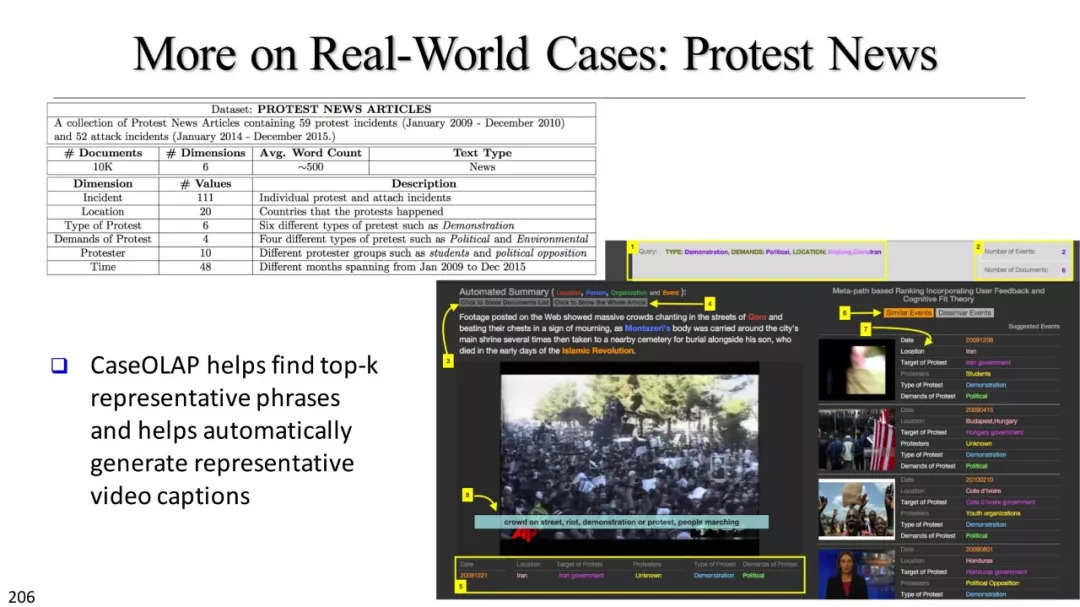
【KDD2018】UIUC韩家炜团队218页文本语料数据挖掘教程
【导读】由于互联网领域的蓬勃发展,人们获取信息的便捷性越来越高,但也面临着信息过载的问题,因此,对自然语言处理的技术需求逐渐增多。本周,我们为大家整理了韩家炜团队最新发布的KDD大会教程:文本语料的多维文本分析,希望帮助大家理解相关问题。
摘要
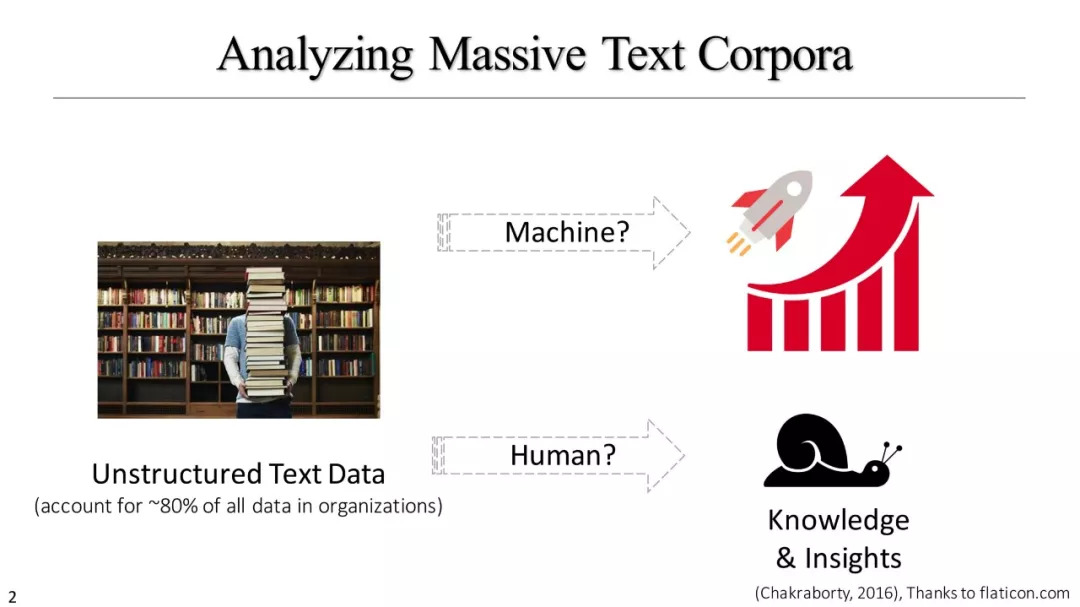
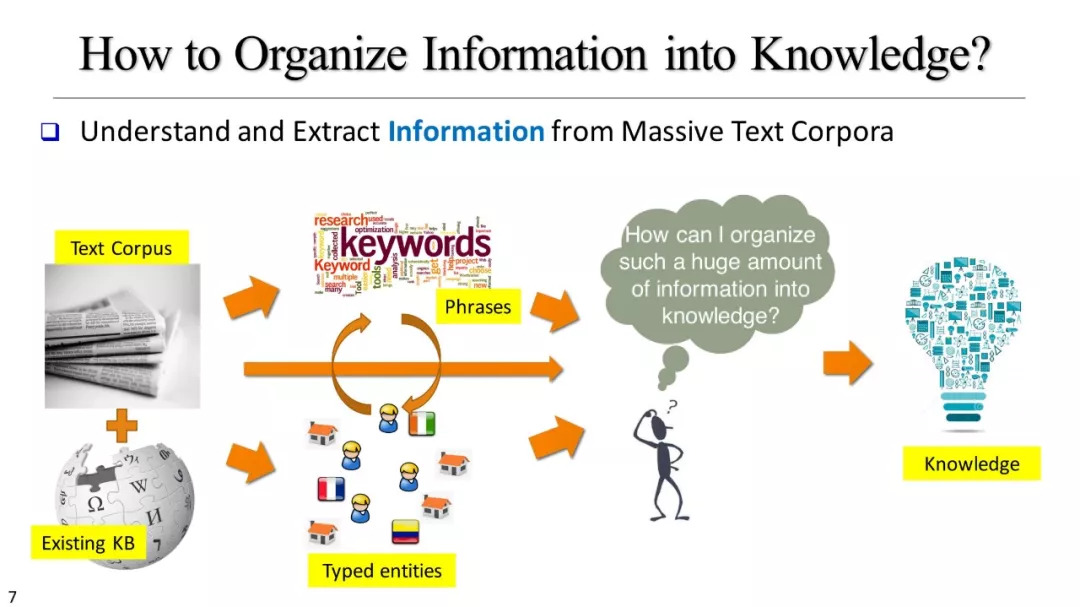
在今天的信息社会中,我们被大量的文本数据包围,从新闻文章和社交媒体,到研究文献、医疗记录和公司报告。数据挖掘研究者面临大一大挑战是,如何设计有效并且具有可扩展特性的方法来挖掘此类庞大的非结构化文本语料库,以发现隐式结构并生成多维的文本异构信息网络,从中可以根据用户的需求生成可操作的知识。
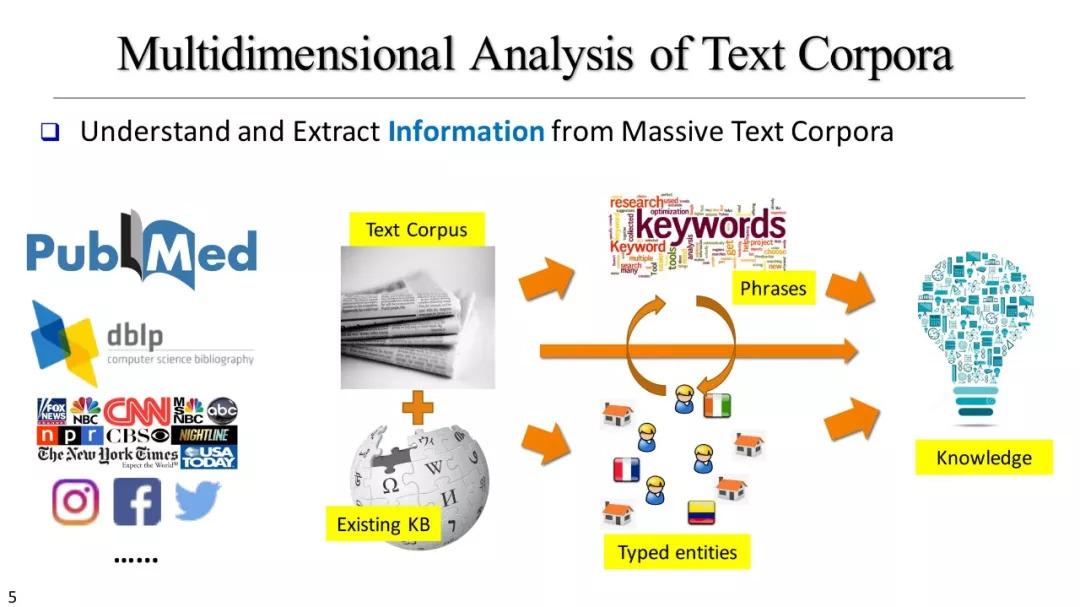
在本教程中,我们介绍了数据驱动的方法,以便从不同类型的文本语料库构建结构化文本多维数据集(特别是对于大规模的,特定领域的文本语料库)。这种文本异构网络可以提供更多结构信息和指导来进一步增强数据挖掘能力。我们专注于弱监督、与领域无关的、语言无关的方法,以便在各类领域可以实现快速的、高质量的文本网络构建。进而,在真实的数据集上示范了,如何在新闻文章、科学出版物、产品评论等信息上,构建文本信息网络以协助对大规模文本语料库进行多维分析。
大纲
介绍
动机和现有技术
多维度分析概述
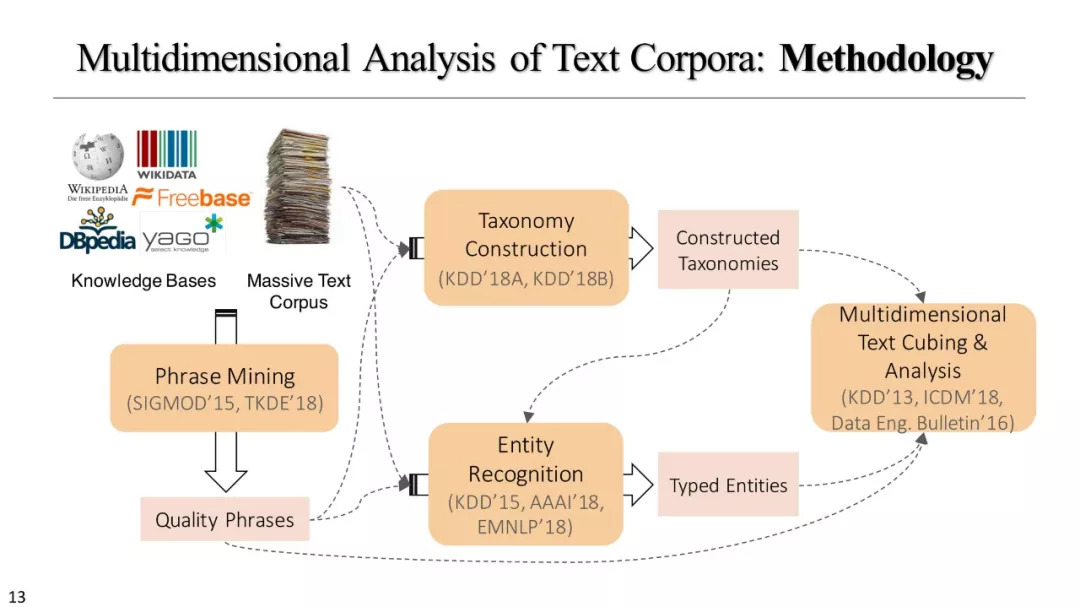
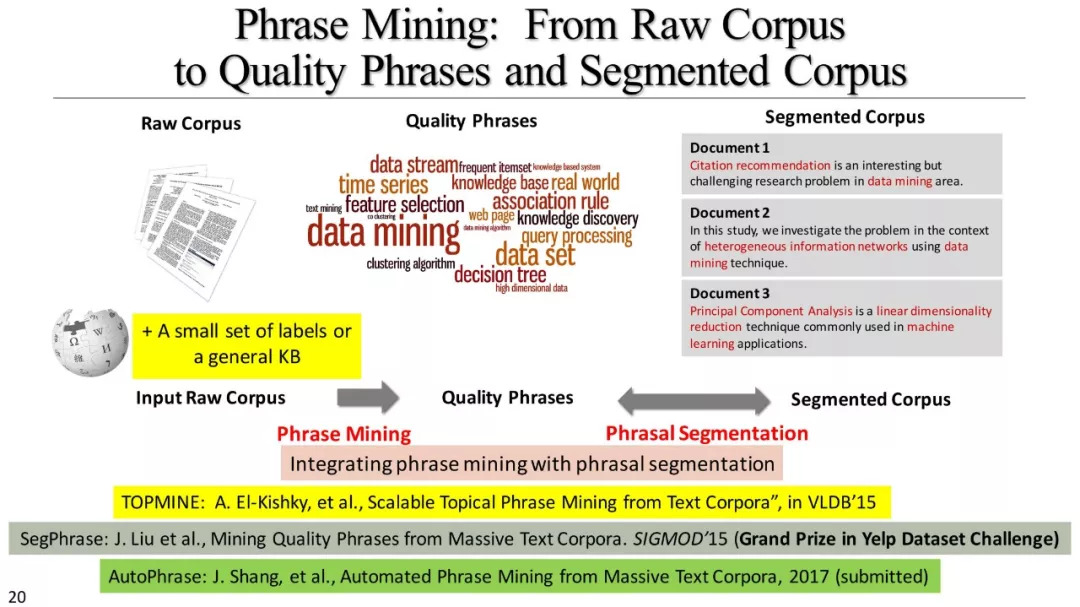
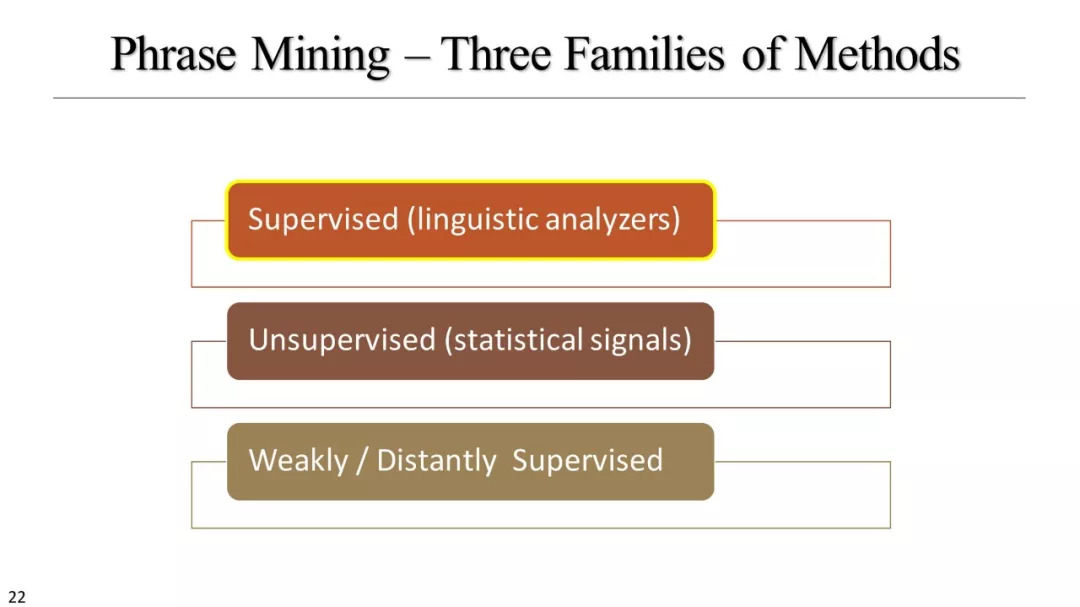
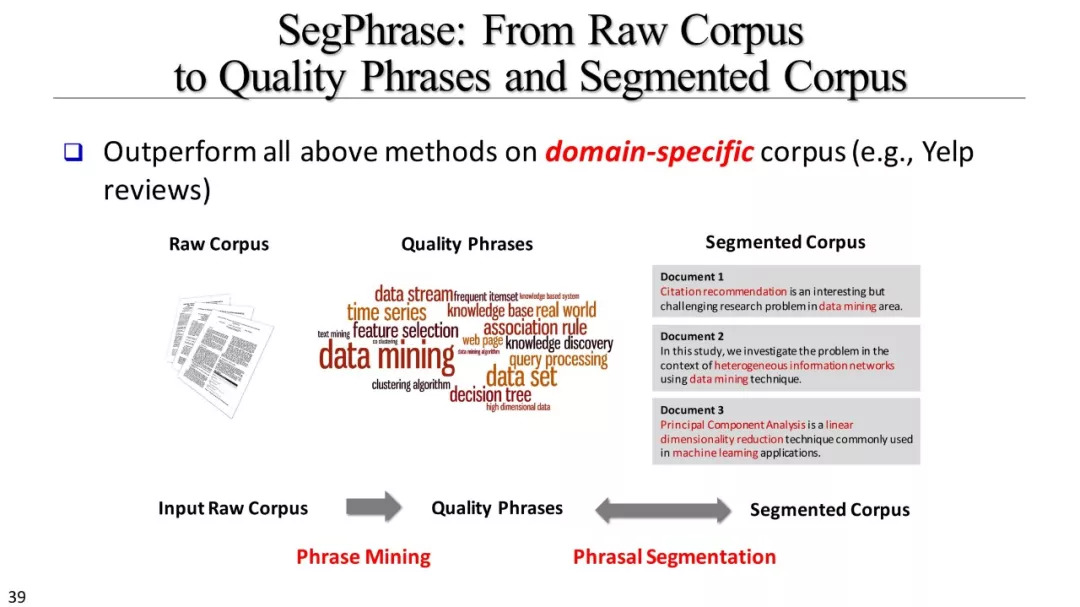
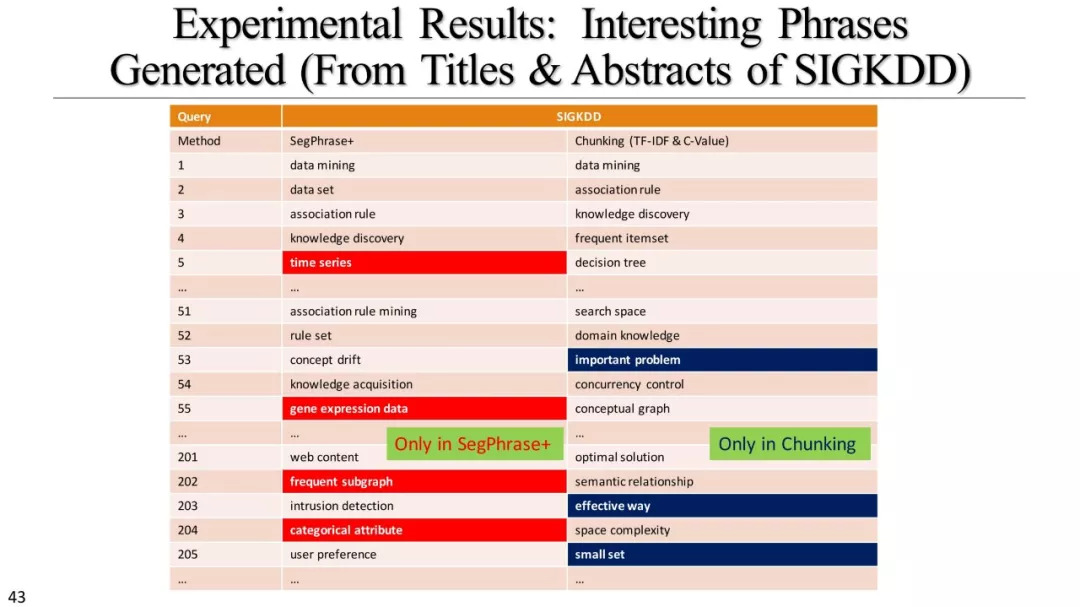
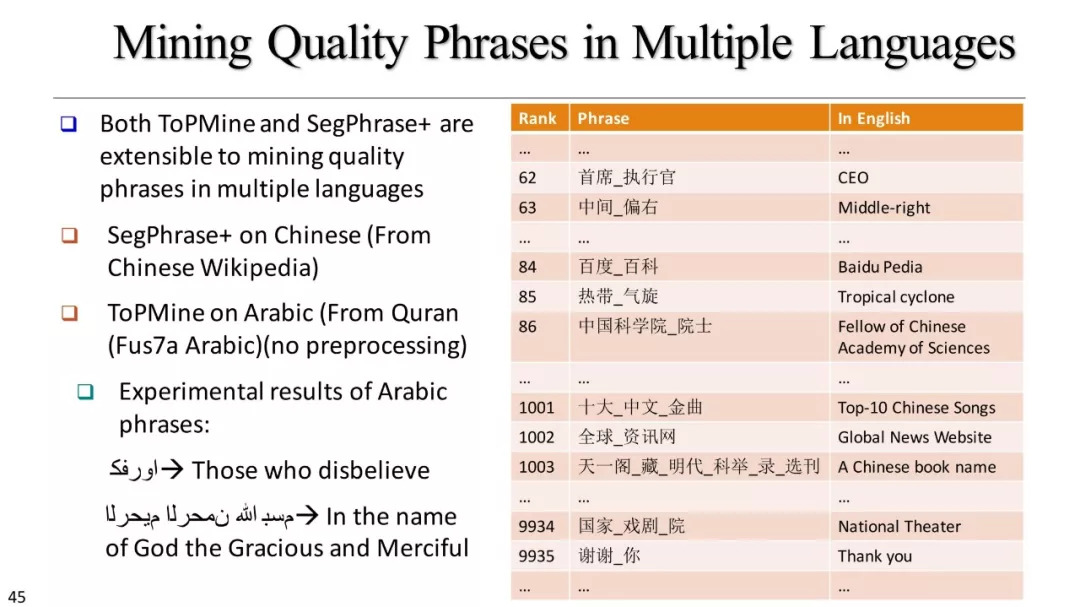
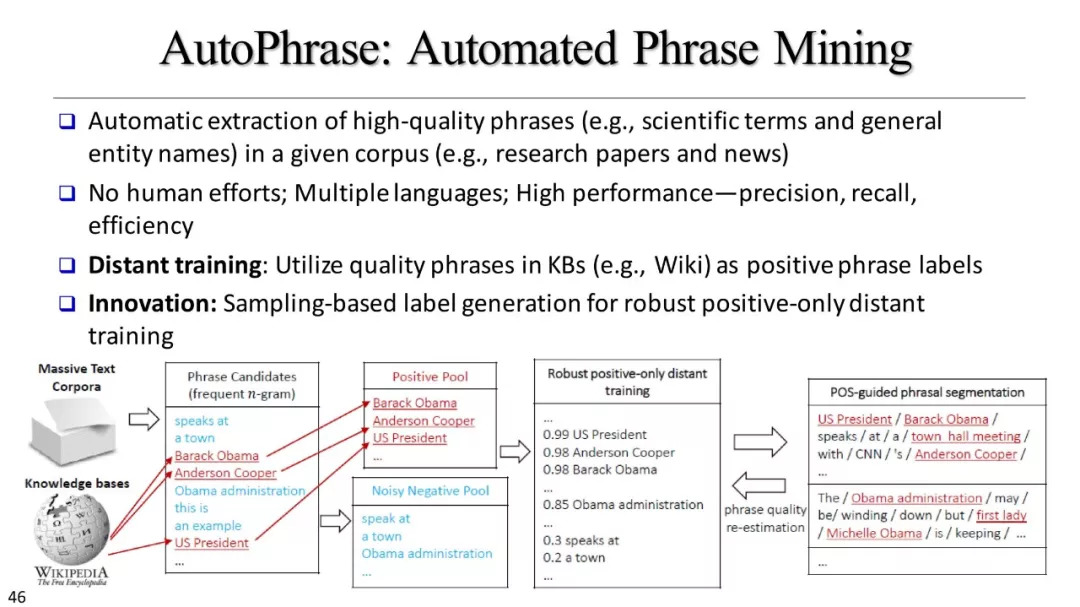
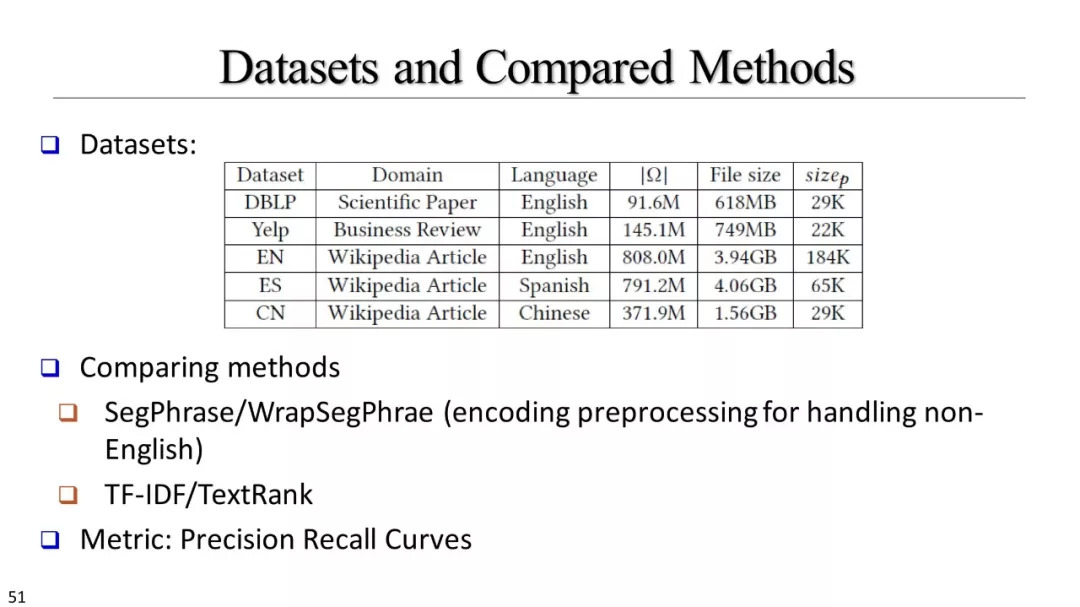
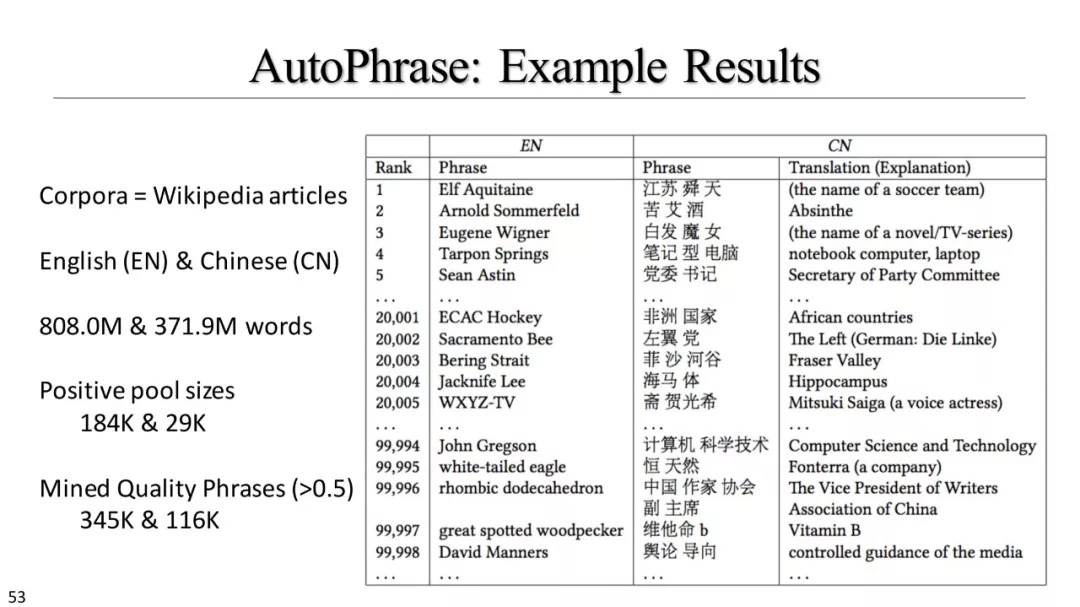
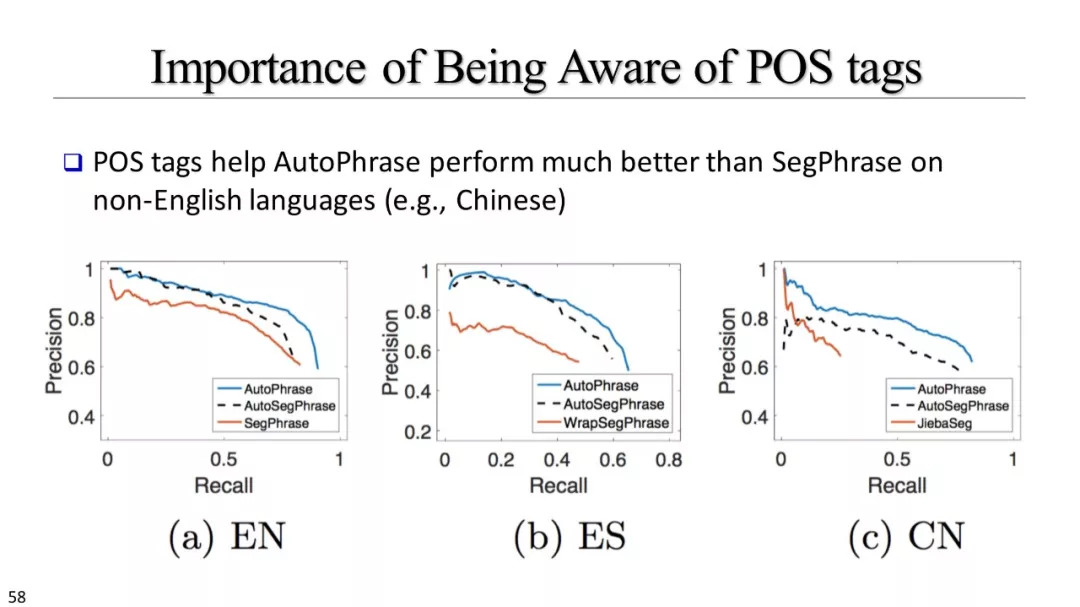
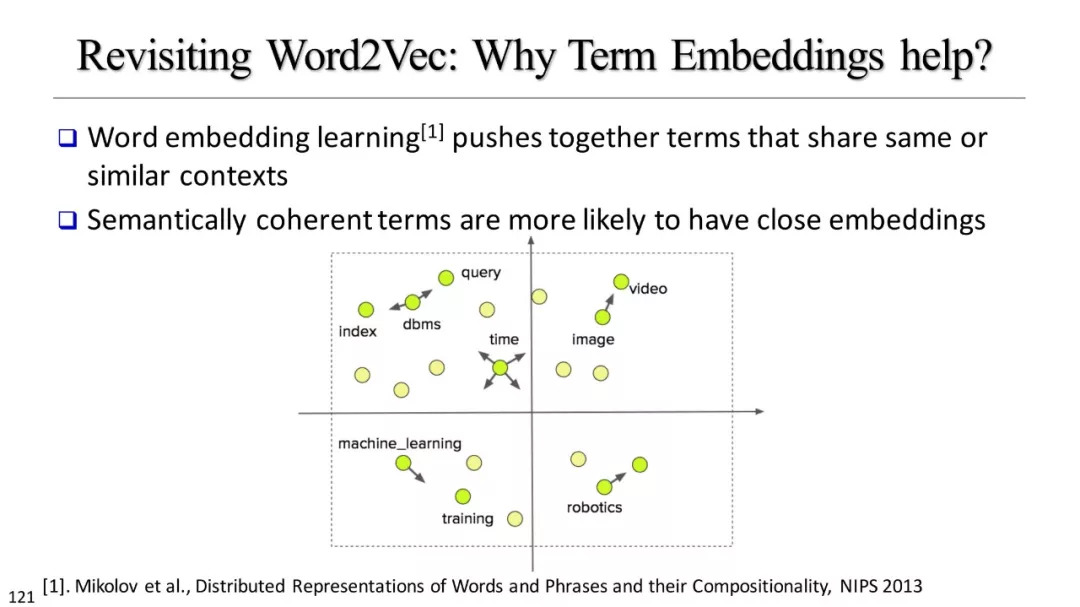
短语挖掘和实体识别
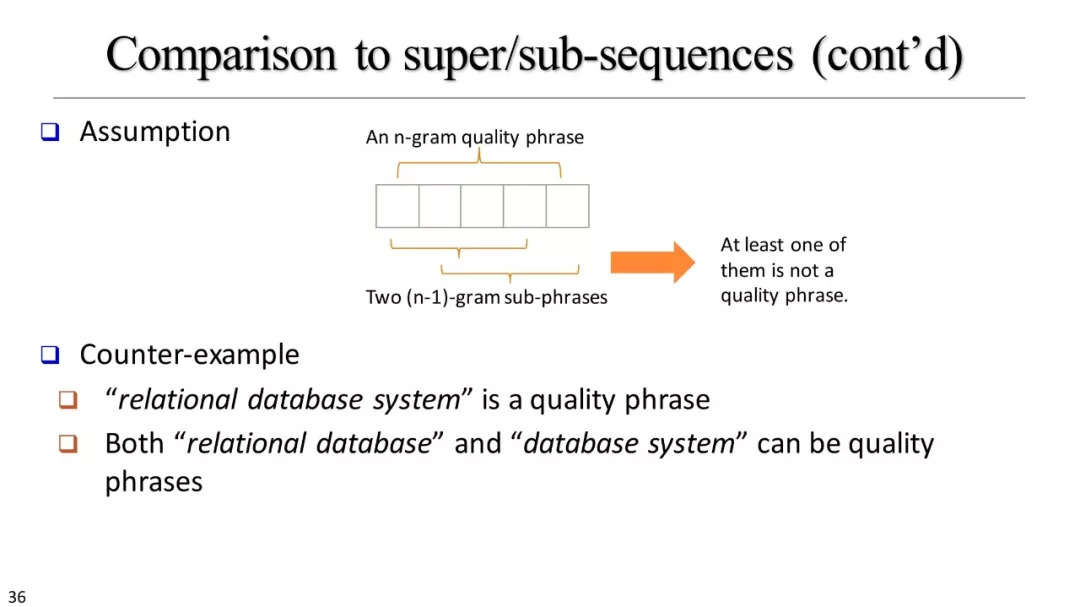
什么是优质短语
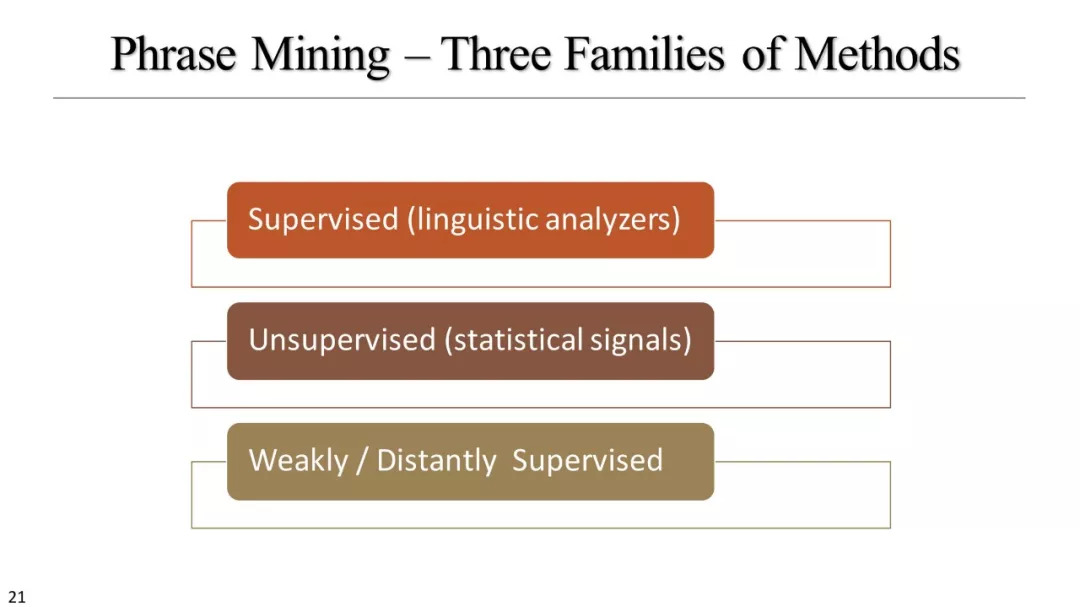
监督方法
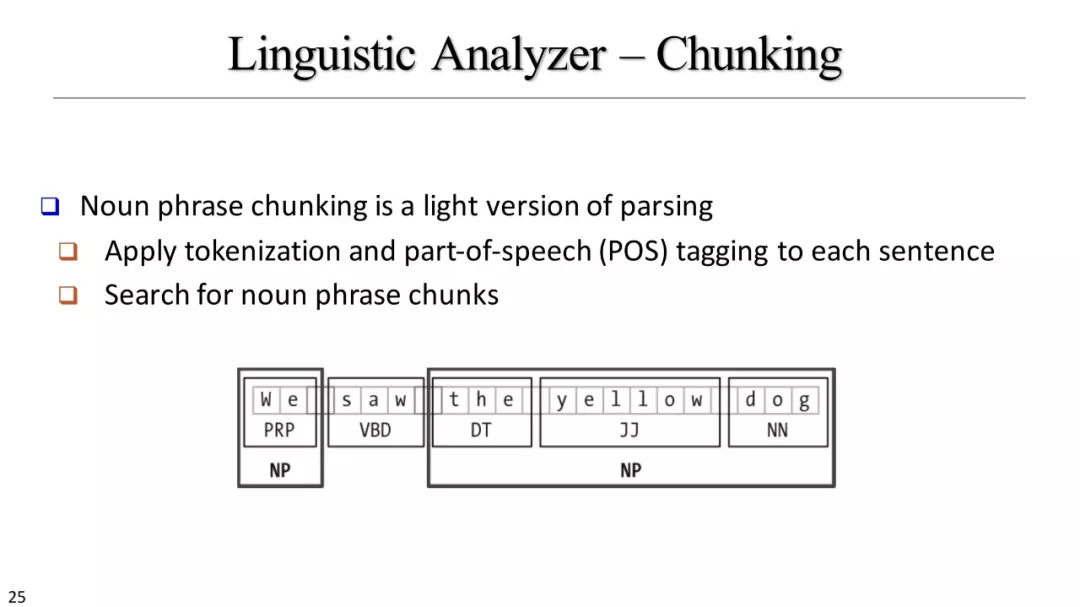
名词短语分块方法
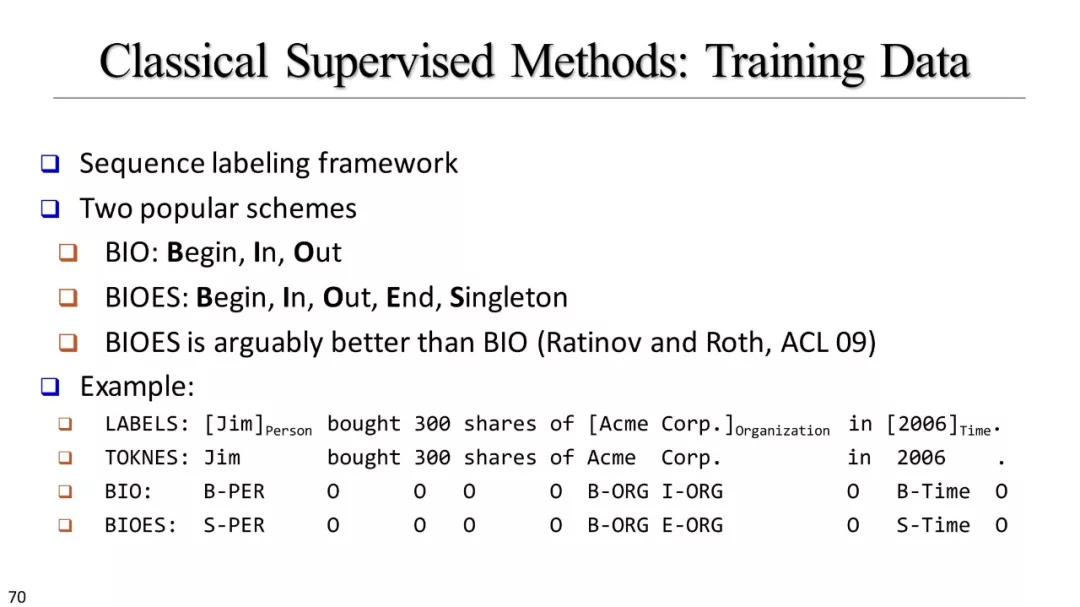
命名实体识别方法
序列标记的神经网络模型
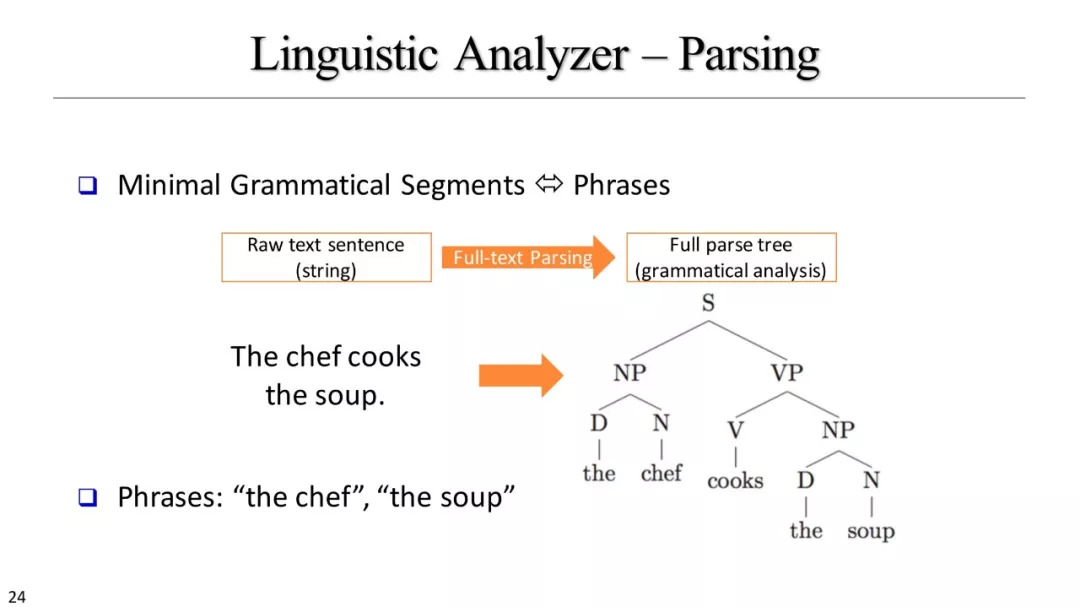
基于解析的方法
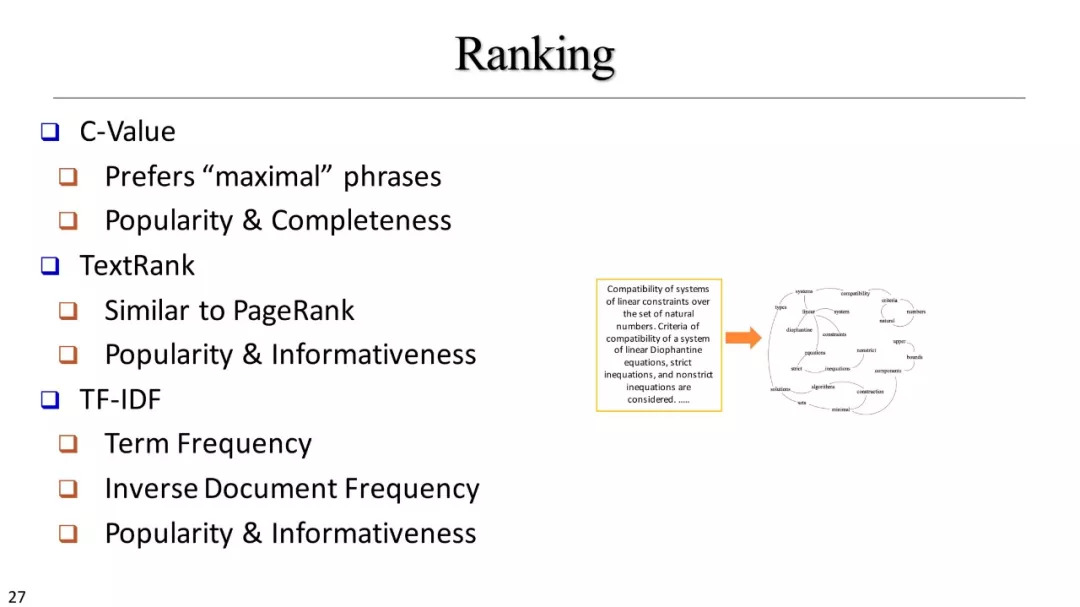
如何在语料库级别对实体进行排名
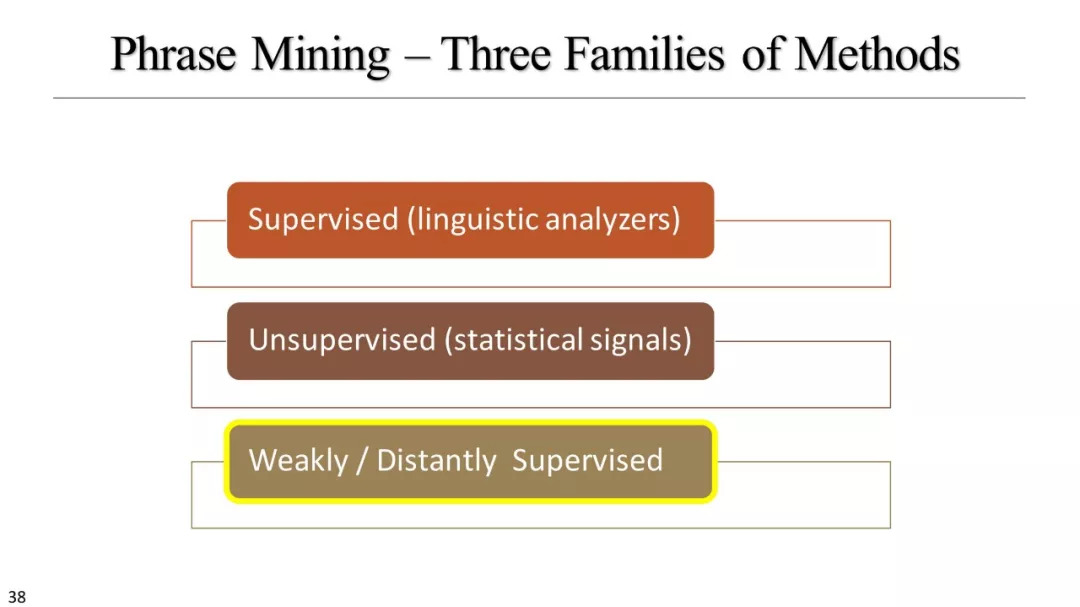
无监督方法
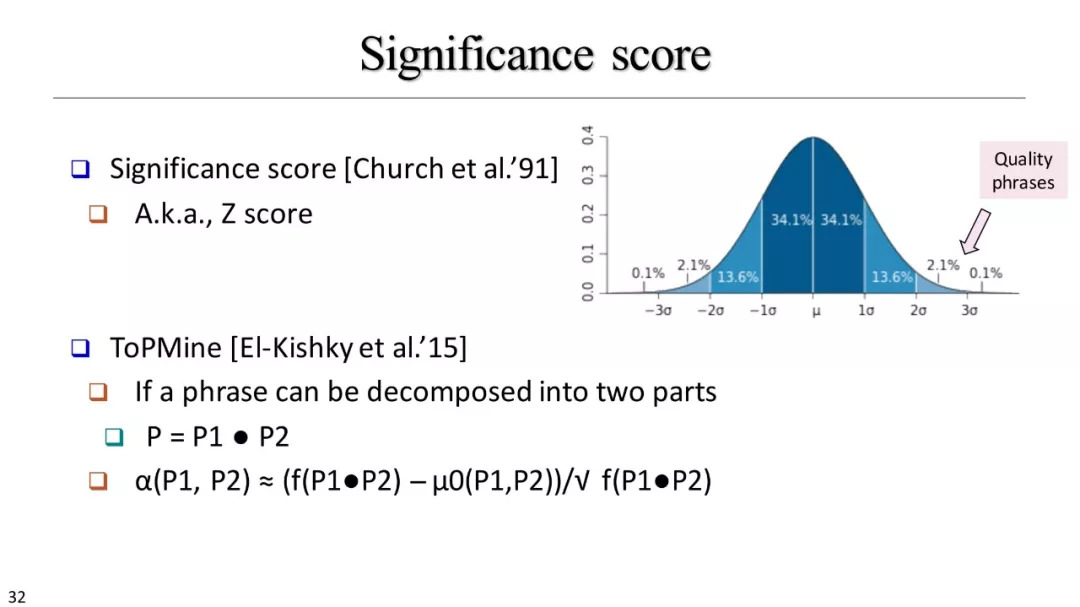
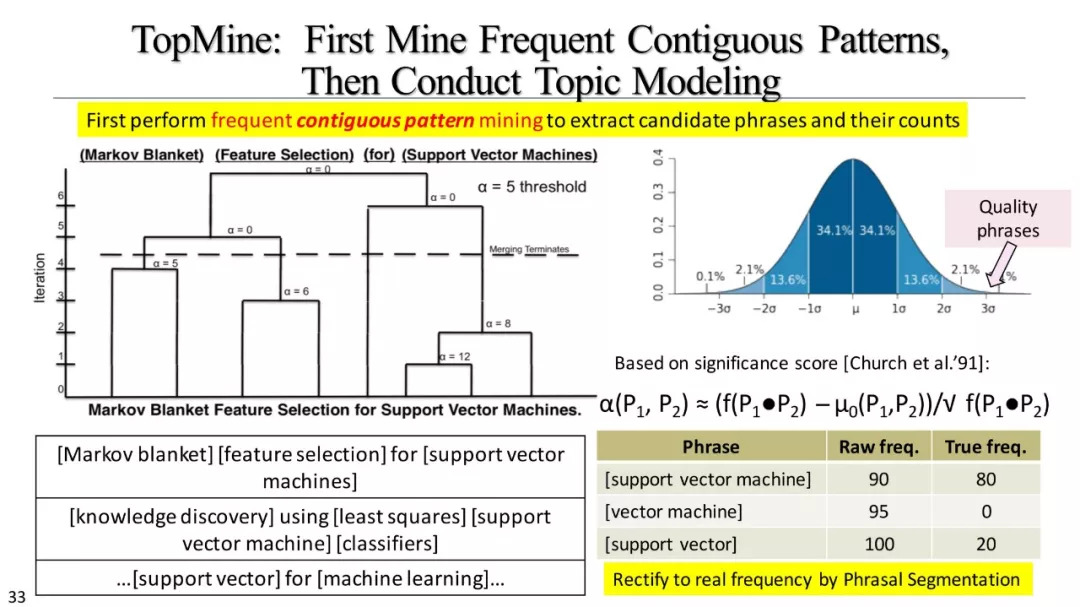
基于原始频率的方法
基于协调的方法
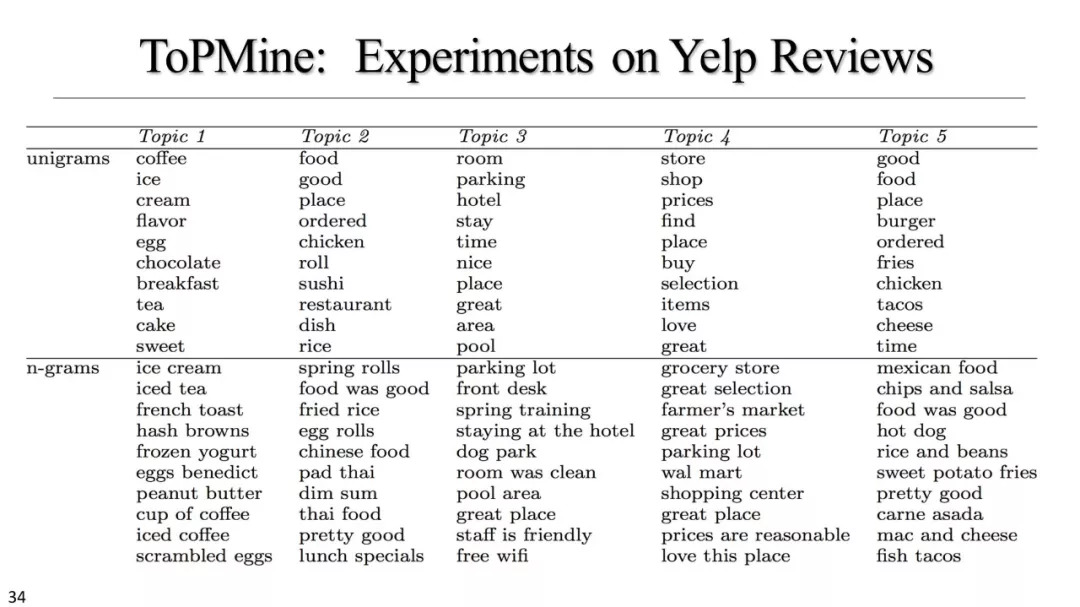
基于主题模型的方法
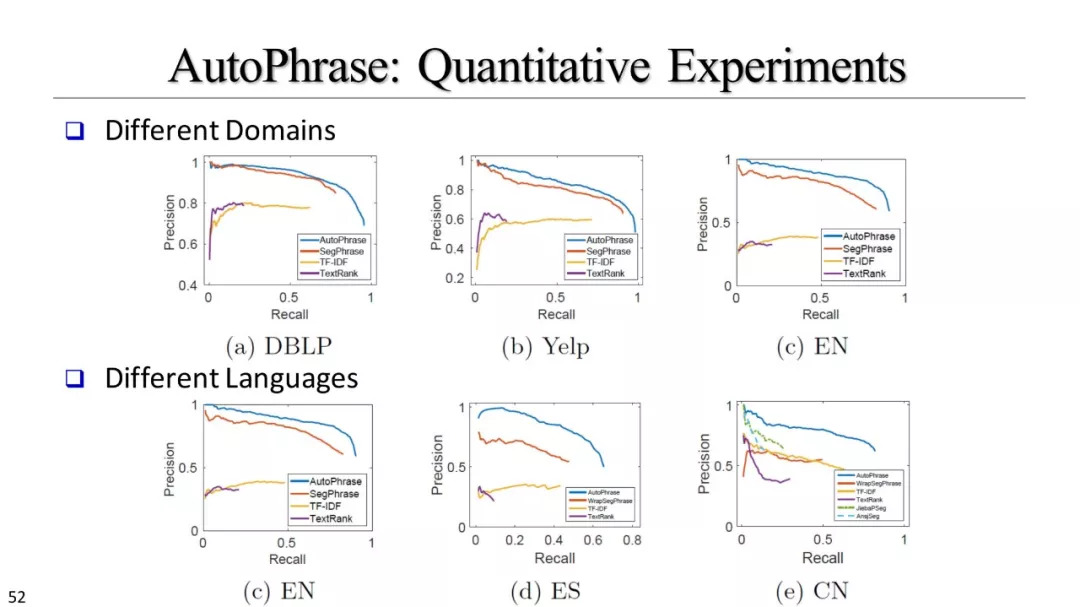
比较方法
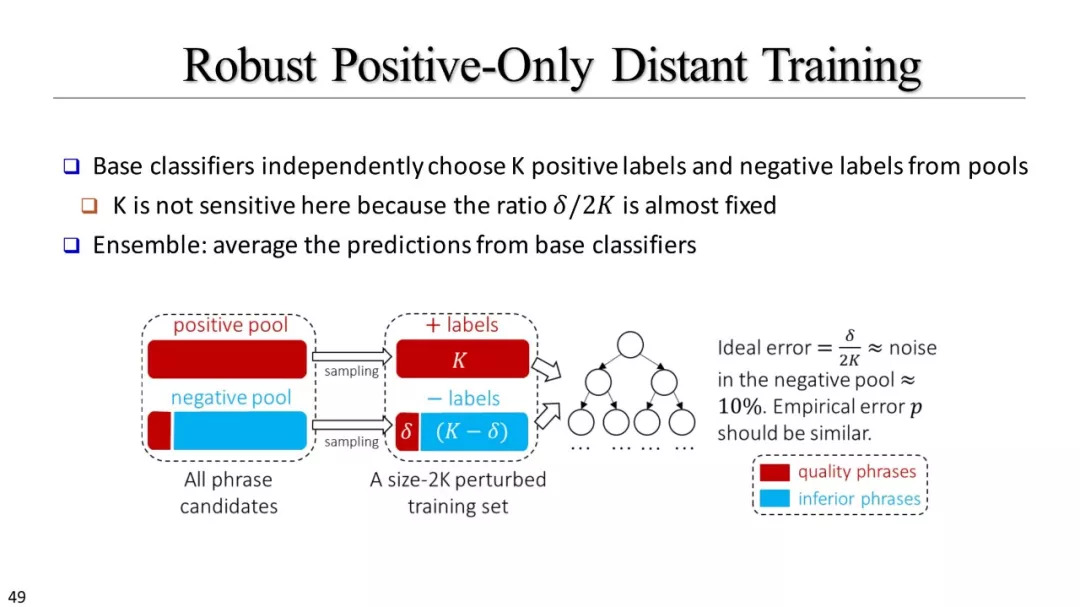
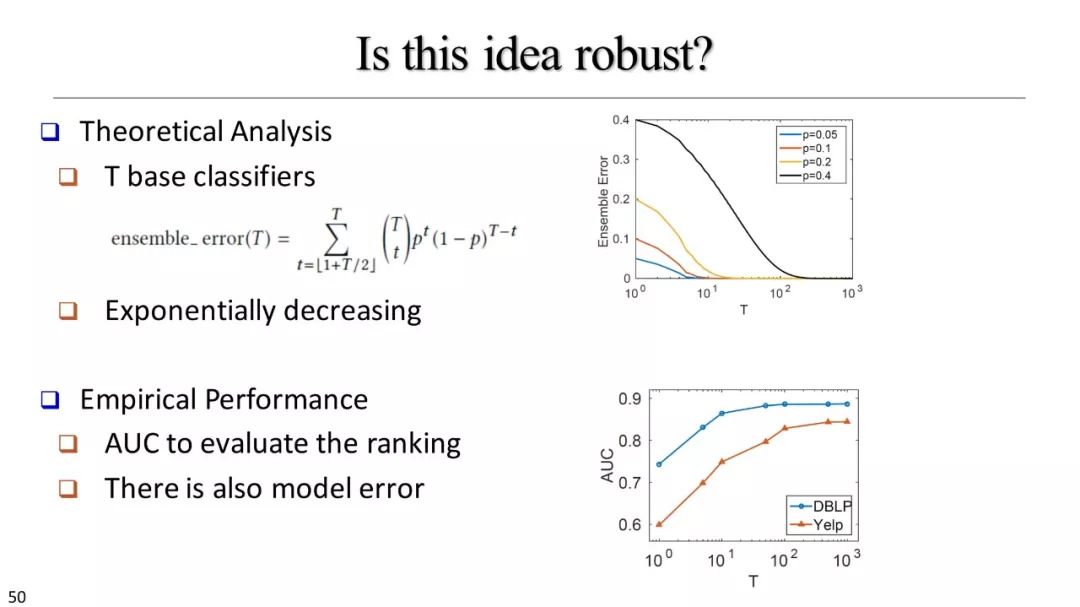
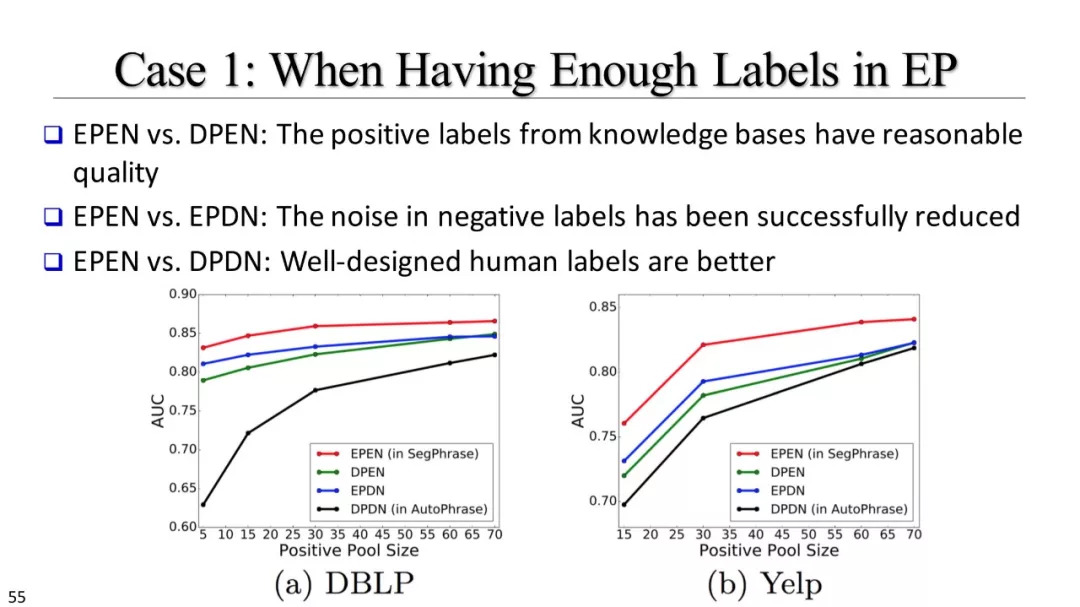
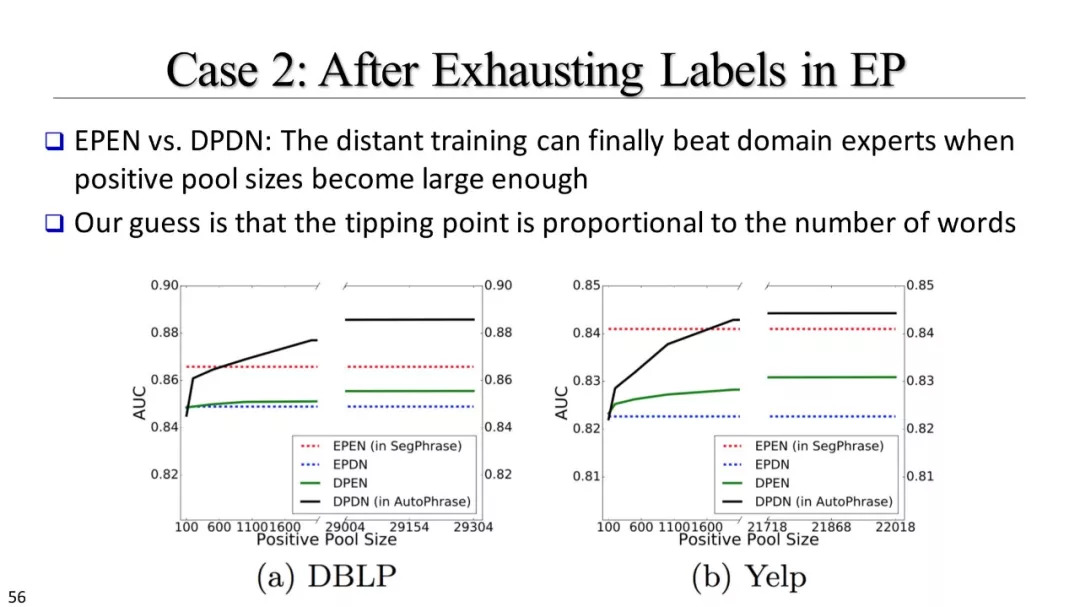
弱、远监督方法
短语分词及其变体
如何利用远监督?
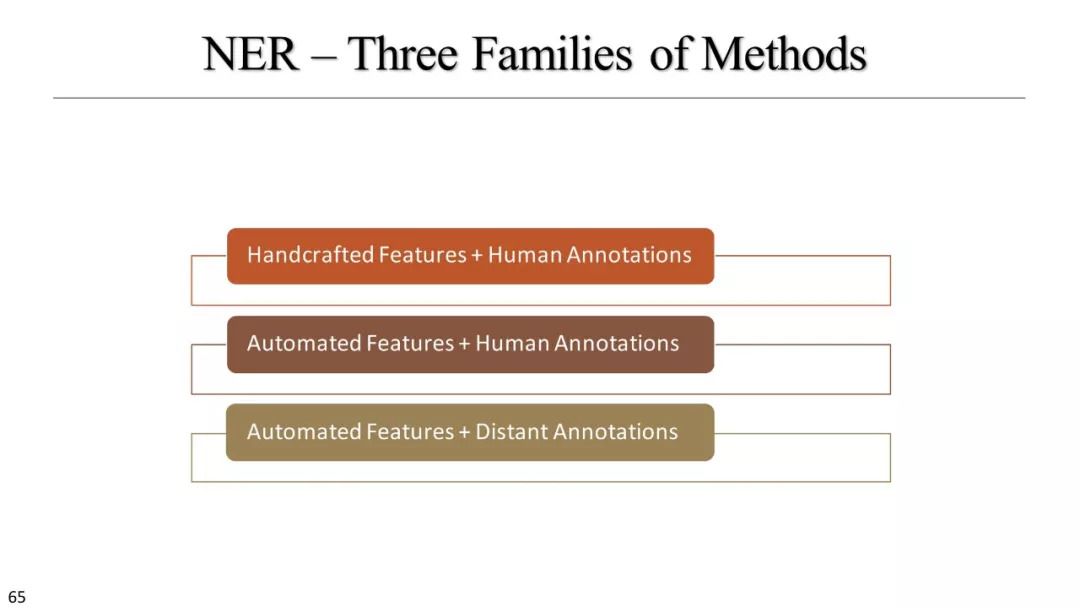
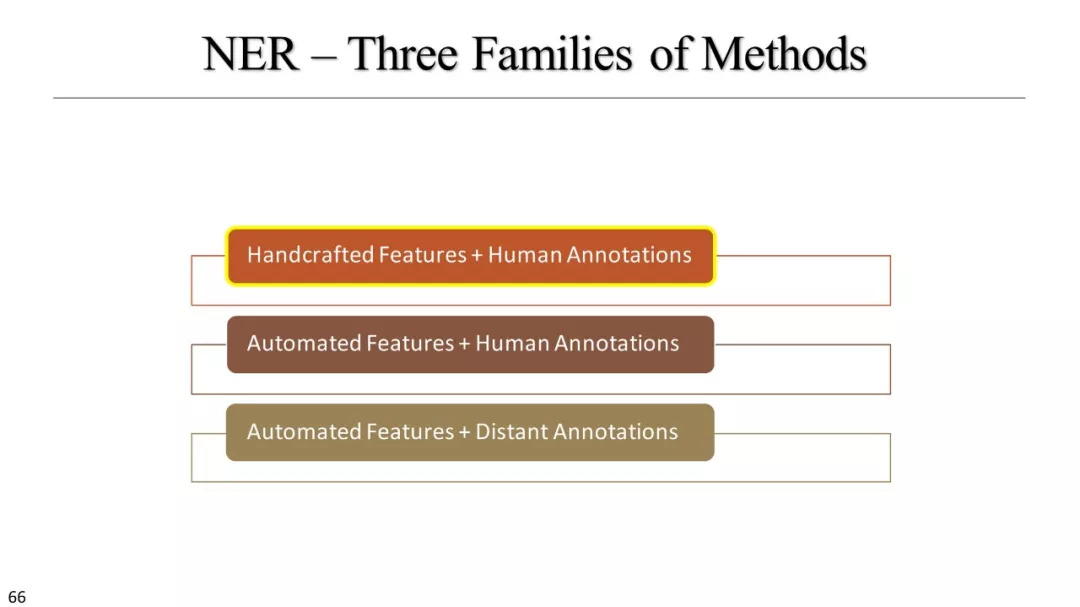
命名实体识别
什么是命名实体识别
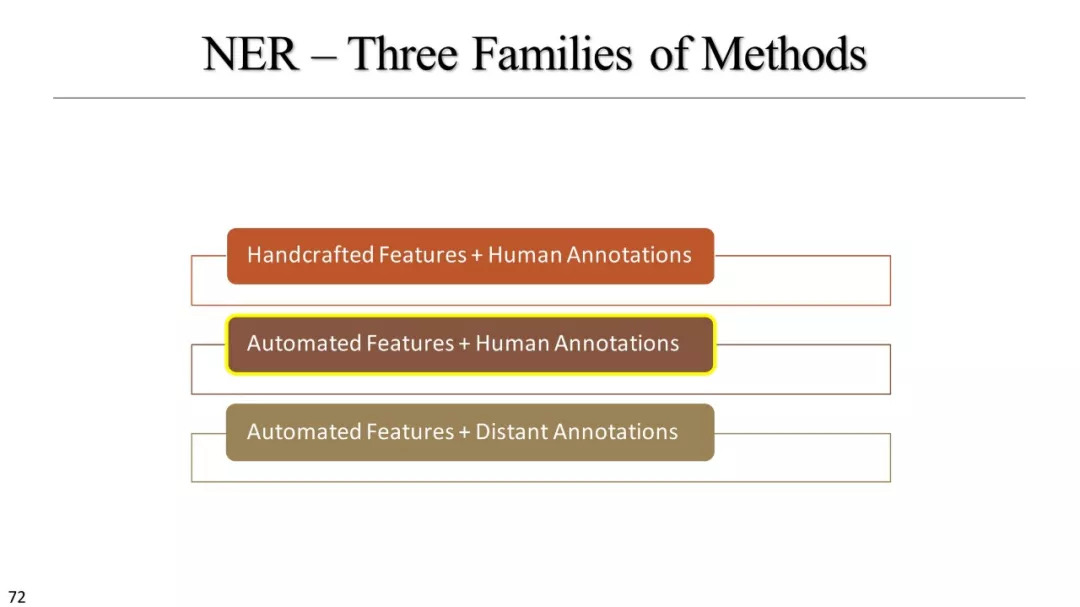
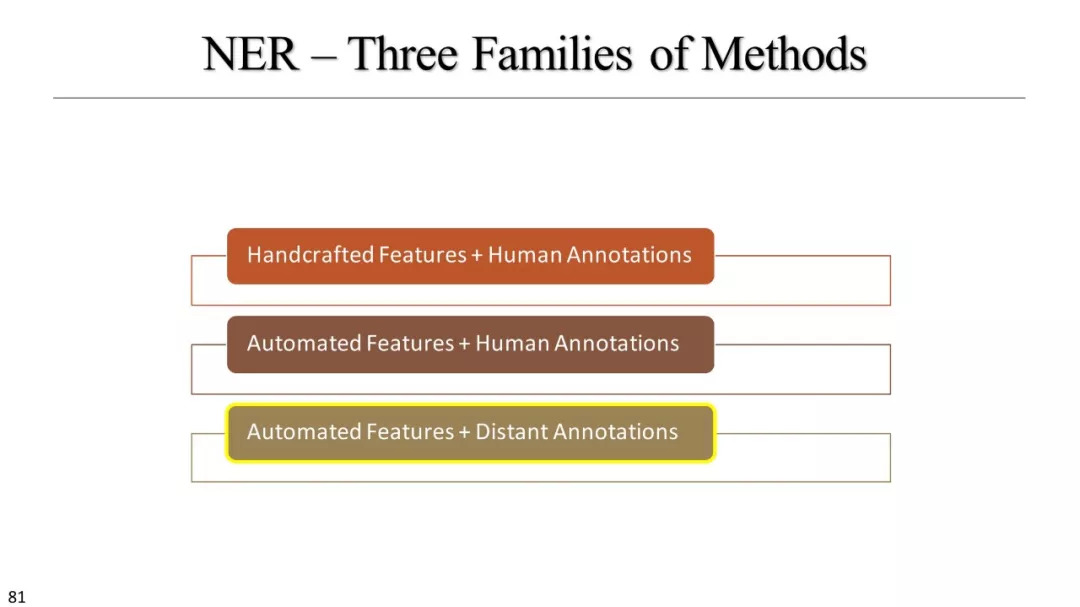
手工制作特征+人监督
经典模型:条件随机场
斯坦福NER
推特NER
自动特征+人监督
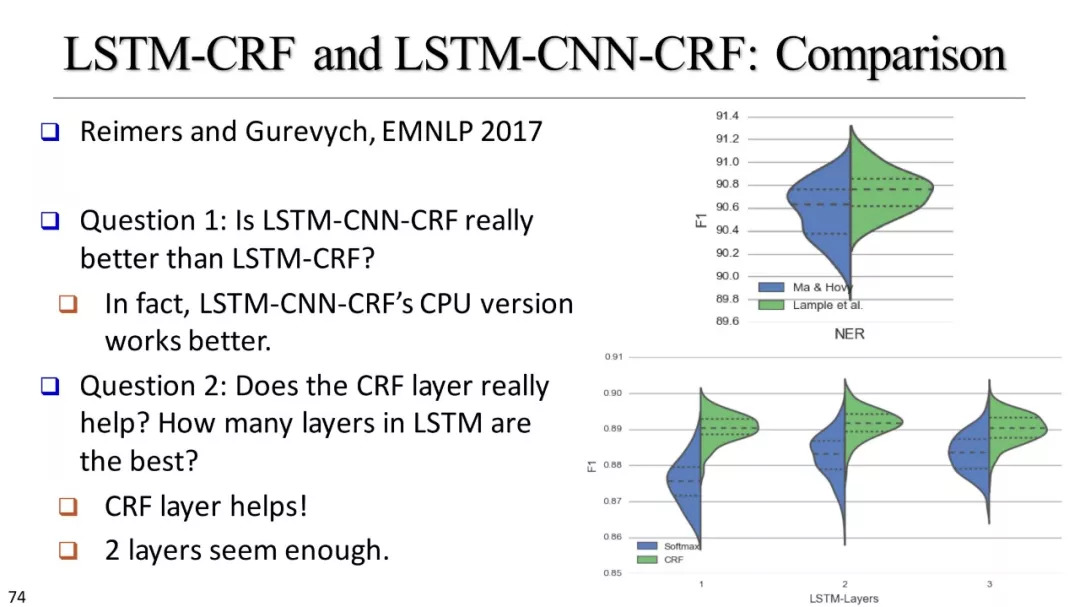
LSTM-CRF,LSTM-CNN-CRF
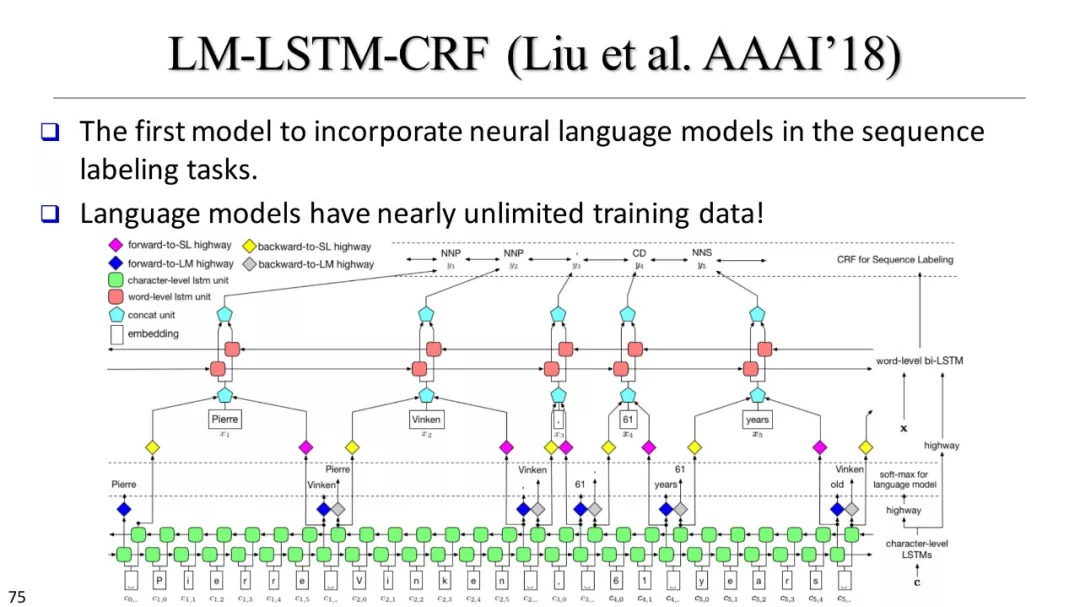
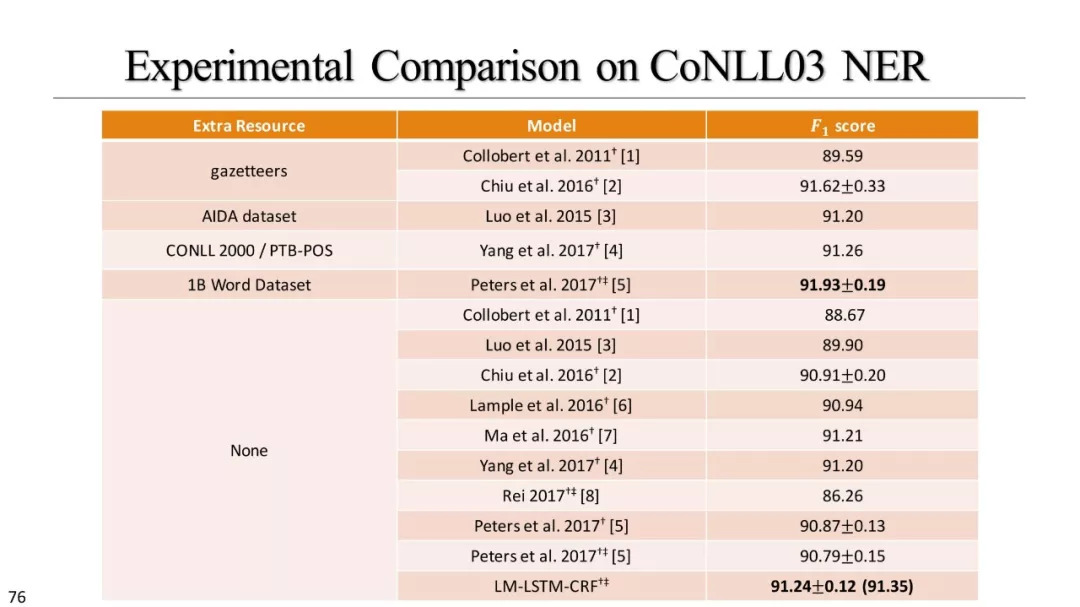
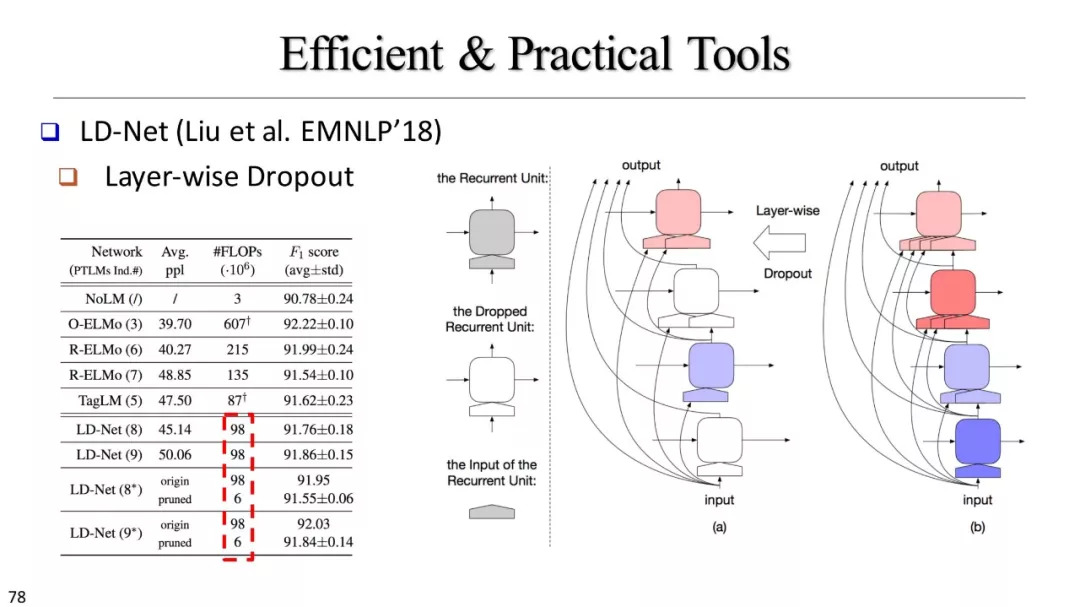
LM-LSTM-CRF,EMLo,Flair
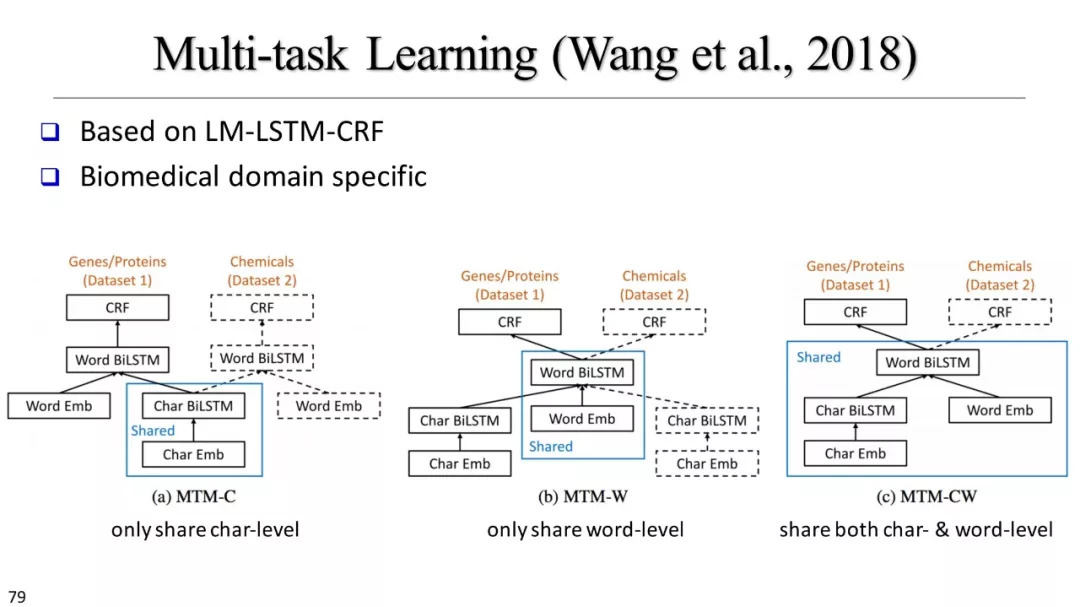
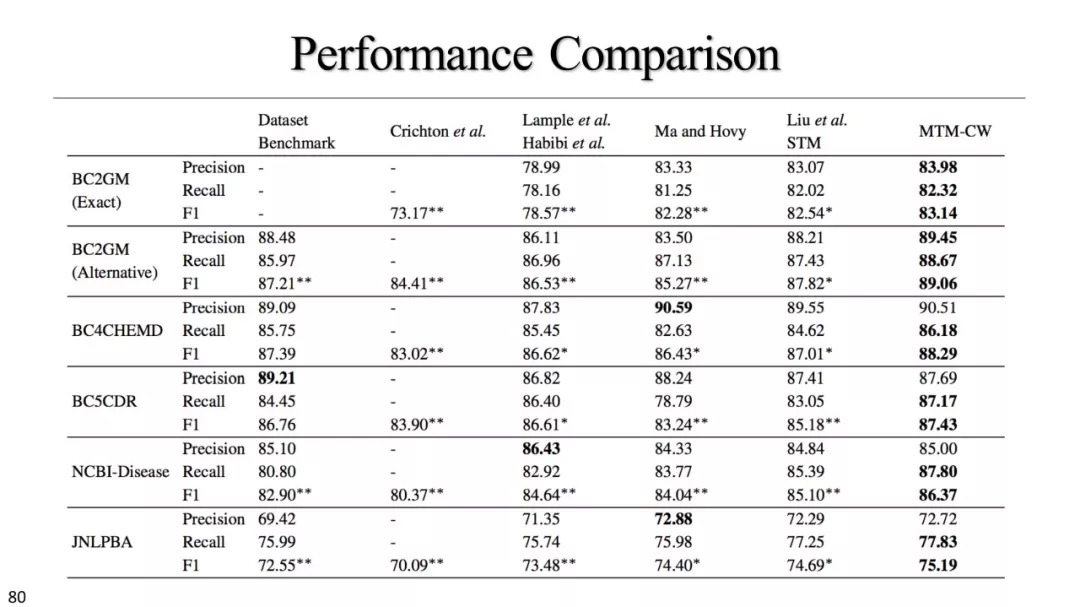
多任务学习
自动特征+远监督
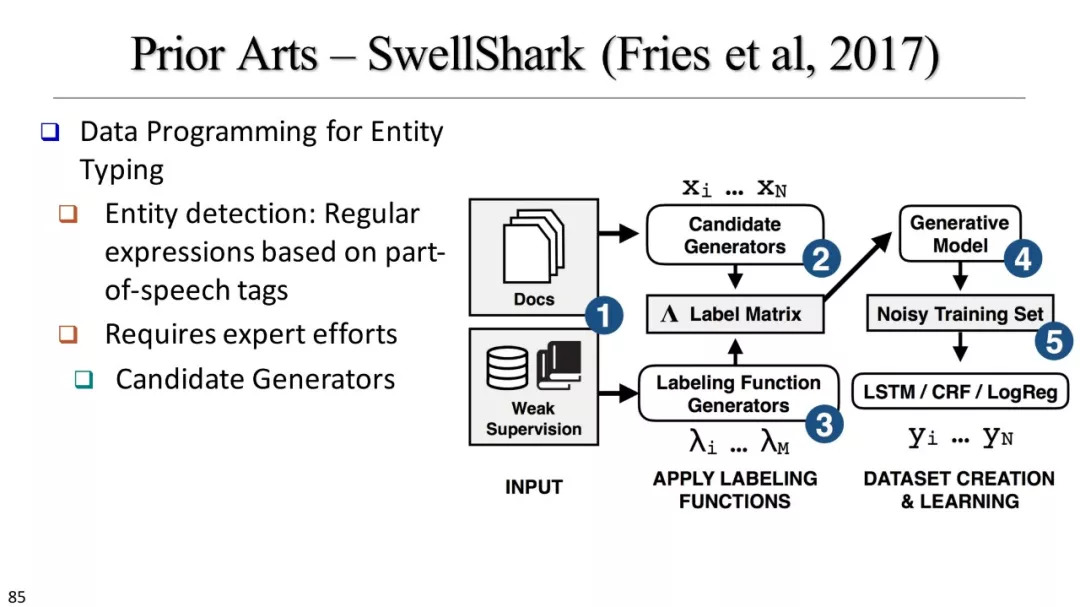
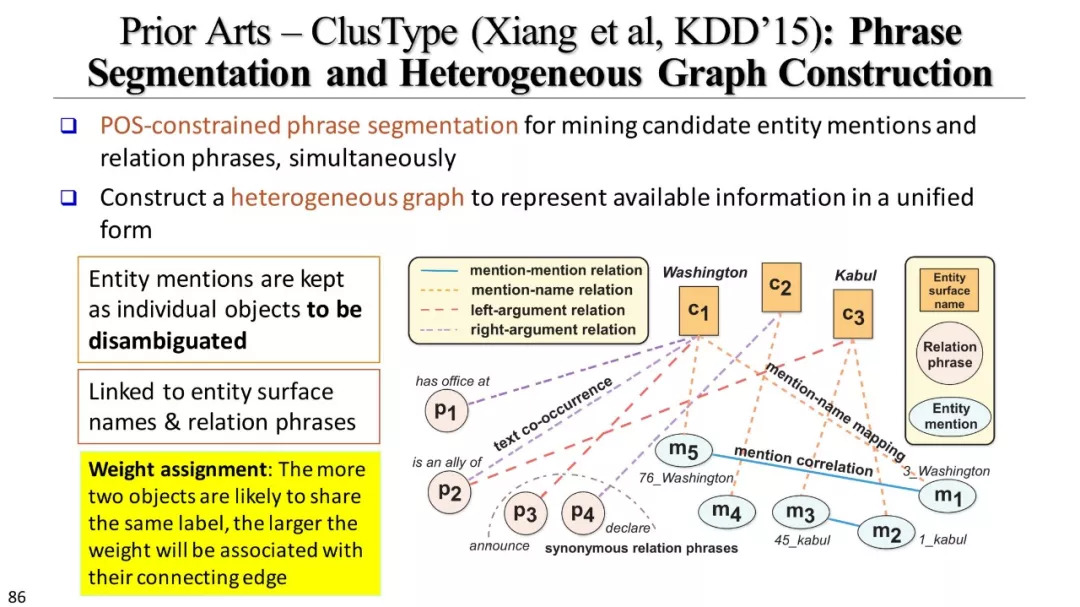
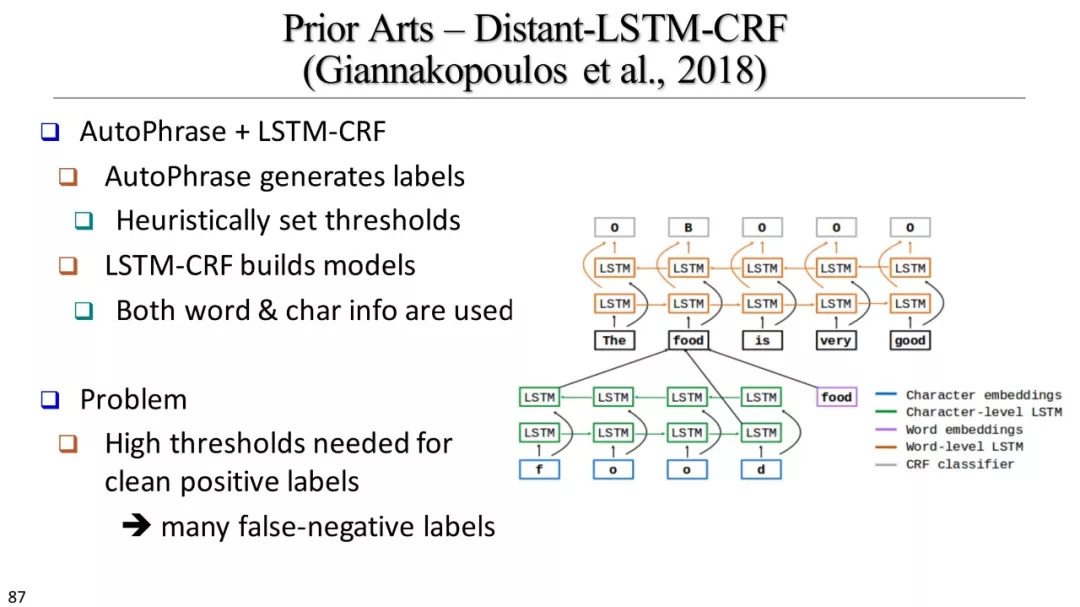
AutoEntity, SwellShark, ClusType, Distant-LSTM-CRF, …
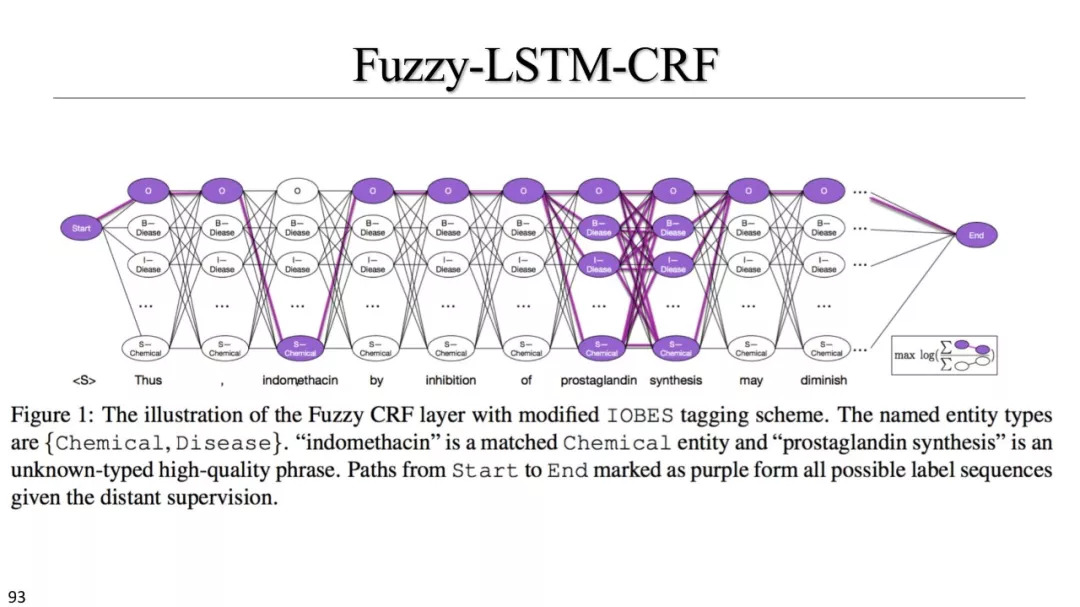
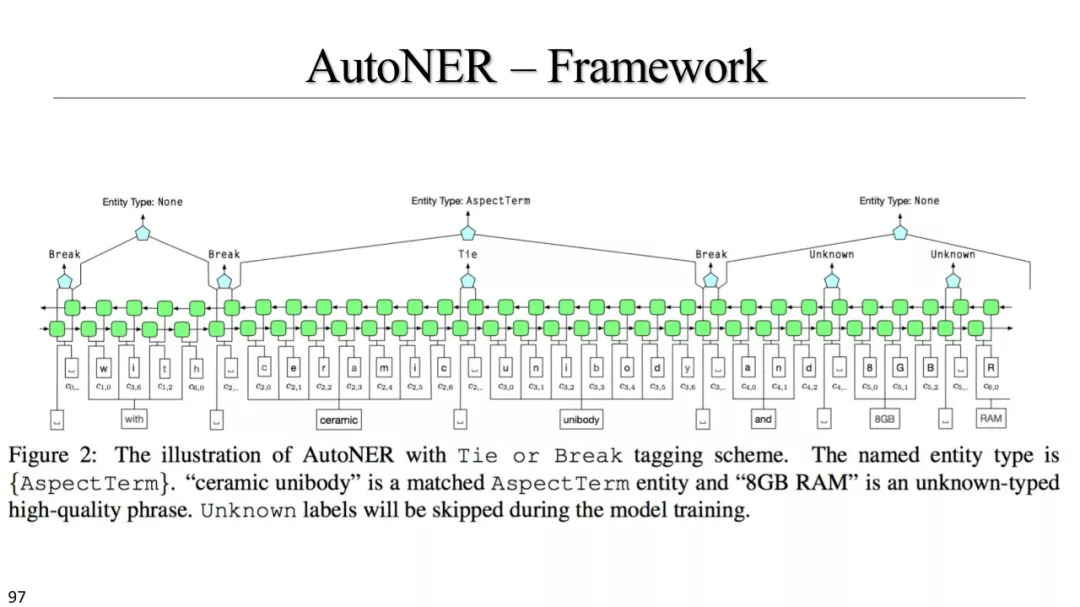
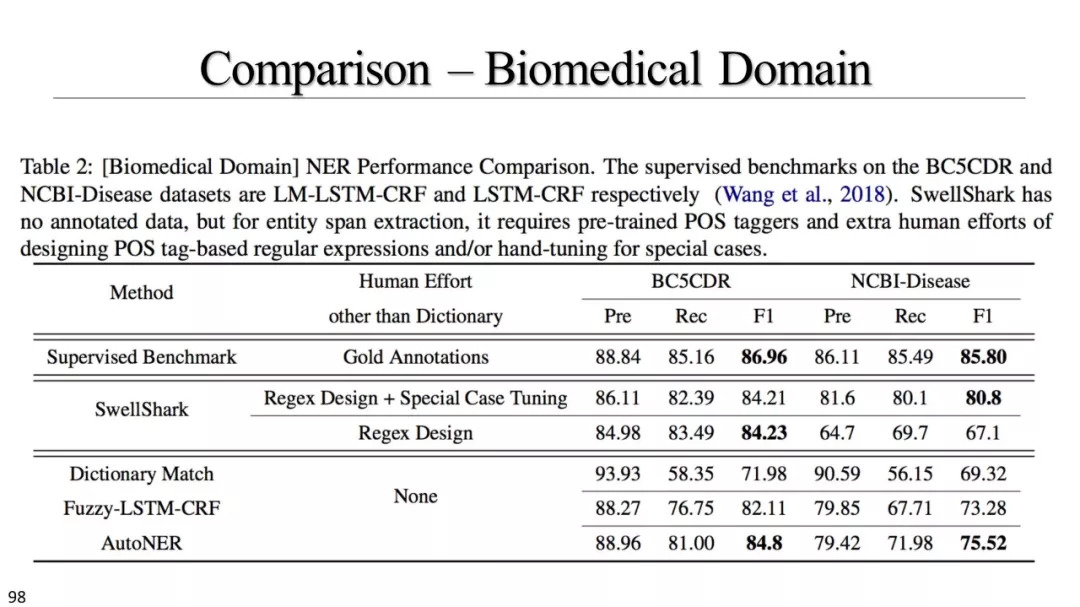
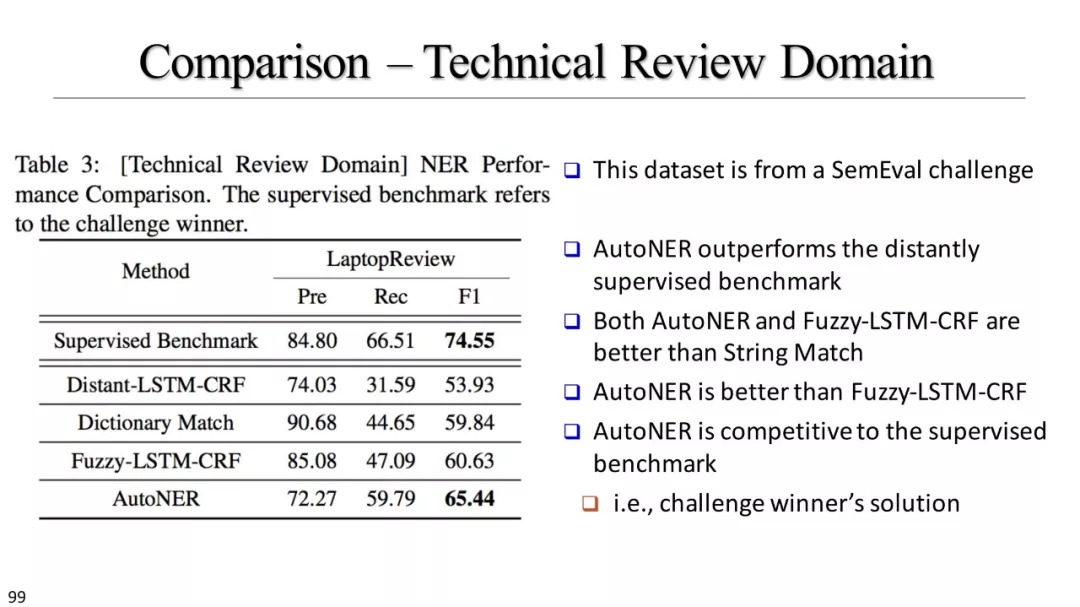
FuzzyCRF & AutoNER
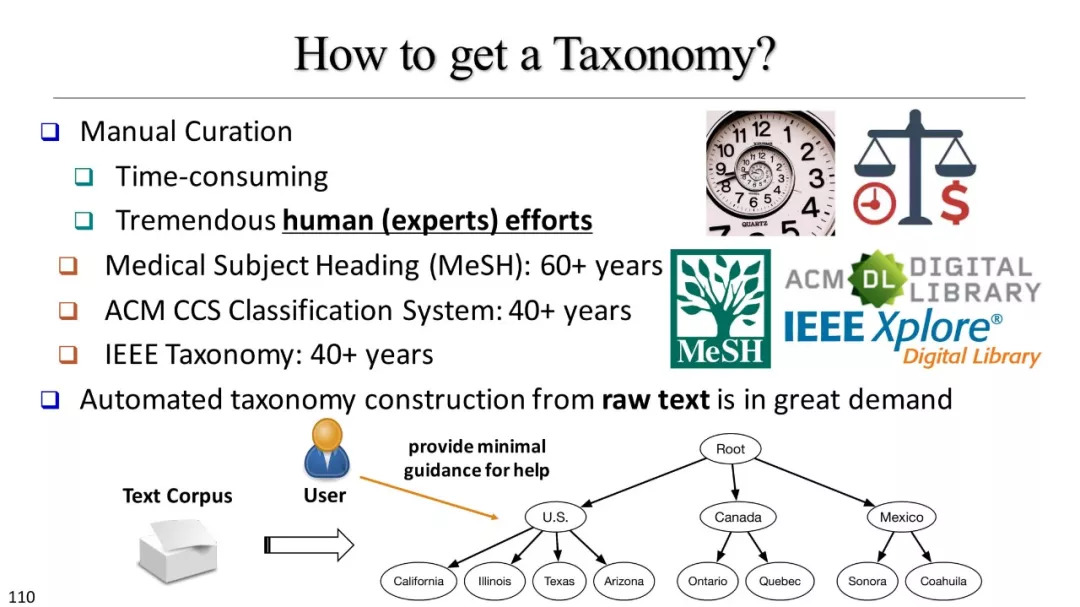
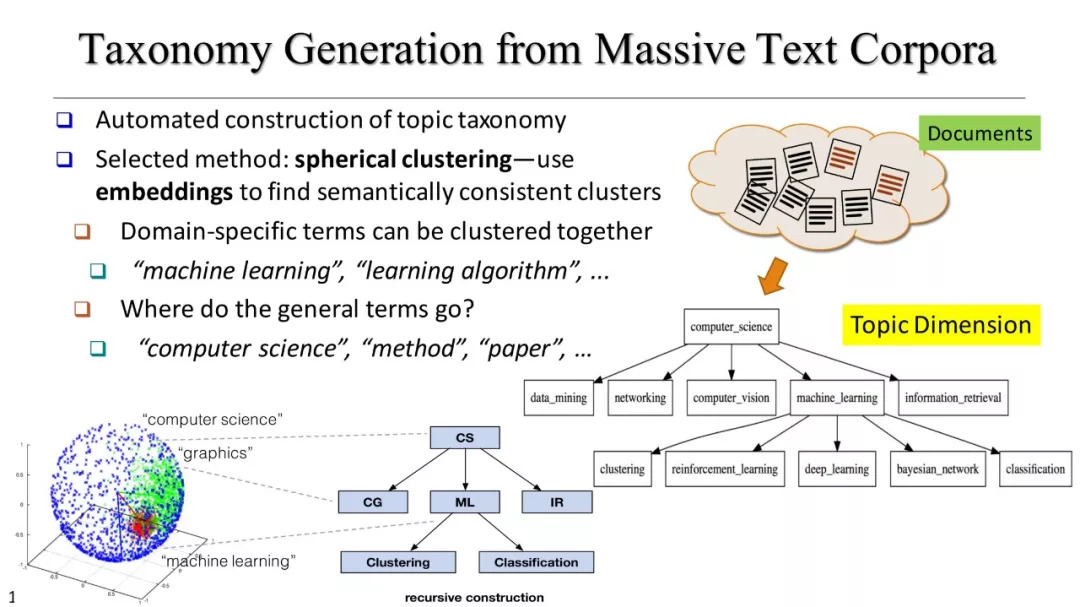
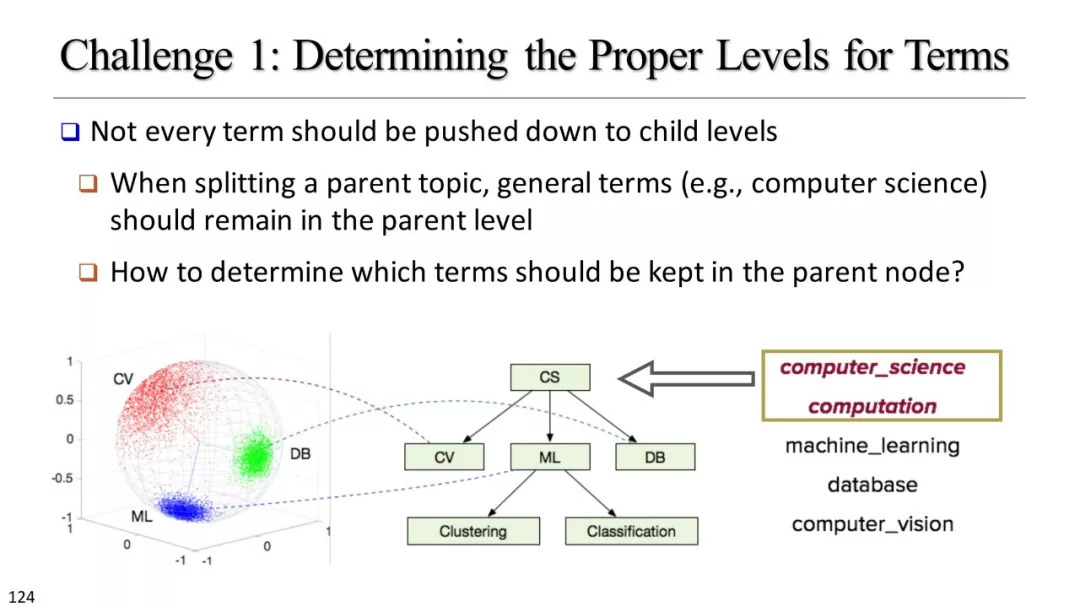
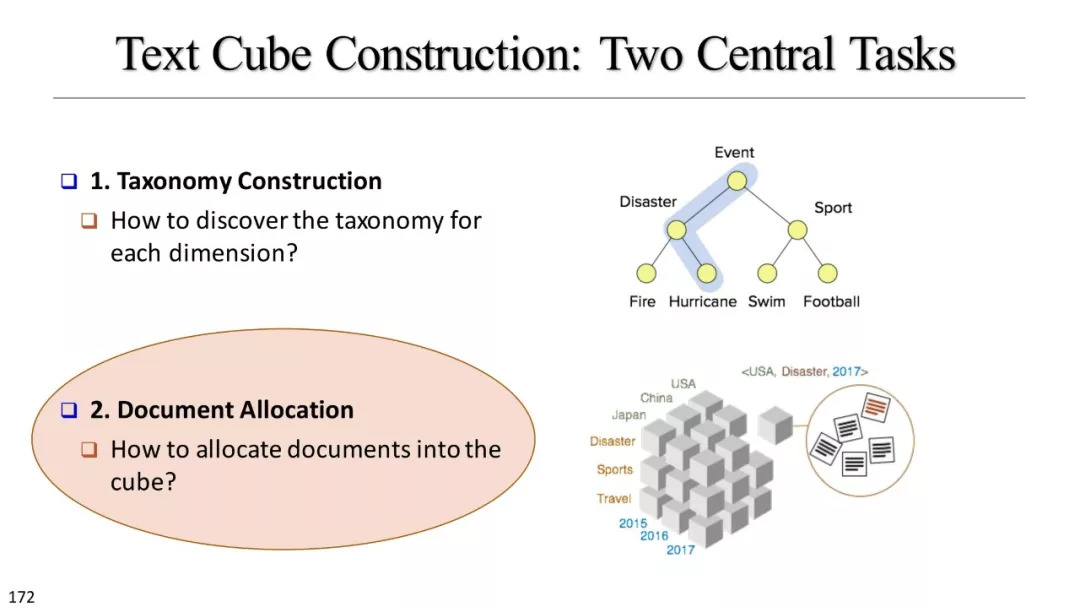
分类库建设
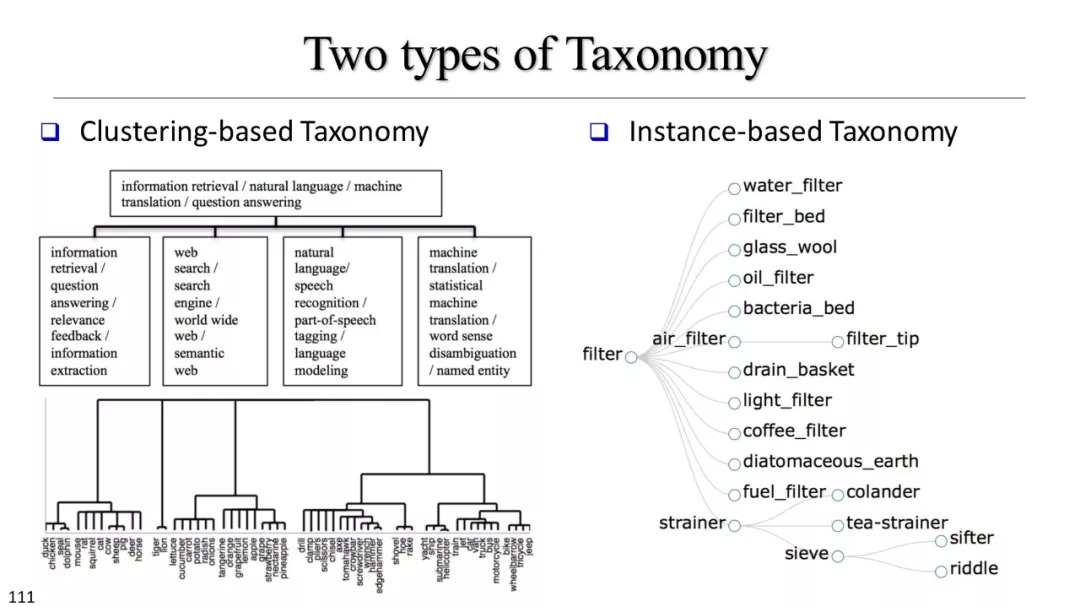
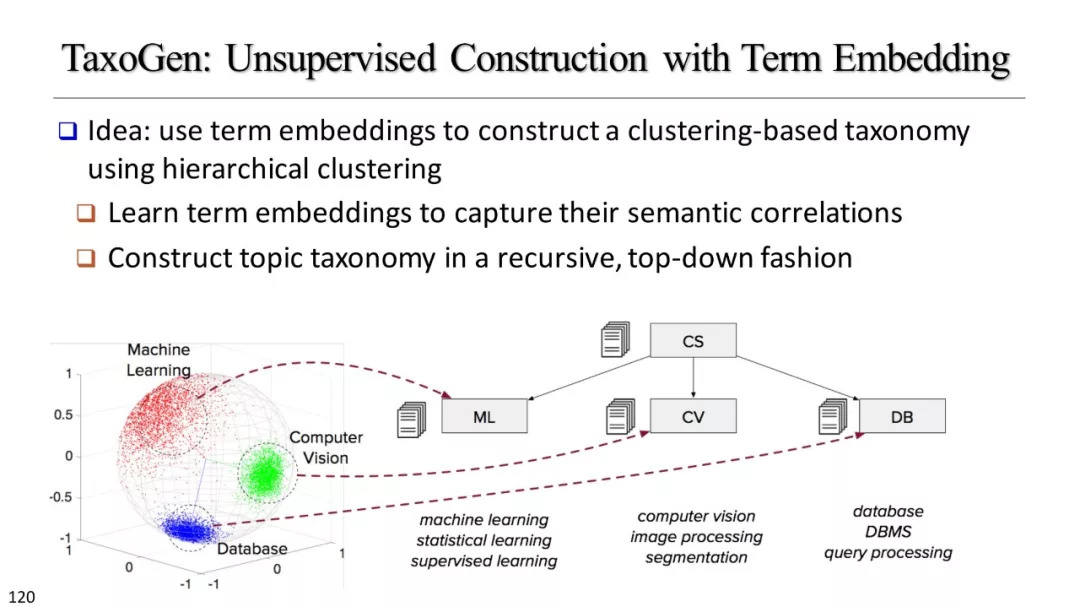
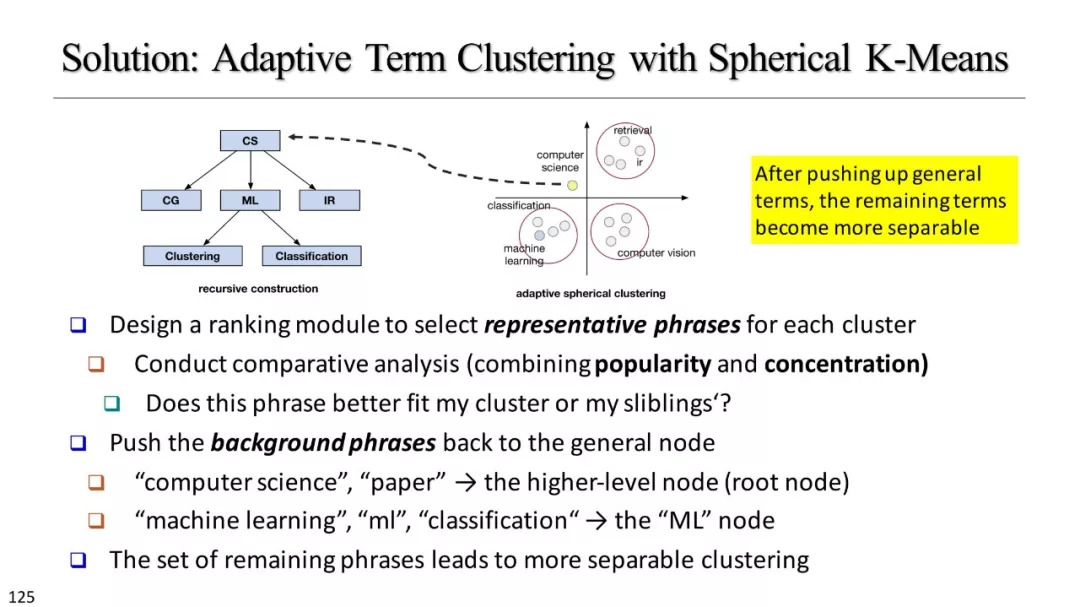
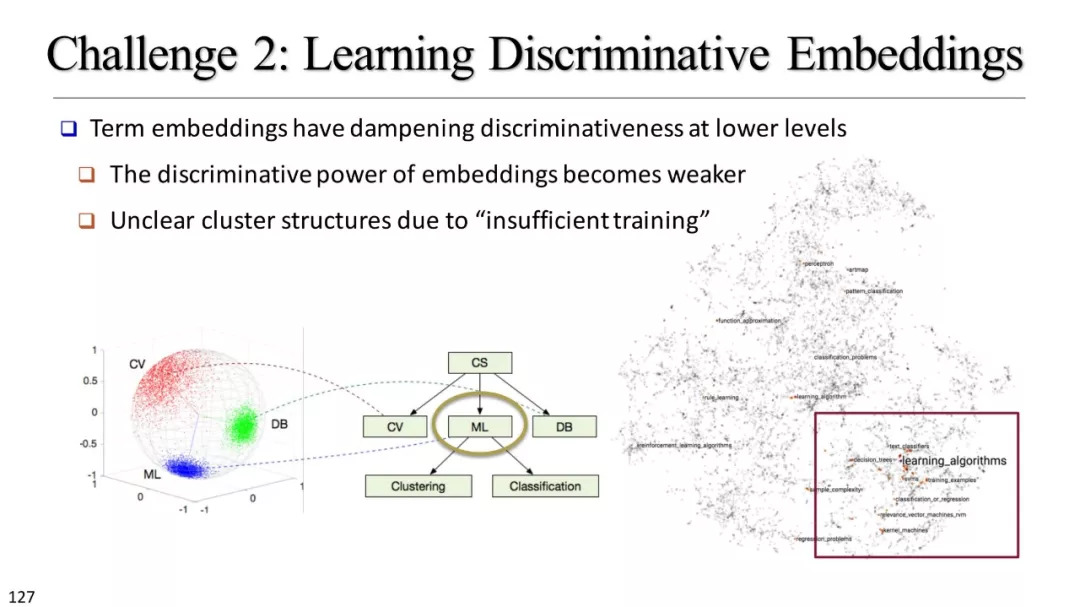
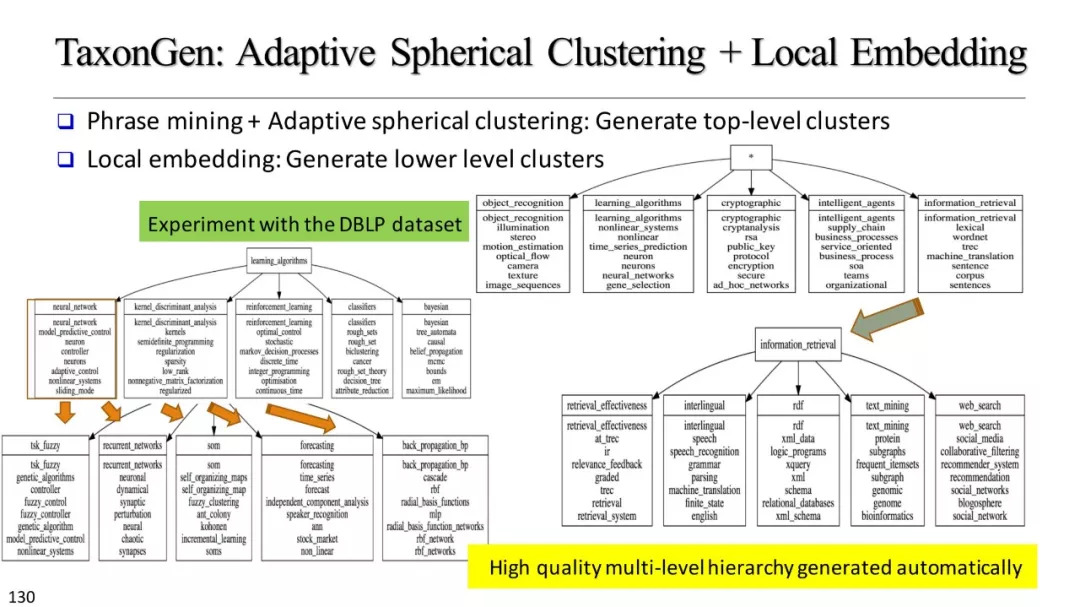
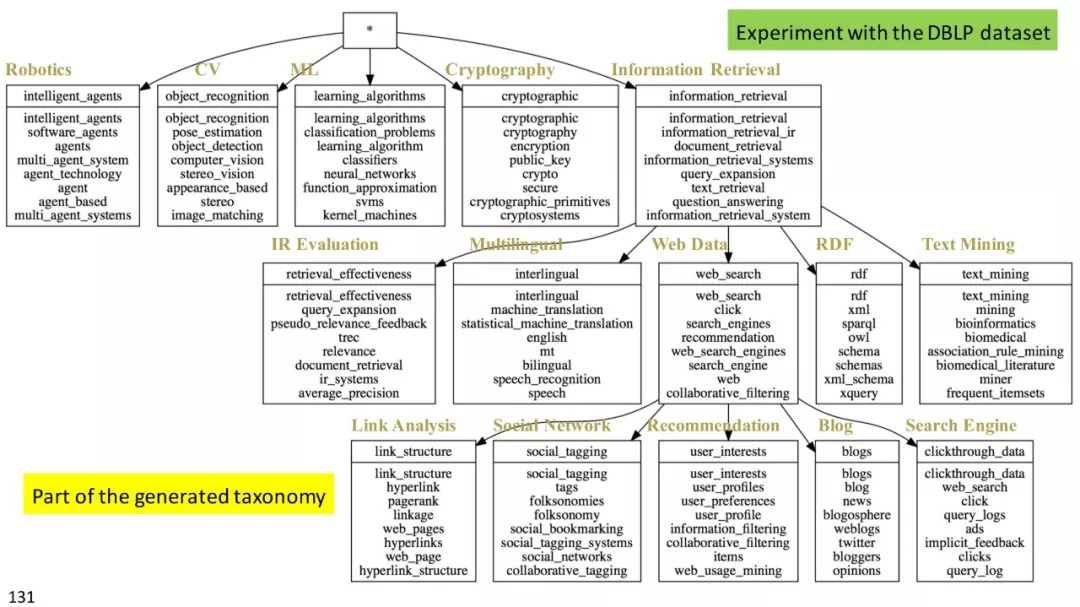
基于聚类的分类标准构建
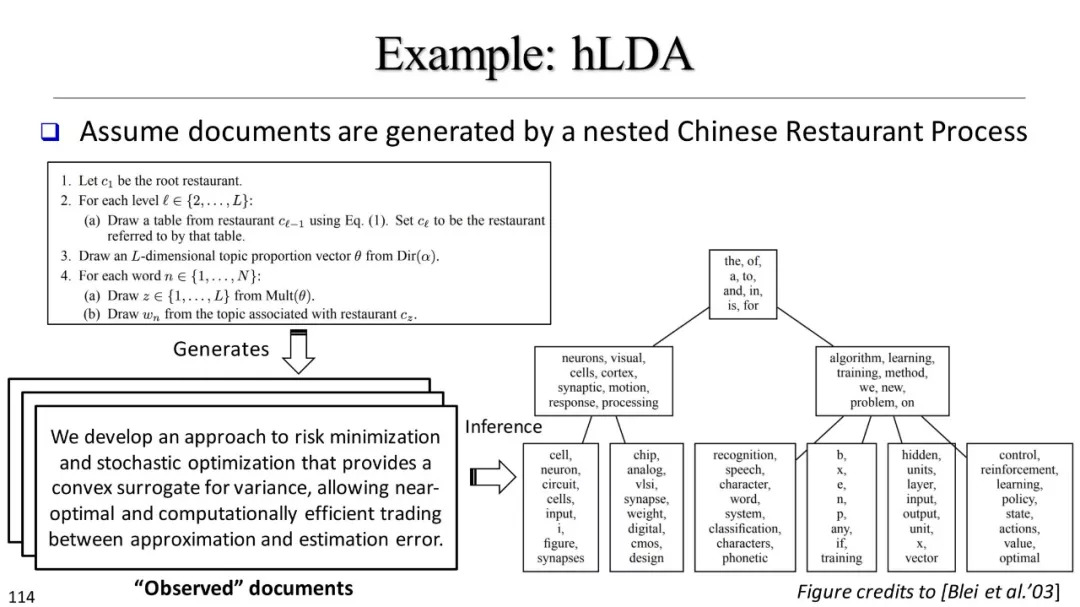
分层主题建模
通用图模型方法
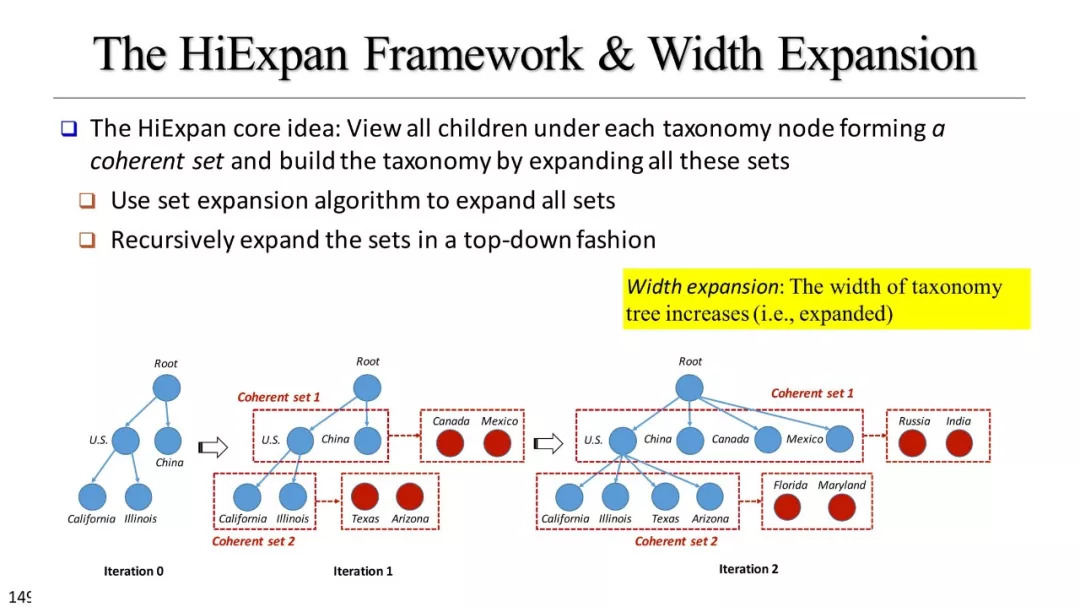
层次聚类
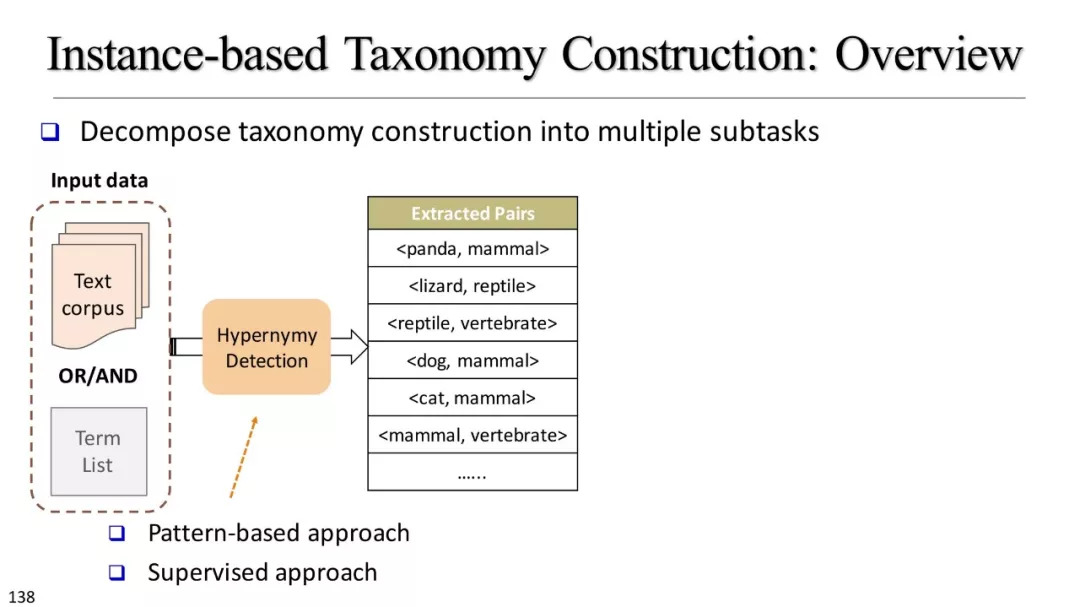
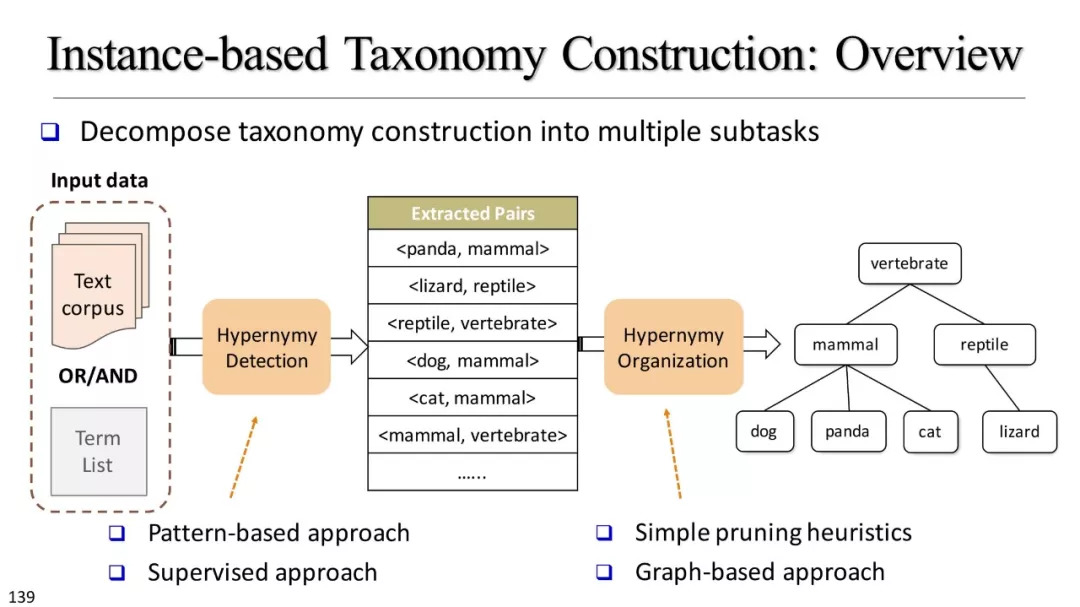
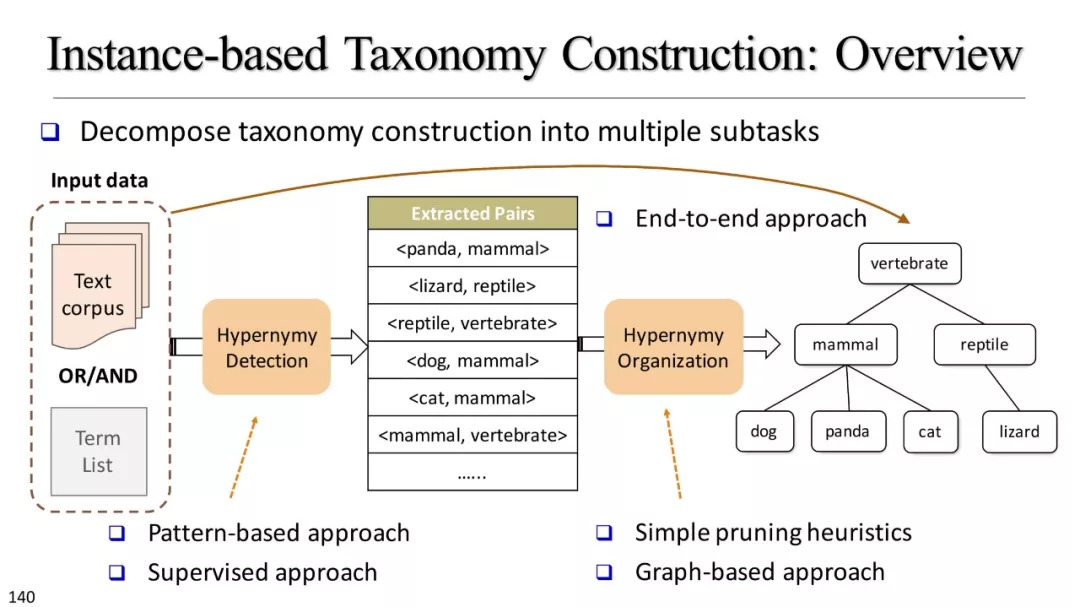
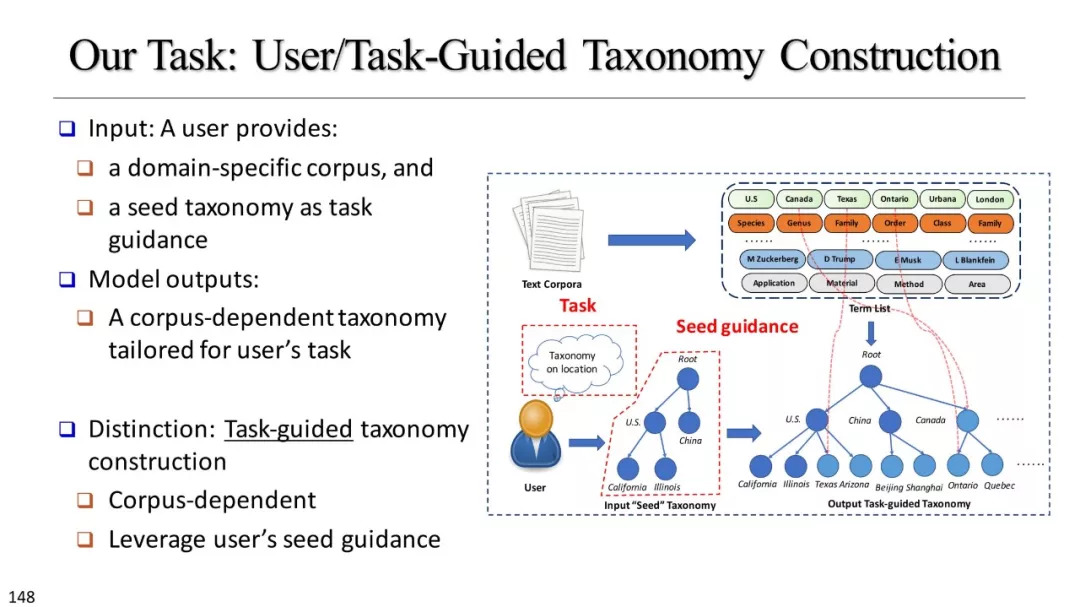
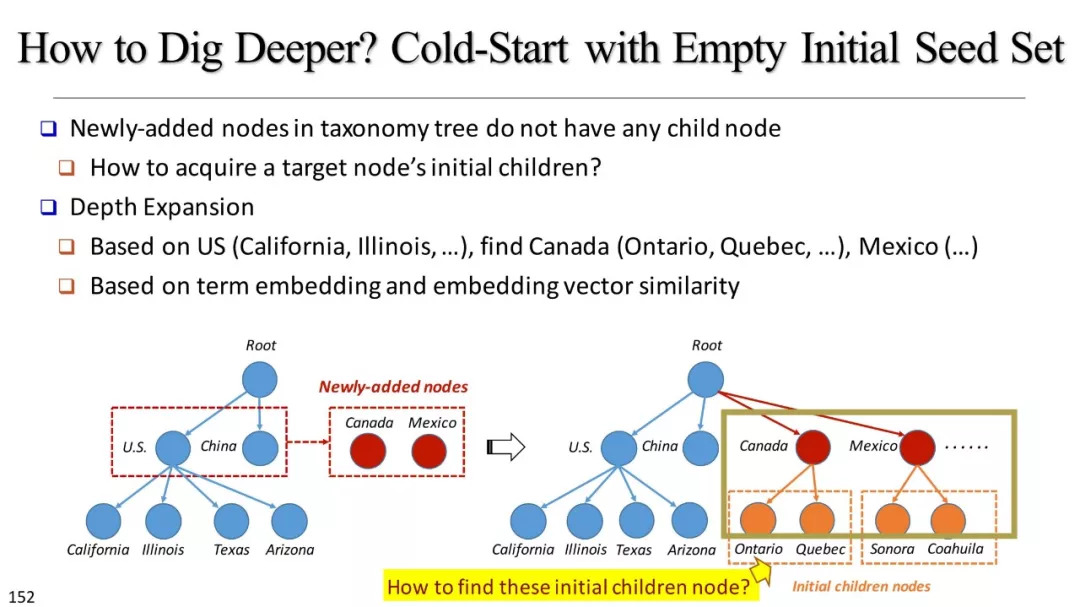
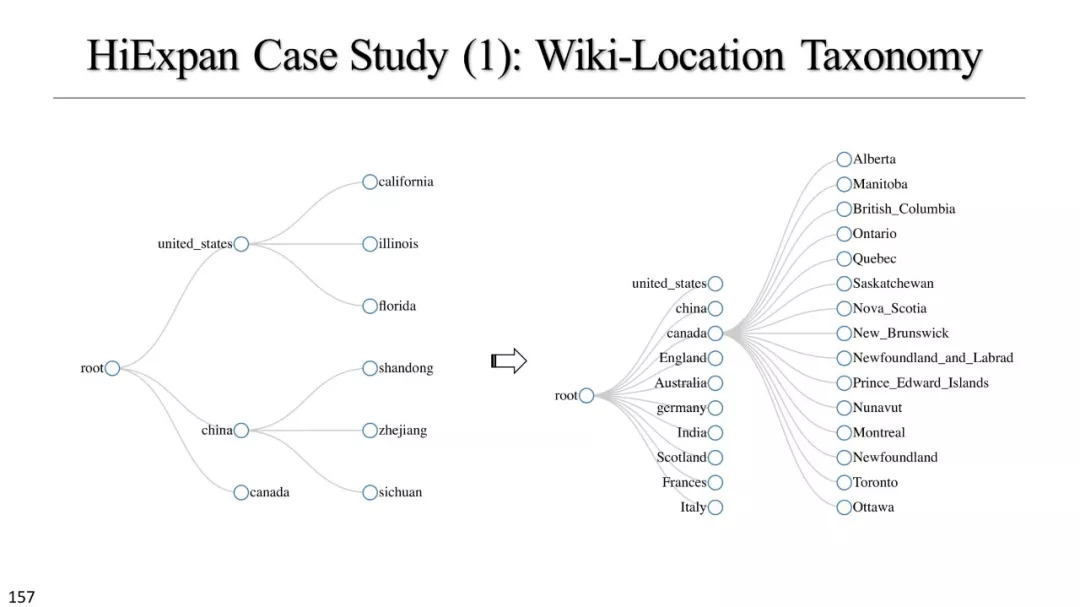
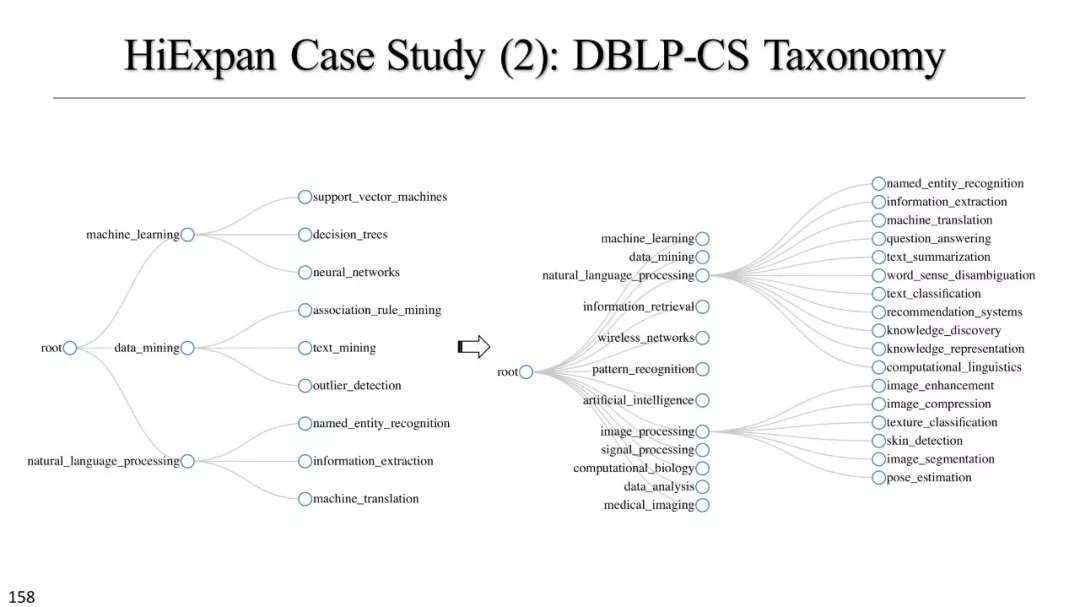
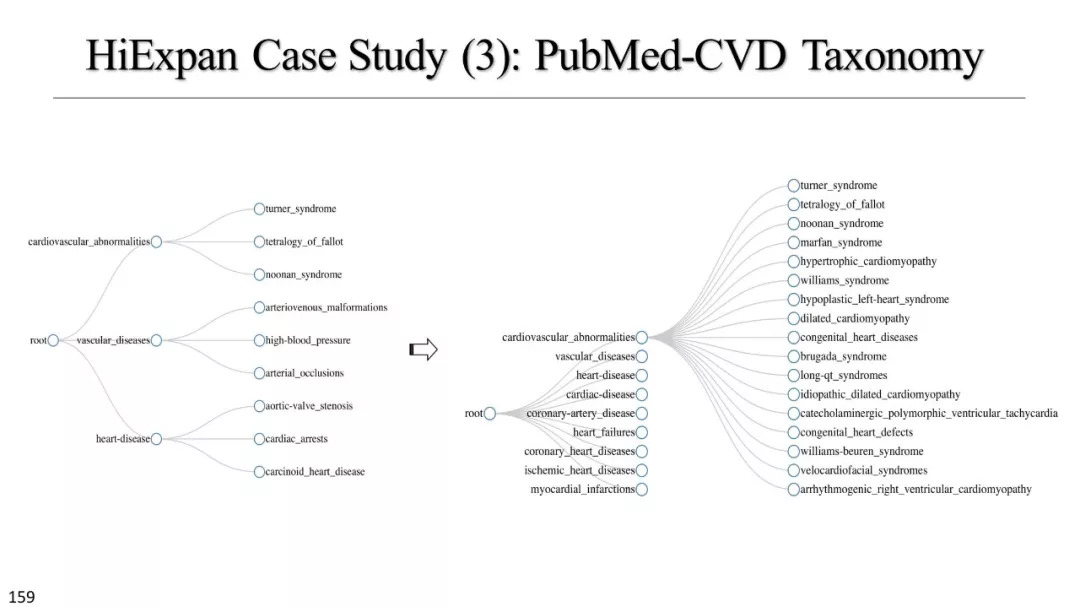
基于实例的分类学构建
使用资源概述
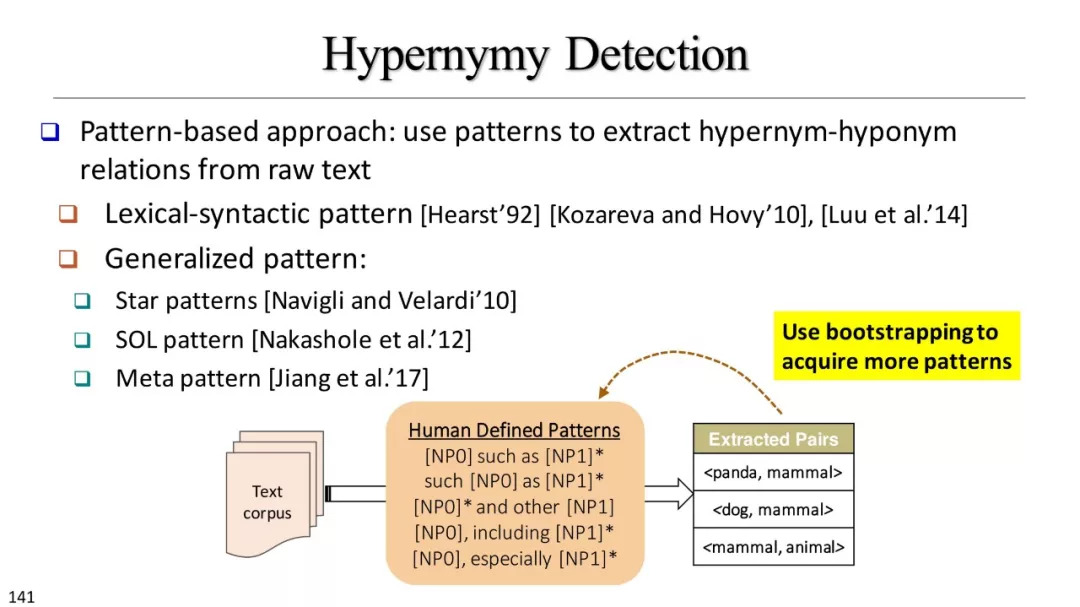
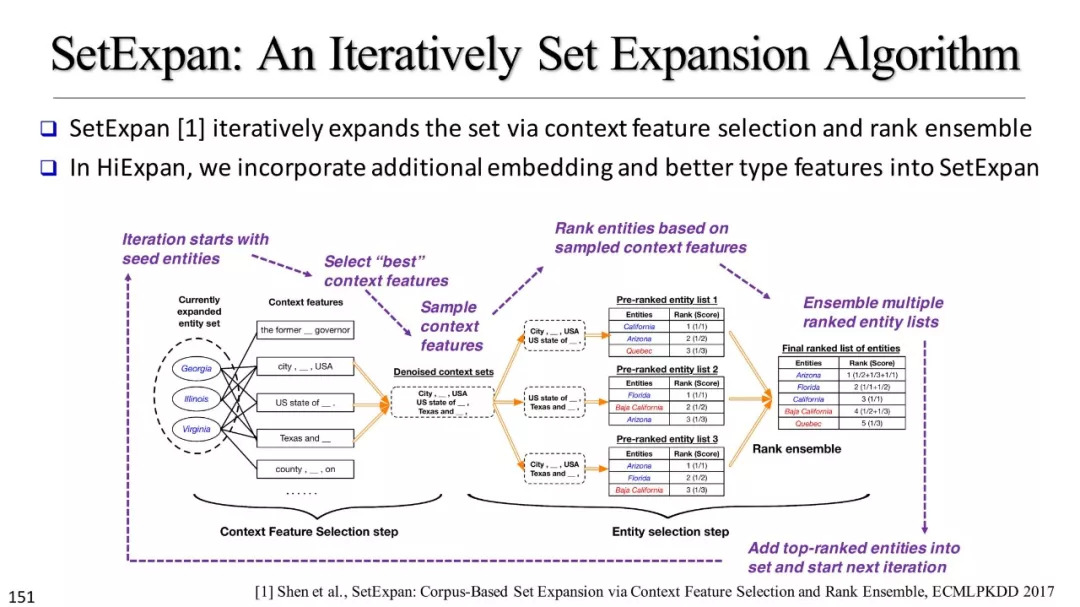
基于模式的方法
监督方法
弱监督方法
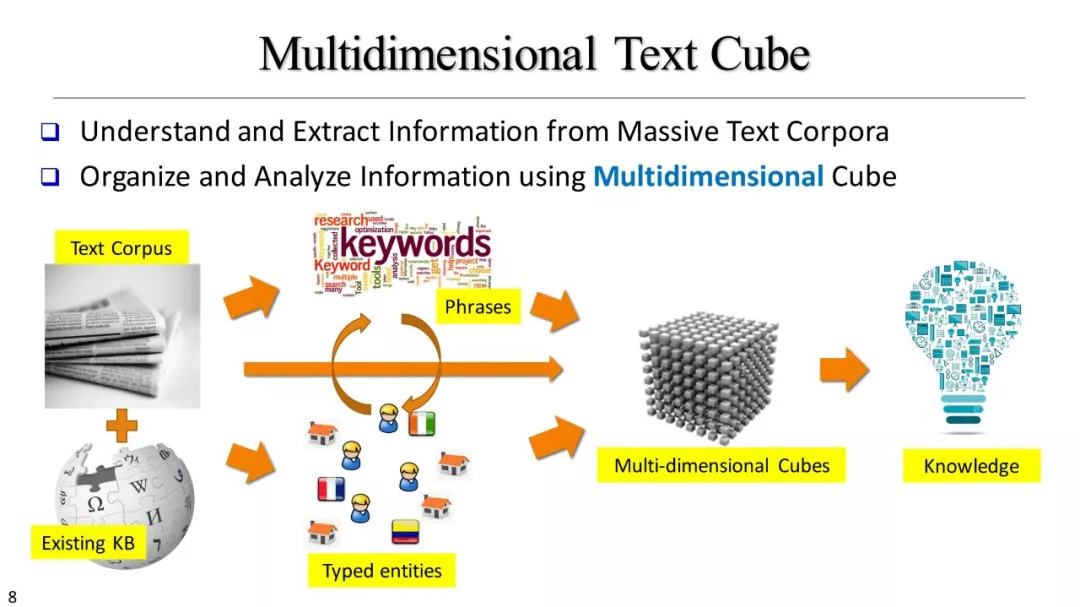
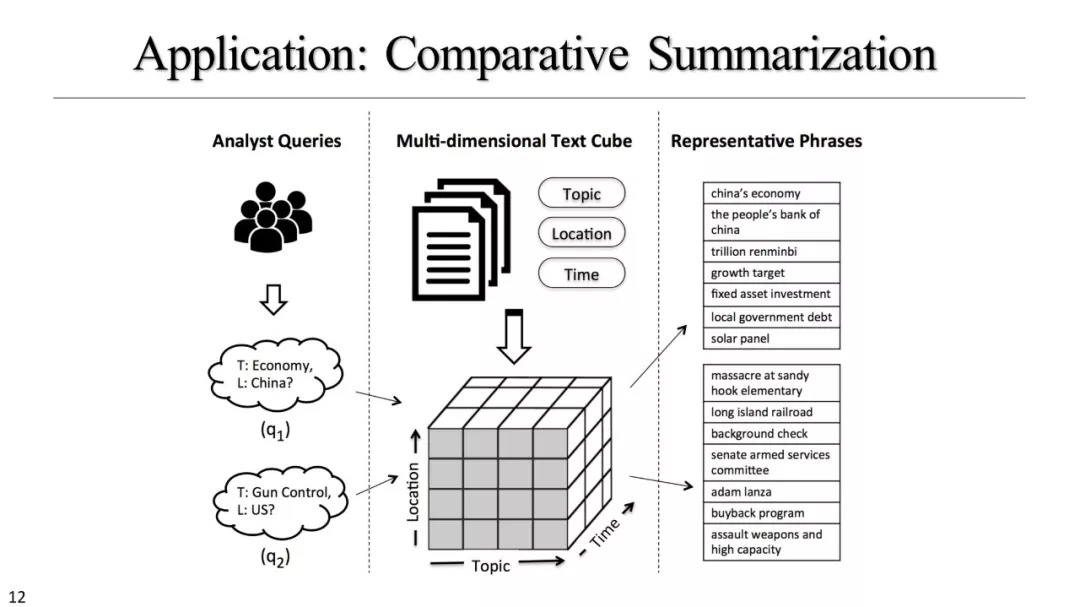
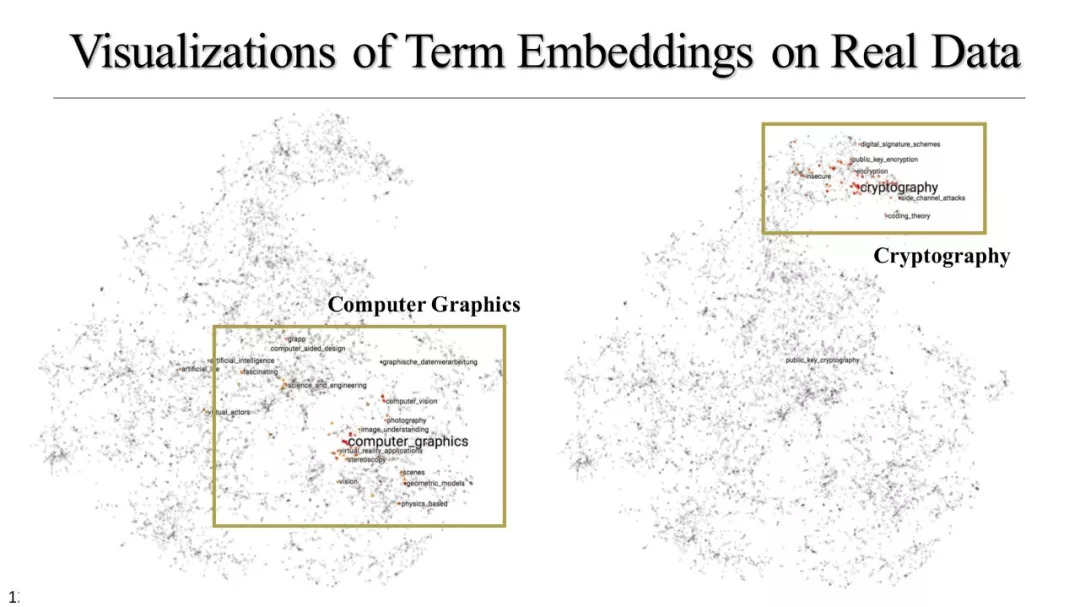
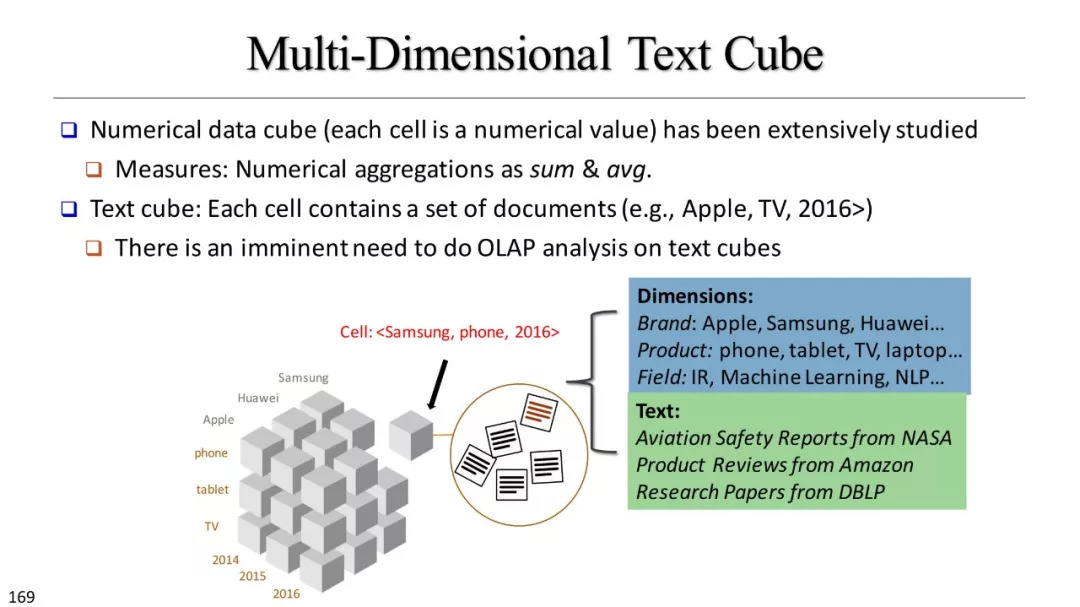
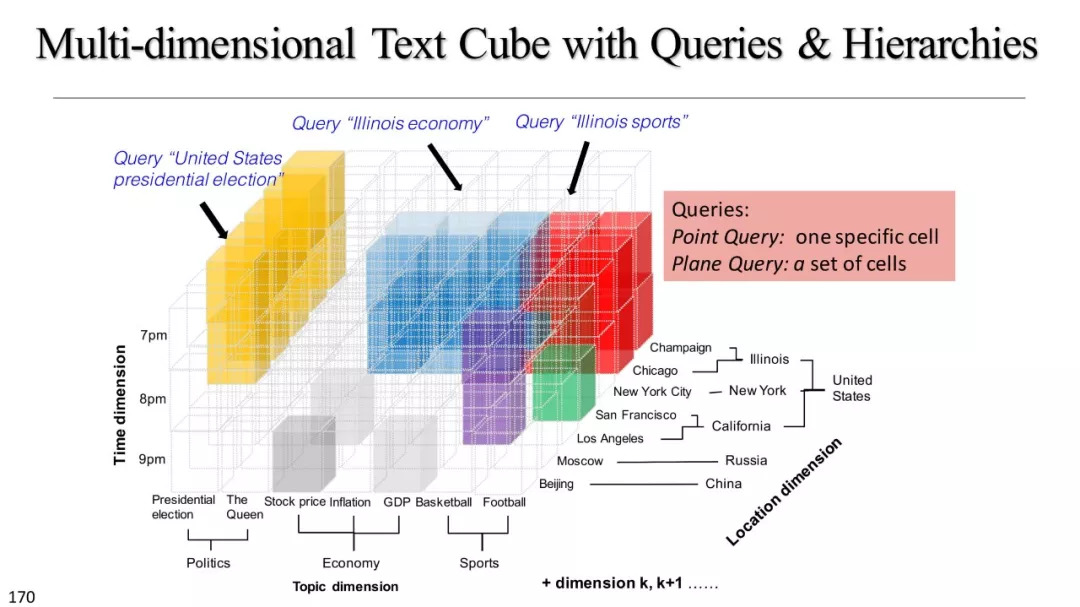
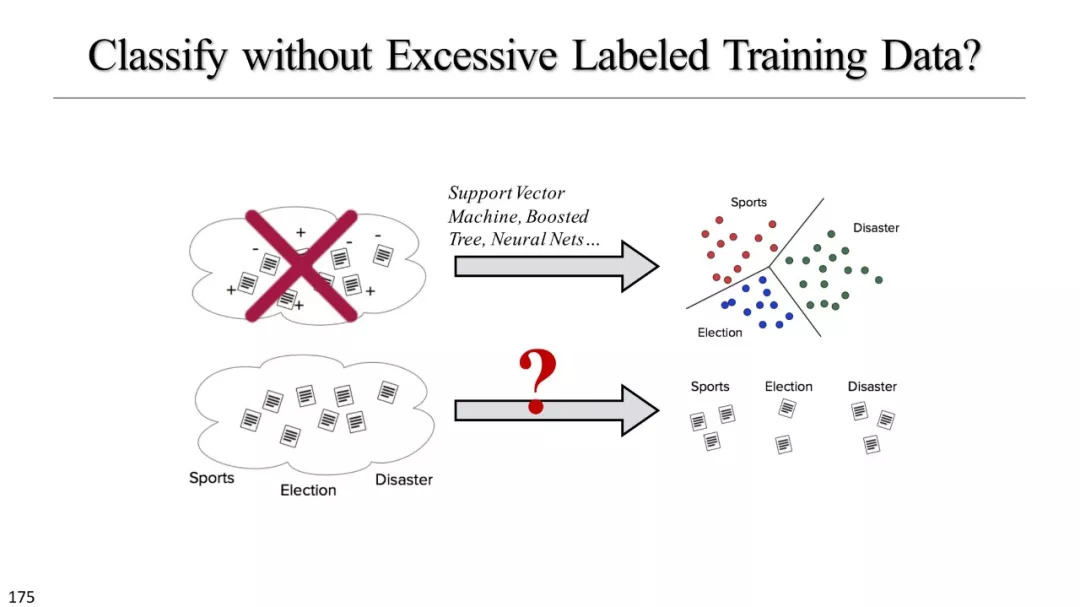
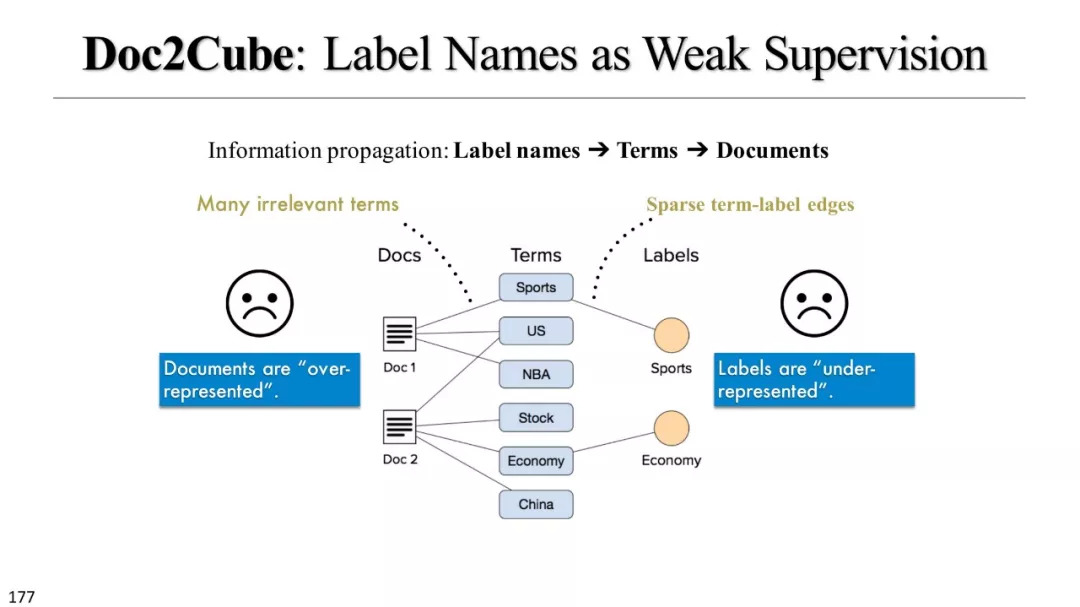
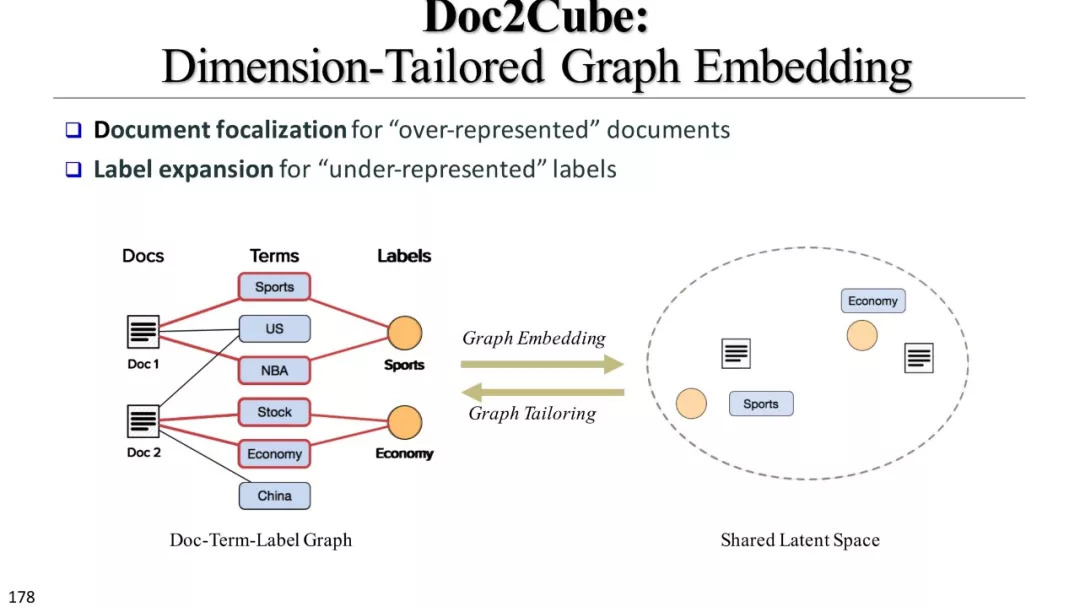
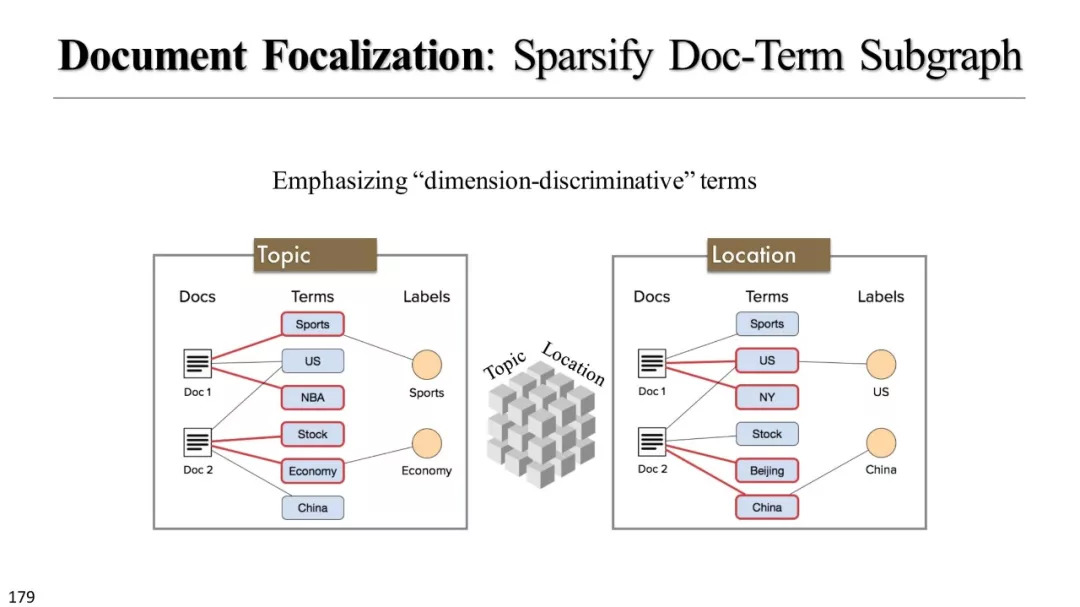
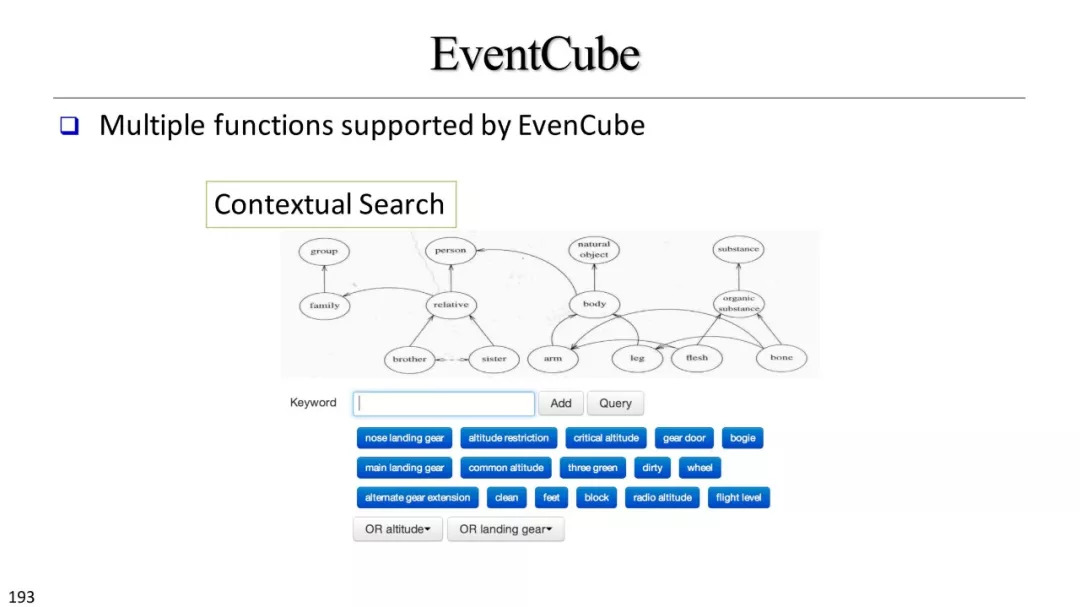
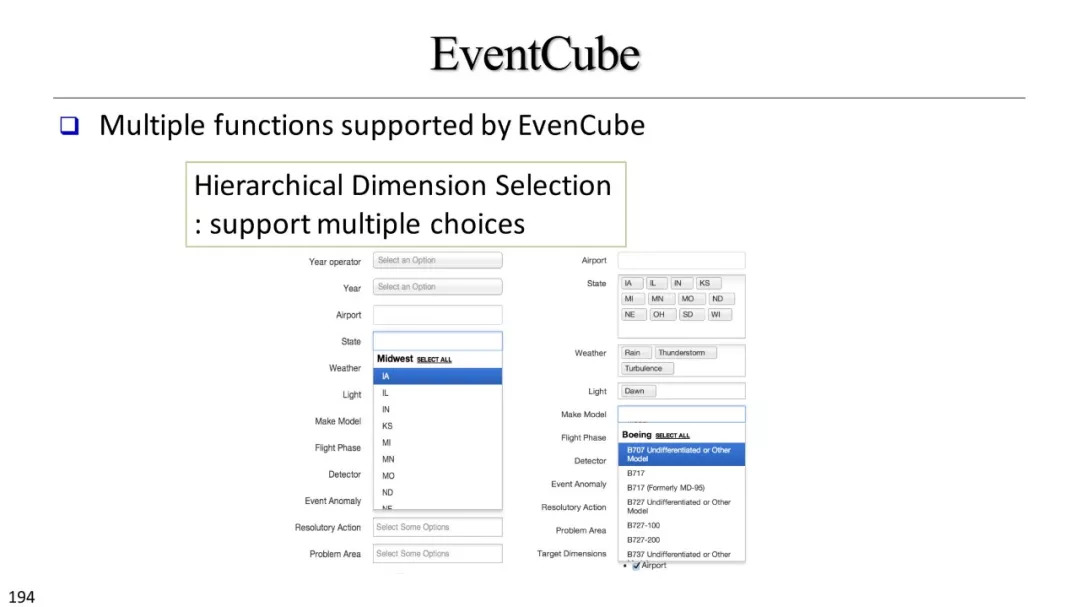
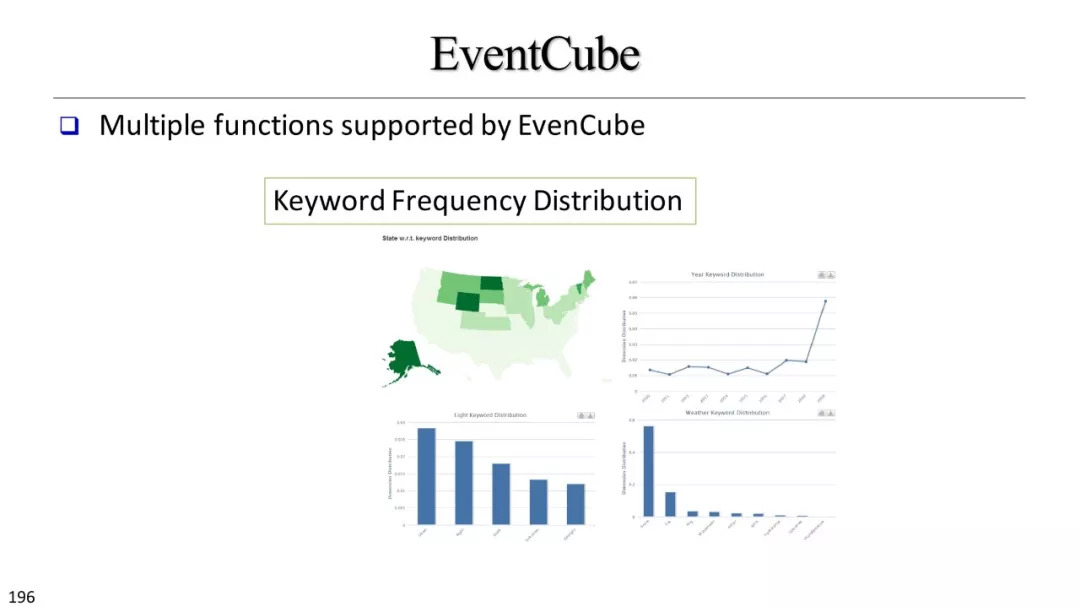
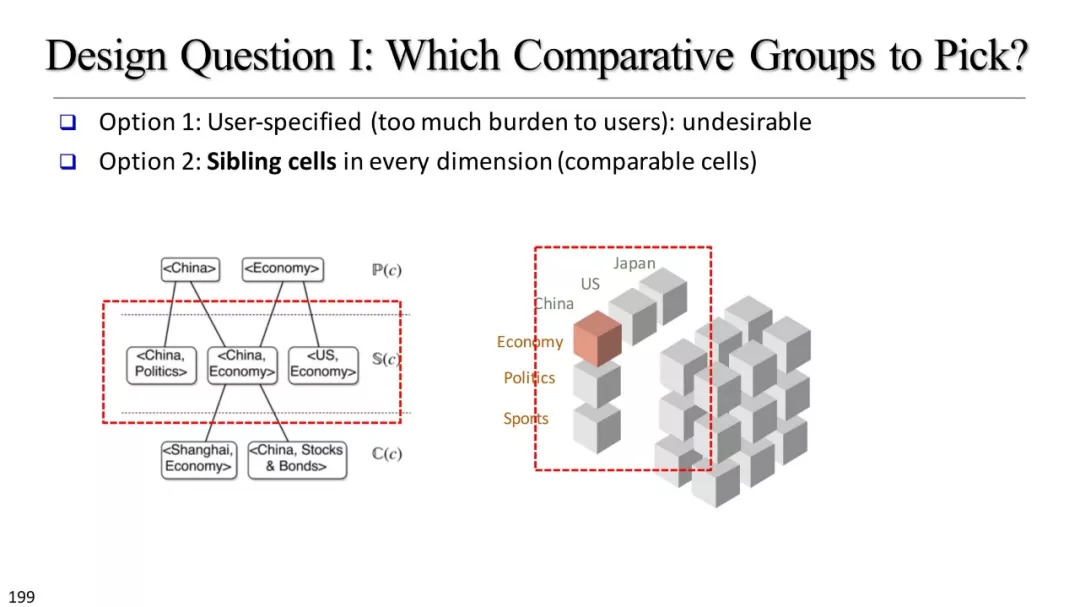
文本立方体构建以及有效知识发现的多维探索
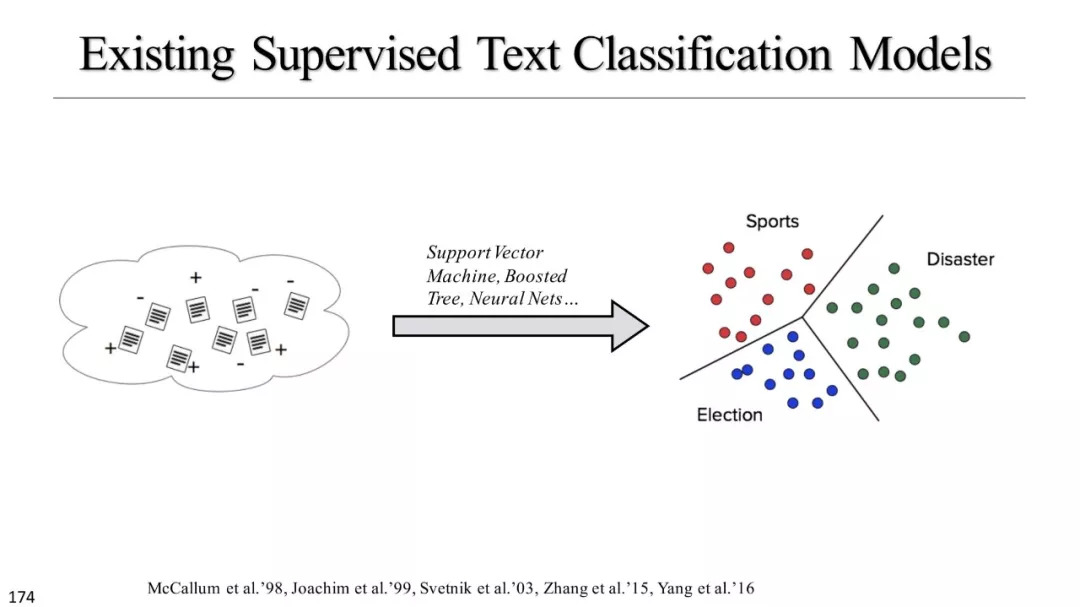
监督模型
文本分类模型
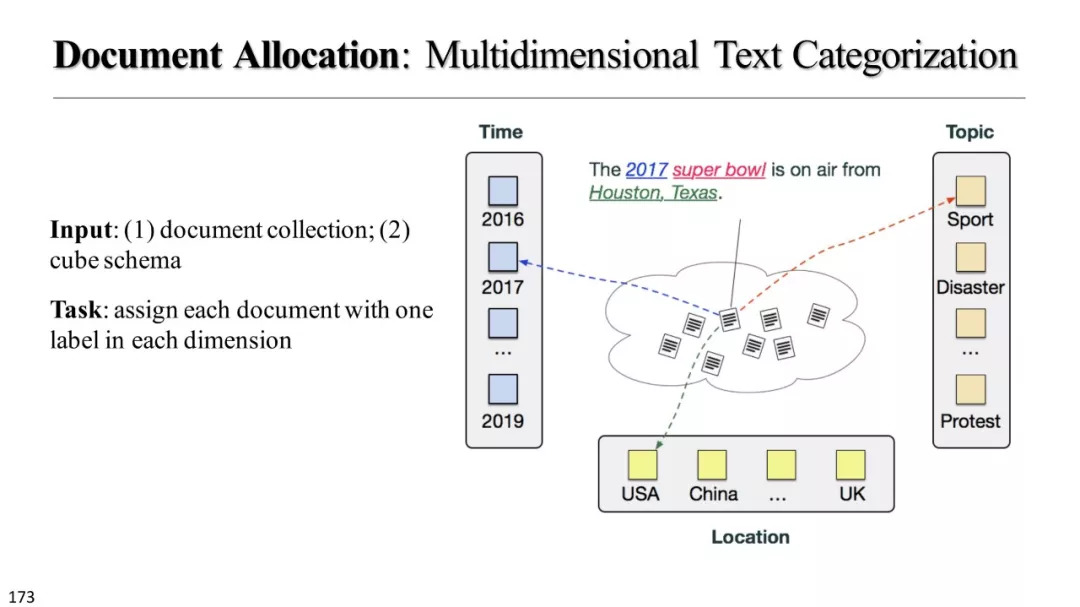
合适的立方体构建
弱监督和无监督模型
弱监督模型
无监督模型
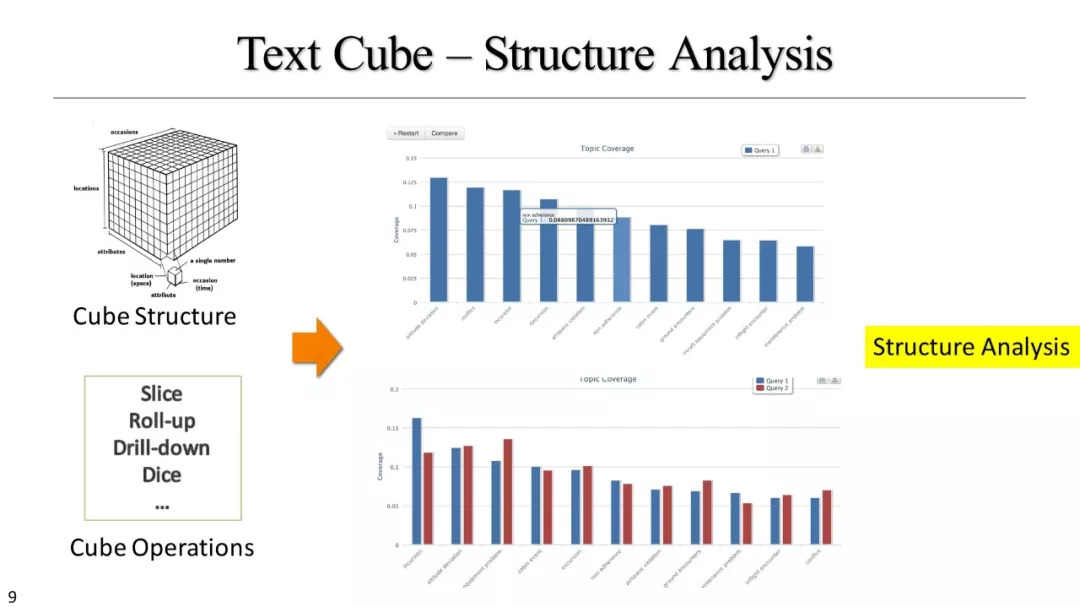
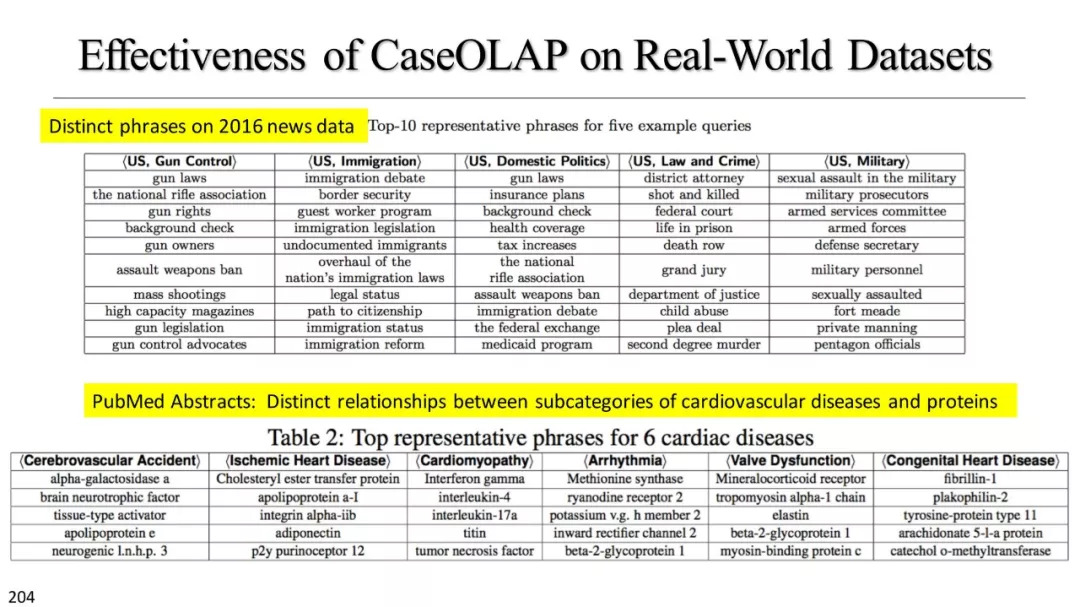
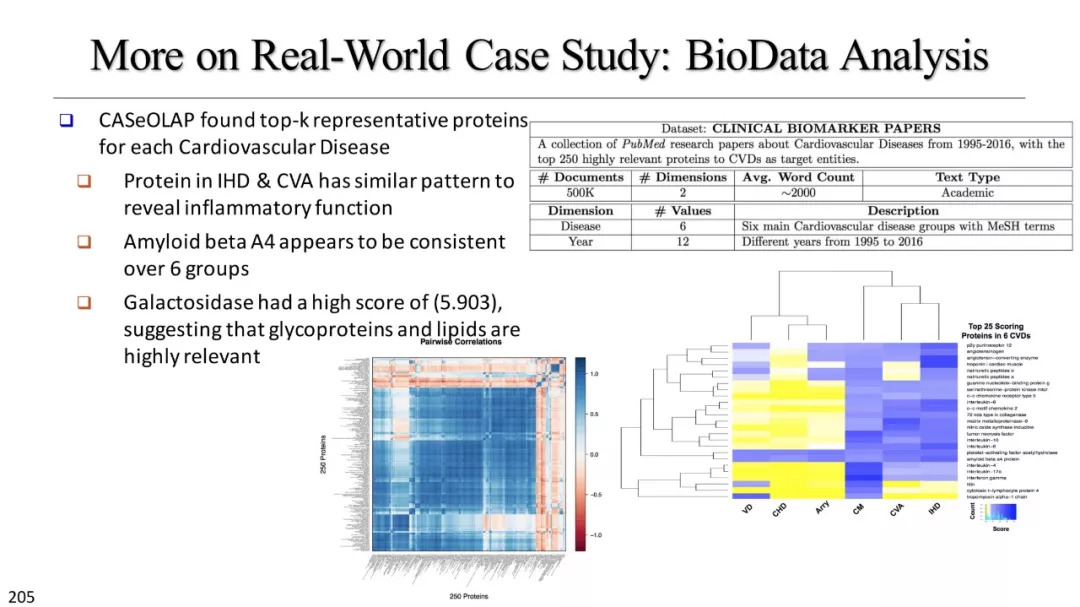
基于文本立方体的多维分析
统计方法汇总
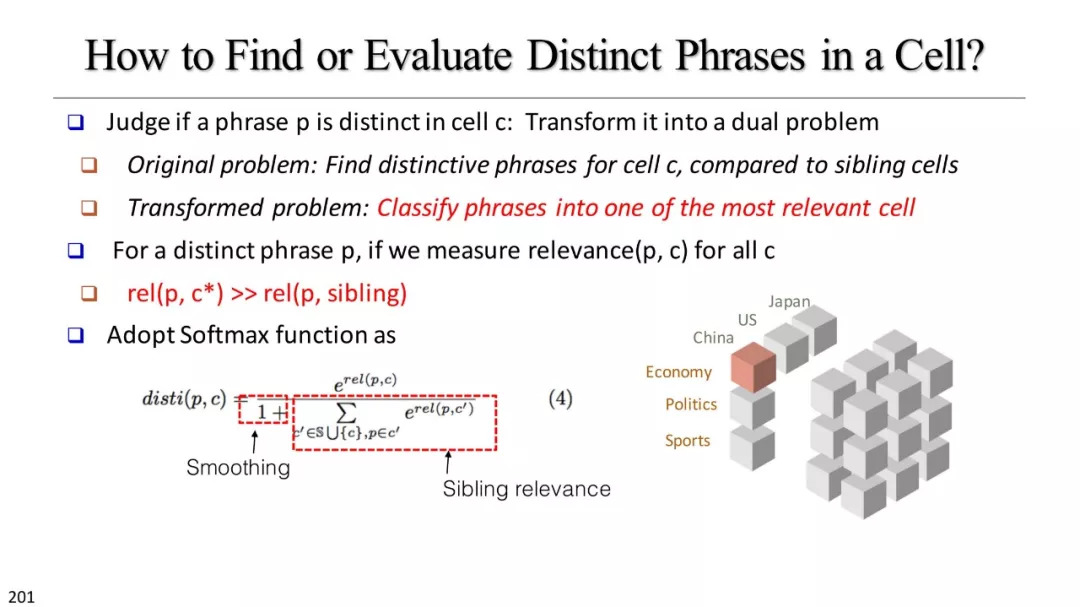
基于短语的细胞总结
基于N-gram的排名和探索
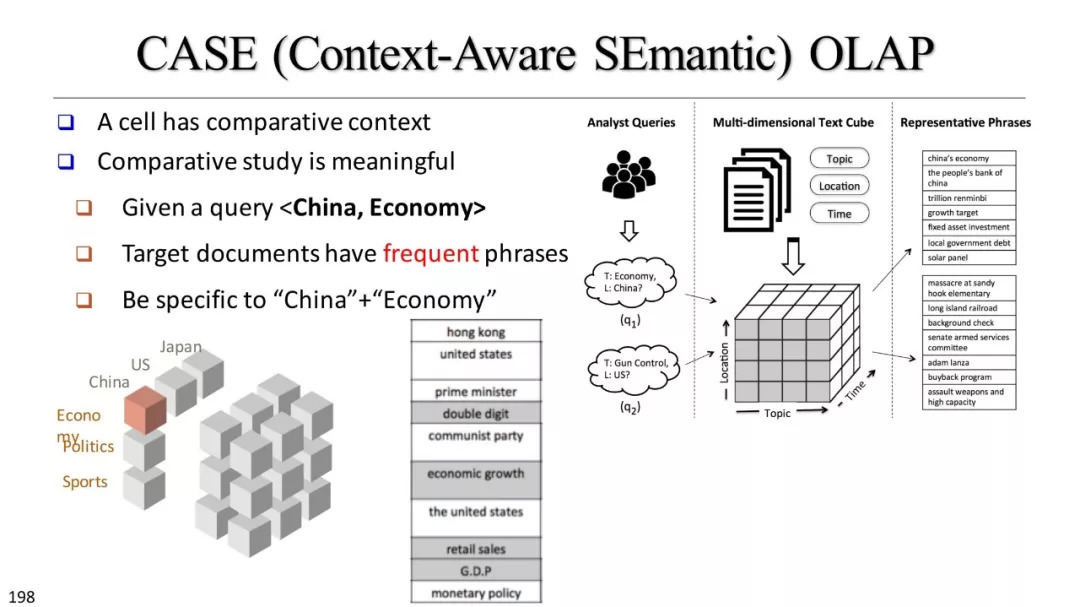
将文本立方体与HIN的整合
HIN潜入
cube-aided HIN嵌入和挖掘
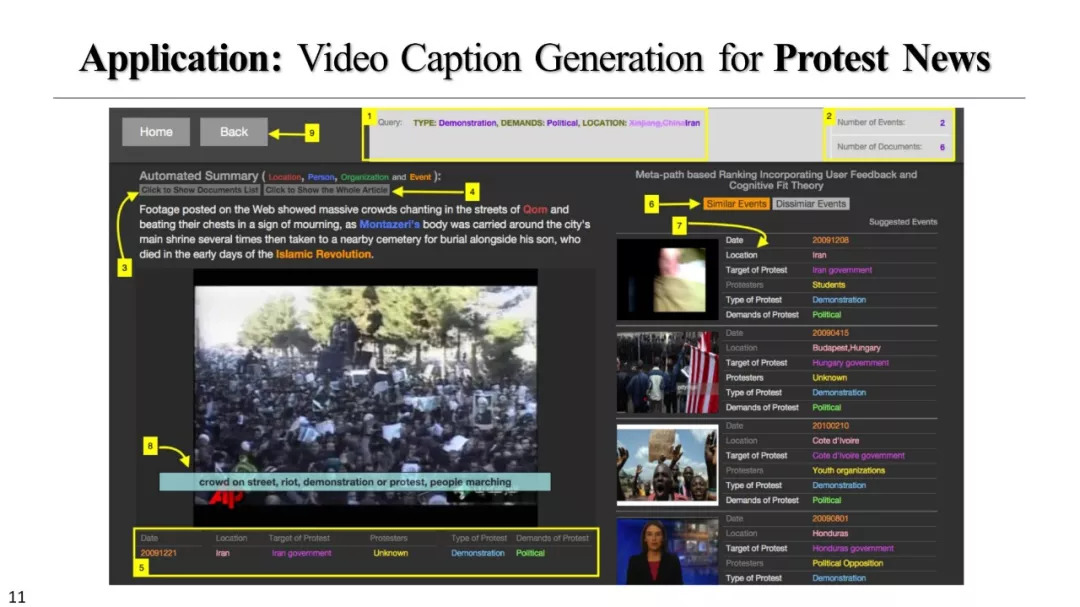
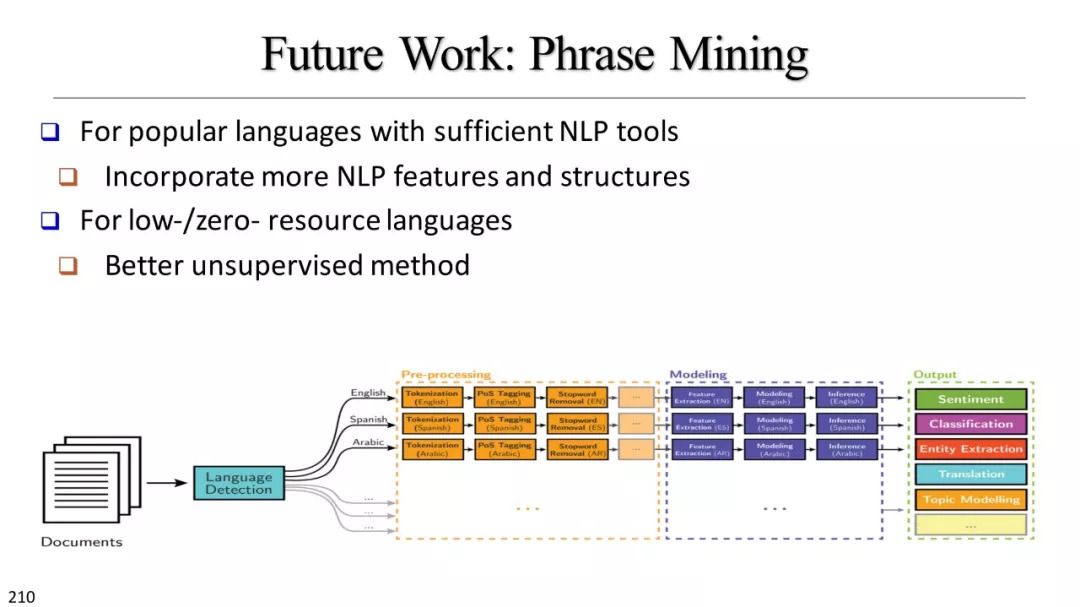
总结以及未来的方向
多维文本分析
原理和技术
优点和局限
如何基于你的应用选择合适的方法?
未来发展方向
作者简介
Jingbo Shang,伊利诺伊州香槟分校的博士生。研究重点是从大量文本语料库中挖掘和构建结构化知识。他于2017年获得Google全球博士学位结构化数据和数据库管理奖学金和Yelp数据集挑战大奖。
韩家炜,伊利诺伊大学计算机科学系教授,研究方向是数学挖掘,信息网络分析和数据库系统。曾担任TKDD的创始主编。获奖经历丰富,曾获得ACM SIGKDD创新奖(2004年),IEEE计算机学会技术成就奖(2005年),IEEE计算机学会W. Wallace McDowell奖(2009年),以及UIUC的Daniel C. Drucker杰出教师奖(2011年),ACM和IEEE Fellow,陆军研究实验室网络科学-写作技术联盟(NS-CTA)计划支持的信息网络学术研究中心(INARC)主任。
原文链接:
https://shangjingbo1226.github.io/2018-04-21-kdd-tutorial/
请关注专知公众号(扫一扫最下面专知二维码,或者点击上方蓝色专知),
后台回复“KDD2018MAT” 就可以获取最新PPT 下载链接~





































































































-END-
专 · 知
人工智能领域26个主题知识资料全集获取与加入专知人工智能服务群: 欢迎微信扫一扫加入专知人工智能知识星球群,获取专业知识教程视频资料和与专家交流咨询!

请PC登录www.zhuanzhi.ai或者点击阅读原文,注册登录专知,获取更多AI知识资料!

请加专知小助手微信(扫一扫如下二维码添加),加入专知主题群(请备注主题类型:AI、NLP、CV、 KG等)交流~

请关注专知公众号,获取人工智能的专业知识!
点击“阅读原文”,使用专知