最新《知识驱动的文本生成》综述论文,44页pdf

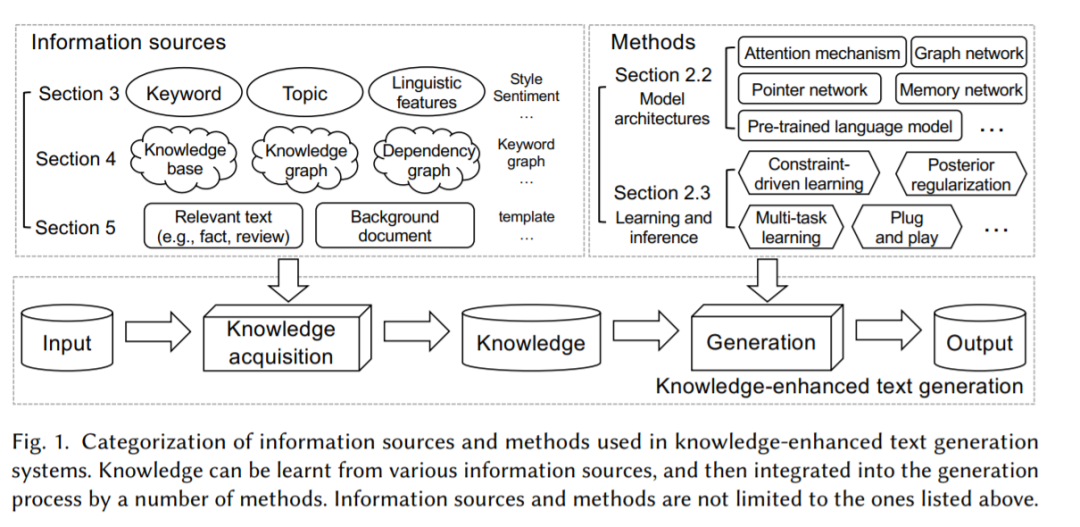
文本生成的目标是让机器用人类语言表达。它是自然语言处理(NLP)中最重要也是最具挑战性的任务之一。自2014年以来,各种由Seq2Seq首创的神经编解码器模型被提出,通过学习将输入文本映射到输出文本来实现这一目标。然而,仅凭输入文本往往无法提供有限的知识来生成所需的输出,因此在许多真实场景中,文本生成的性能仍然远远不能令人满意。为了解决这个问题,研究人员考虑将输入文本之外的各种形式的知识纳入生成模型中。这一研究方向被称为知识增强文本生成。在这项综述中,我们提出了一个全面的综述,在过去的五年里,知识增强文本生成的研究。主要内容包括两部分:(一)将知识集成到文本生成中的一般方法和体系结构;(二)根据不同形式的知识数据的具体技术和应用。这项综述在学术界和工业可以有广泛的受众,研究人员和实践者。
https://arxiv.org/abs/2010.04389
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“KETG” 可以获取《最新《知识驱动的文本生成》综述论文,44页pdf》专知下载链接索引



登录查看更多
相关内容

Arxiv
5+阅读 · 2018年2月3日


相关VIP内容
相关资讯