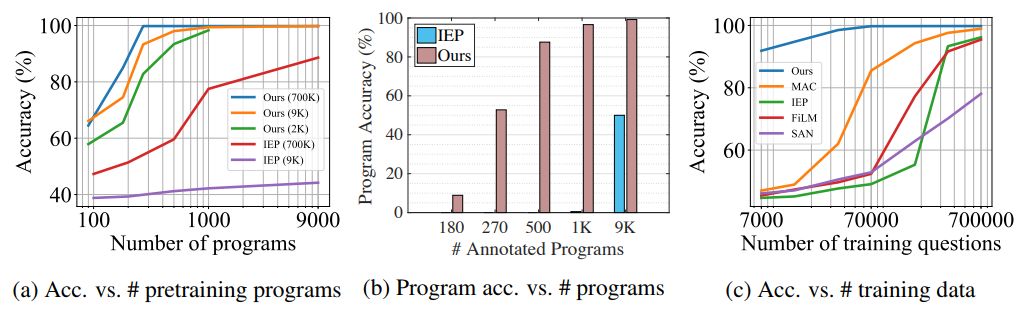
图 4:我们的模型表现出了很高的数据效率,同时也实现了当前最佳的表现并保持了可解释性。(a)问答准确度随预训练所用程序数的变化情况;不同的曲线表示 REINFORCE 阶段使用了不同数量的问答对。(c)问答准确度随训练的问答对的总数量的变化情况;我们的模型是在 270 个程序上预训练的。
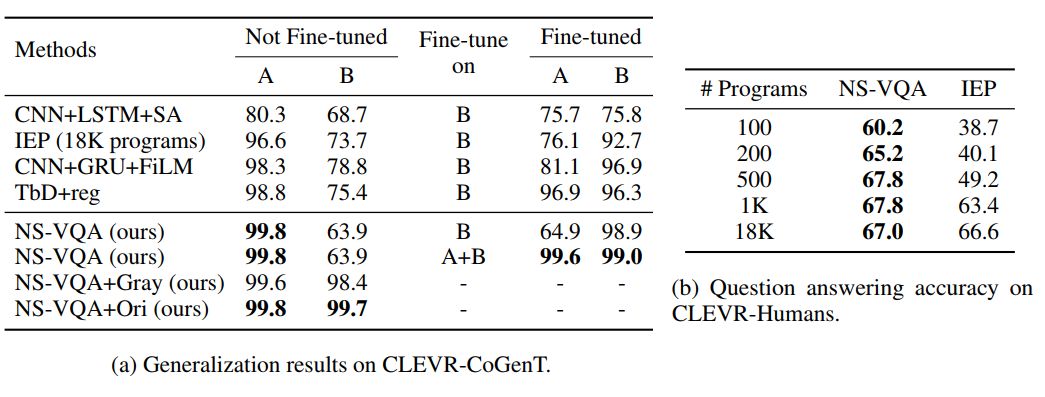
表 2:泛化到未曾见过的属性组合和问题类型。(a)我们的图像解析器在来自分割 A 的 4000 张合成图像上进行了训练,然后在 B 的 1000 张图像上进行了微调。问题解析器仅在 A 上从 500 个程序开始进行了训练。基准方法在来自 B 的 3000 张图像加 30000 个问题上进行了微调。NS-VQA+Gray 在图像解析器中采用了一个灰度通道来进行形状识别,NS-VQA+Ori 使用了一个在来自 CLEVR 的原始图像上训练的图像解析器。(b)在不同的训练条件下,我们的模型在 CLEVR-Humans 上都优于 IEP。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


