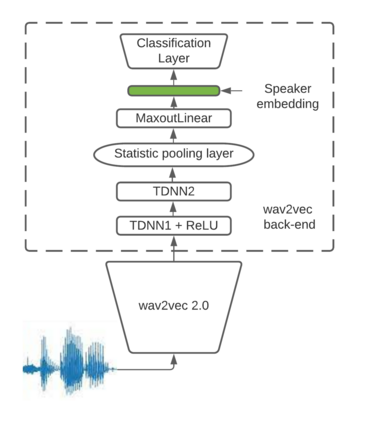
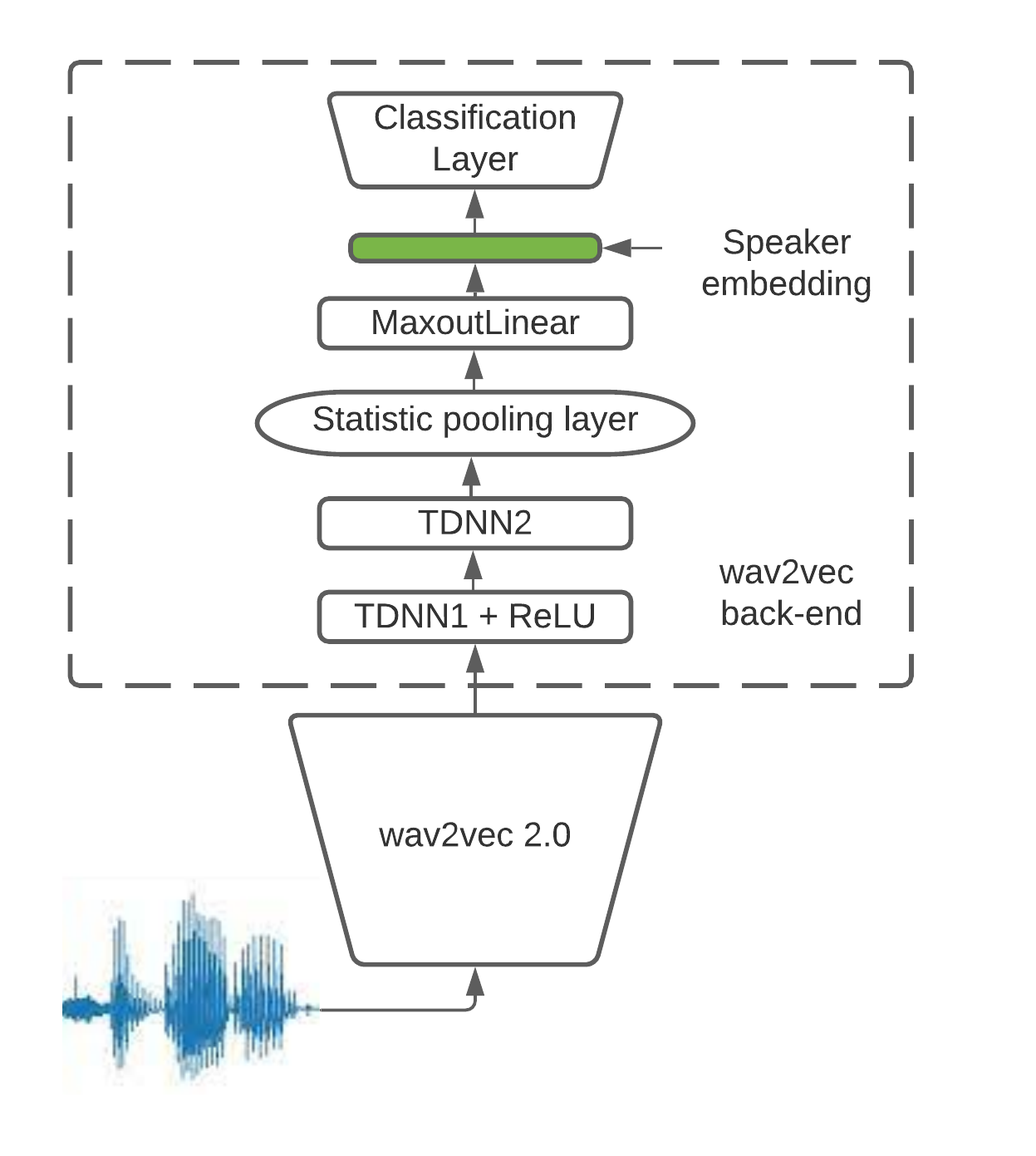
This paper presents a description of STC Ltd. systems submitted to the NIST 2021 Speaker Recognition Evaluation for both fixed and open training conditions. These systems consists of a number of diverse subsystems based on using deep neural networks as feature extractors. During the NIST 2021 SRE challenge we focused on the training of the state-of-the-art deep speaker embeddings extractors like ResNets and ECAPA networks by using additive angular margin based loss functions. Additionally, inspired by the recent success of the wav2vec 2.0 features in automatic speech recognition we explored the effectiveness of this approach for the speaker verification filed. According to our observation the fine-tuning of the pretrained large wav2vec 2.0 model provides our best performing systems for open track condition. Our experiments with wav2vec 2.0 based extractors for the fixed condition showed that unsupervised autoregressive pretraining with Contrastive Predictive Coding loss opens the door to training powerful transformer-based extractors from raw speech signals. For video modality we developed our best solution with RetinaFace face detector and deep ResNet face embeddings extractor trained on large face image datasets. The final results for primary systems were obtained by different configurations of subsystems fusion on the score level followed by score calibration.
翻译:本文介绍了向NIST 2021 发言人确认评价有限公司提交的固定和开放式培训条件的STC Ltd系统,这些系统包括若干基于使用深神经网络作为特征提取器的不同子系统。在 NIST 2021 SRE 挑战期间,我们的重点是通过使用基于RESNets和ECAPA网络等最先进的深声器嵌入器提取器的培训,为此使用了基于抗抗控的三角边偏差损失功能。此外,由于在自动语音识别中的 wav2vec 2.0 功能最近取得了成功,我们探索了这一方法对所提交演讲者核查的有效性。根据我们的观察,对预先训练的大型 wav2vec 2. 0 模式的微调为我们提供了最佳的开放轨道条件系统。我们用基于 ResNets 和 ECAPA 的基于固定条件的 wav2 2. 0 提取器进行的实验表明,通过抗控性自控性磁力前训练,为从原始语音信号中培训强大的变压器提取器的提取器打开了大门。 对于视频模式,我们与Retinaface 脸探测器和深ResNet 脸嵌入式2.0系统的最佳解决方案, 遵循了通过大图像升级升级的升级的升级系统最终的升级配置。