![]()
文 | 李威
编 | 杨晓凡
论文标题:GANILLA: Generative Adversarial Networks for Image to Illustration Translation
论文链接:https://arxiv.org/abs/2002.05638
解读作者:李威
本文提出了一种从自然图片到儿童读物插画的风格迁移方法,能够在保持原始图像内容的前提下迁移给定艺术家风格。文章的代码、预训练模型、生成训练数据的脚本均已开源。
GitHub地址:https://github.com/giddyyupp/ganilla
自从 Gatys 等人提出图片风格迁移的开创性工作,越来越多的学者在这方面进行了研究和探索。各种各样的方法被提出,包括配对 (paired) 和未配对 (unpaired) 的风格迁移、基于卷积神经网络 (Convolutional Neural Networks, CNN) 或者生成对抗网络 (Generative Adversarial Networks, GAN) 的方法等等。在迁移内容上也多种多样,如自然图片到艺术画的迁移,将一种动物迁移到另一种动物,变换场景中的各种属性如天气、季节等,将航拍影像转换为地图,将人脸图片变为素描或者卡通图片等等。这篇文章介绍了一种新的风格迁移:自然图片到儿童读物插图的风格迁移。
与艺术画或者卡通图片不同,插图虽然也有诸如高山、人物、玩具、树木等这些常见物体,但其抽象程度更高,现有方法很难在风格和内容之间取得好的平衡。如 CycleGAN[3] 虽然能够迁移艺术家的风格,但是无法成功迁移内容;DualGAN[4] 虽然能够保留输入图片的内容,却无法很好的迁移风格。作者通过试验经验性地验证了当前 state-of-the-art 的未配对风格迁移方法也无法为插图提供令人满意的结果,如下图所示。
![]()
文章的目标是 给定输入自然图片,通过迁移给定插图艺术家的风格,生成能保留原始图片内容、令人满意的插图。
为了解决这个问题,作者采取了未配对的风格迁移方法,其需要两个未配对的独立集合,一个是包含自然图片的源域,另一个是包含插图的目标域。作者以现有的用于插图分类的数据集为基础,将其大小几乎增加了一倍,从而构建了目前最为广泛的插图数据集,该数据集包含363种不同儿童书籍和24个不同艺术家的9448张插图。
为了在风格迁移和内容保留之间取得平衡,作者基于现有 state-of-the-art 的模型,提出了两点改变。
首先,作者提出了一个新的生成器,其对每个残差层的特征图进行下采样。
其次,为了更好地迁移内容,作者提出通过使用跳跃链接 (skip connections) 和上采样来将低级特征和高级特征进行融合。低级特征通常包含像边这样的信息,其有助于生成的图片保留输入图片的结构。
未配对的风格迁移方法的一个主要问题是评价部分,为此作者提出了一种基于图片内容和风格分类器的定量评价框架,并通过实验证明了该框架可以产生合理的结果。
总的来说,文章的贡献主要在三个点:数据集,网络架构 和 评价指标。具体来说:
-
作者构建了一个包含24个艺术家的9500张插图的数据集,其是目前已知的最大的儿童读物插图数据集;
-
作者提出了一种新颖的生成器网络,能够在风格迁移和内容保留两者之间取得较好的平衡;
-
作者提出了一个评价图像生成模型的新框架,能够同时基于内容和风格对生成结果进行定量评价。
GANILLA
在对图像到插图问题的初步实验中,作者观察到当前未配对的图像到图像的翻译模型 (unpaired image-to-image translation models) 如 CycleGAN[3], DualGAN[4], CartoonGAN[5] 等都无法同时迁移风格和内容。为此作者设计了一种新的生成器网络,能够在保留输入图片内容的同时迁移风格。
GANILLA 模型设计细节
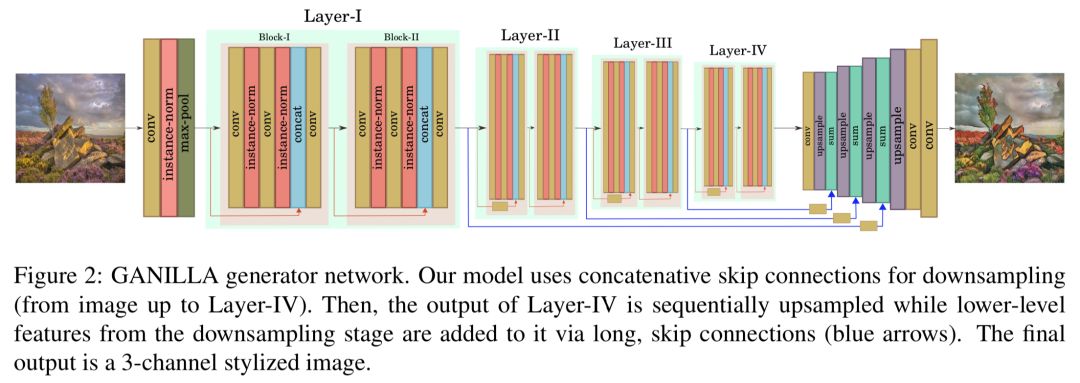
GANILLA 采用低层特征以在迁移风格的同时保留内容,如图2所示,模型包含两个阶段:
-
下采样阶段:下采样阶段是经过修改的 ResNet-18 网络,为了在下采样阶段集成低层特征,作者在下采样的每一层将来自先前各层的特征进行拼接 (concatenate),由于底层网络包含诸如形态学特征 (morphological features)、边缘、形状等信息,因此它们可以确保迁移后的图像含有输入内容的子结构。
-
上采样阶段:在上采样阶段,作者使用下采样阶段每一个网络层的输出,通过长的跳跃连接 (下图2中的蓝色箭头),在进行上采样运算之前将这些低层特征送入求和层 (summation layers),这些连接有助于保留图片内容。
![]()
网络架构
下采样阶段从一个核为 7x7 的卷积层开始,紧跟着实例归一化 (instance norm)、ReLU 和最大池化 (max pooling) 层。然后继续四个网络层,其中每一层包含两个残差块。每个残差块都从一个卷积层开始,后面接着实例归一化和 ReLU 层。然后再是一个卷积层和实例归一化,并将输出和残差块的输入进行拼接。最后再将拼接的张量最后一个卷积和 ReLU 层。作者在除了 Layer-I 以外的其他层使用步长 (stride) 为2的卷积层以将特征图大小减半。残差层中所有卷积层的核均为 3x3 。
上采样阶段包含四个连接的卷积、上采样和求和层。首先Layer-IV的输出通过卷积和上采样层来增加特征图大小,以匹配上一层的特征图尺寸。所有上采样阶段的卷积滤波核的大小为 1x1 。最后再使用一个核为 7x7 的卷积层来输出转换后的三通道图像。
作者使用的判别器网络是 70x70 的 PatchGAN,其由三个卷积块组成,其中每个块包含两个卷积层。作者将第一个卷积块的滤波尺寸设为64,并在后续块将其大小加倍。
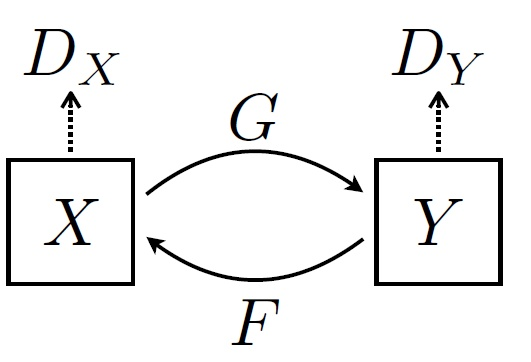
作者遵循 CycleGAN 和 DualGAN 中的循环一致性 (cycle-consistency) 思想来训练 GANILLA 模型,第一组 $(G)$尝试将源图像隐射到目标域,第二组$(F)$将输入图像作为目标域,并尝试以循环的方式生成源图像。
![]()
损失函数
GANILLA 的损失函数包括两个生成器和判别器对的 Minimax 损失和一个循环一致性损失。循环一致性损失试图确保生成的样本可以映射回源域,作者使用 L1 距离用于衡量该损失。当将源域图像提供给生成器$F$时,由于其已经与源域相对应,因此期望他们没有变化。同样当向生成器$G$提供目标域图像时,也会出现类似情况。这一技术首先在 CycleGAN 中被提出,作者也采用了这一方案,使用基于 L1 距离的身份损失 (identity loss)。GANILLA 的最终目标函数便是极小化这四个损失函数之和,具体公式可以参考 CycleGAN 文章。
数据集
GANILLA 不需要配对的图像,而是需要两个不同的图像数据集,分别用于源域和目标域。这里使用自然图像作为源域,将插图图像作为目标域。
在训练阶段,作者使用来自 CycleGAN 训练数据集的5402张自然图像作为源域,并构建了一个新的插图数据集作为目标域。在测试阶段,作者使用 CycleGAN 测试集中的751张图像。对于插图数据集,作者用新图像将[2]中的数据集进行了扩充,这个新的数据集几乎是原来的两倍大小,包含来自363种不同书籍和24个不同艺术家的近9500个插图。为了更好地训练 GAN 模型,作者通过抓取网页和扫描公共图书馆的书籍来收集新的图像,几乎增加了所以插图艺术家的图像数量。作者使用包含10位艺术家的插图数据集来训练网络,插图的作者、数量等信息可以参考下表1,下面图4展示了部分插图。其余14位插画家的作品用于定量评价网络。
![]()
![]()
实现
作者使用 PyTorch 实现 GANILLA 模型,包括自然图像和插图在内的所有训练图像都被调整为$256 \times 256$大小。作者使用学习率为0.0002的Adam优化器训练了200个epochs,所有网络都从头开始训练,即没有ImageNet预训练模型作为初始权重。所有实验均在 Nvidia Tesla V100 GPU 上进行。
与其它模型对比
下面图3展示了文章的生成器网络 GANILLA 的简要架构描述,以及当前的 state-of-the-art 模型和两个对比实验模型。从图中可以看出,使用卷积层进行下采样再使用去卷积层进行上采样是一种常见的策略。除了 DualGAN之外,CycleGAN 和 CartoonGAN 在下采样和下采样层之间还有额外的带有加性连接 (additive connections) 的残差层。在文章的模型中,作者使用带有拼接连接 (concatenative connections) 的残差层,并使用上采样算子代替反卷积层。两个对比模型的目的在于理解下采样和上采样部分低层特征的效果。第一个对比模型将拼接连接替换为加性连接,以观察下采样部分低层特征的重要性。第二个对比模型将 GANILLA 的上采样层替换为 CycleGAN 的上采样层,以测试上采样部分低层特征的有效性。
![]()
实验
作者将 GANILLA 与 CycleGAN、DualGAN 和 CartoonGAN 三种方法进行了对比,三种方法使用的是官方开源的代码实现。作者先提供了定性结果和用户调研的结果。但对 GAN 模型进行定量评价比较困难,因此作者提出了一个新的框架来进行定量评价,其包含两个 CNN,Style-CNN 旨在衡量风格迁移方面的效果,Content-CNN 意在检测输入内容是否得到了保留。
下表2中 GANILLA 和其他模型在参数量和训练时间方面的比较,作者以大小为4的批次运行 CartoonGAN,以批次大小1运行其他三种方法。所有的模型都训练了200个Epochs。
定量评价和人为主观评价
下面图5展示了输入相同的图片,基于不同插图艺术家的风格 GANILLA 生成的结果,虽然对某些艺术家来说生成的图像包含不太明显的缺陷,但大部分图像都能成功捕获目标风格。
![]()
下面图6针对每个插图艺术家,输入相同图片,CartoonGAN、CycleGAN、DualGAN 和本文的 GANILLA 分别生成的结果,只有本文方法能够在保留输入图片内容的前提下成功地迁移了风格。
![]()
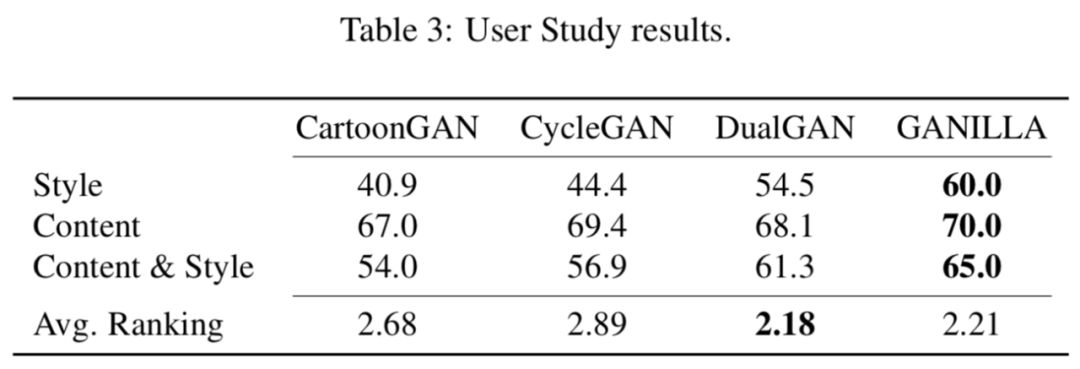
基于视觉的定性分析是主观的, 为了减少主观性的影响,作者进行了一项用户调研,从48个用户收集了66份问卷,下面表3展示了最终的结果。
![]()
在风格和内容方面,GANILLA 似乎是最好的方法。在视觉效果评价排名上,DualGAN 略微超过了 GANILLA,主要原因是 DualGAN 未能成功迁移风格,用户认为这些图像更具有视觉吸引力是因为其结果看起来更自然。
定量分析
为了定量评价风格迁移的质量,作者提出了风格分类器 Style-CNN,从图像中随机裁取 100x100 大小的像素块,将其送入分类器中进行训练。训练集包含11个类别,包含10个插图艺术家和1个自然图像,如果生成的图像缺乏风格,其更有可能被分类为自然图像。下面图8展示了 Style-CNN 的结果。
![]()
为了评估输入内容的保留程度,作者提出了内容分类器 Content-CNN,这里内容被定义为属于特定场景类别,如森林、街道等。作者从 SUN 数据集选取了10个与自然图像数据集中内容接近的户外类别,作为负类,作者使用除了训练集中使用的10个插图艺术家的作品外的所有插图。作者的直觉是,如果能够保留内容,风格化后的自然图像应该仍然具有相同的内容,例如如果以高尔基-保罗风格生成山峰图像,仍然应该能够将其分类为山峰。如果生成的图像失去了与内容的联系,则可以将其归类为插图即负类。图9展示了一些 CycleGAN 和 GANILLA 生成图像的分类结果。
![]()
对照实验
作者还进行了两组对比实验。第一组对比模型将 GANILLA 中的下采样卷积层替换为原始的 ResNet-18,第二组对比模型将 GANILLA 中的上采样卷积层替换为 CycleGAN 和 CartoonGAN 使用的反卷积层。作者定量比较了实验结构,对比模型Model 1内容分与 GANILLA 相近,但是风格得分较低,这表明作者对 ResNet-18 网络的修改有助于输入图像的风格化。对比模型Model 2能够得到更高的风格分,但其内容分较低,这说明在上采样阶段使用低层特征有助于保留输入图像的内容。
![]()
宫崎骏动画风格实验
作者还收集了部分宫崎骏的插图作为训练集进行了实验,下图分别展示了收集的数据集和基于宫崎骏风格的迁移结果。
![]()
![]()
和神经网络风格迁移的对比
作者还将 GANILLA 与 Gatys 等人的神经风格迁移 (Neural Style Transfer, NST) 进行了对比,对于 NST 模型,分别使用一张内容图和一张风格图,如下图结果所示,NST 方法无法就插图数据的风格化得到成功的结果,因为其只使用一张内容图和风格图,最终结果高度依赖输入输入图像。
![]()
模型的限制以及讨论
对于某些插图艺术家的风格来说,GANILLA 也无法得到成功的结果。下图展示了一个示例图像,该作品来自 Seuss 博士,失败的原因主要是该类插图大多是木炭素描 (charcoal drawings) 或包含简单地着色。
![]()
参考
GANILLA: Generative Adversarial Networks for Image to Illustration Translation. Samet Hicsonmeza, Nermin Sametb, Emre Akbasb, Pinar Duygulu. Elsevier, 2020.
Draw: Deep Networks for Recognizing Styles of Artists Who Illustrate Children’s Books. Samet Hicsonmez, Nermin Samet, Fadime Sener, Pinar Duygulu. ACM International Conference on Multimedia Retrieval, 2017.
Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros. ICCV, 2017.
DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. Zili Yi, Hao Zhang, Ping Tan, Minglun Gong. ICCV, 2017.
CartoonGAN: Generative Adversarial Networks for Photo Cartoonization. Yang Chen, Yu-Kun Lai, Yong-Jin Liu. CVPR, 2018.