
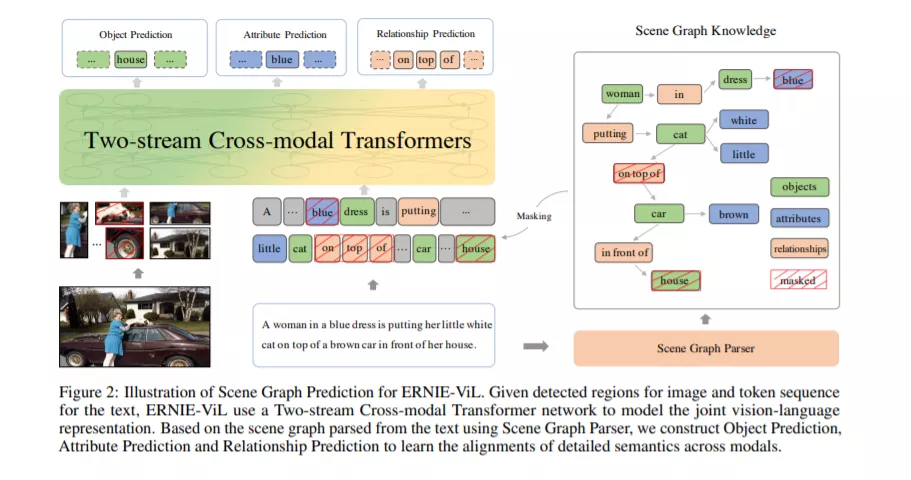
随着大规模无监督预训练技术在文本领域的各个任务上取得了显著的效果提升,视觉-语言预训练(Vision-language Pre-training)也受到了越来越多的关注。视觉-语言预训练的目标是通过对齐语料学习多模态的通用联合表示,将各个模态之间的语义对齐信号融合到联合表示中,从而提升下游任务效果。已有的视觉语言预训练方法在预训练过程中没有区分普通词和语义词,学到的联合表示无法刻画模态间细粒度语义的对齐,如场景中物体(objects)、物体属性(attributes)、物体间关系(relationships)这些深度理解场景所必备的细粒度语义。
我们提出了知识增强的视觉-语言预训练技术ERNIE-ViL,将包含细粒度语义信息的场景图先验知识融入预训练过程,创建了物体预测、属性预测、关系预测三个预训练任务,在预训练过程中更加关注细粒度语义的跨模态对齐,从而学习到能够刻画更好跨模态语义对齐信息的联合表示。作为业界首个融入场景图知识的视觉语言预训练模型,ERNIE-ViL在视觉问答、视觉常识推理、引用表达式理解、跨模态文本检索、跨模态图像检索5个多模态典型任务上取得了SOTA效果,同时,在视觉常识推理VCR榜单上取得第一。
https://www.zhuanzhi.ai/paper/3e78bfda818b0c967f692861d4b05386
成为VIP会员查看完整内容
相关内容
Arxiv
1+阅读 · 2021年3月19日
相关主题

相关VIP内容
相关资讯