
题目: Multiresolution and Multimodal Speech Recognition with Transformers
摘要:
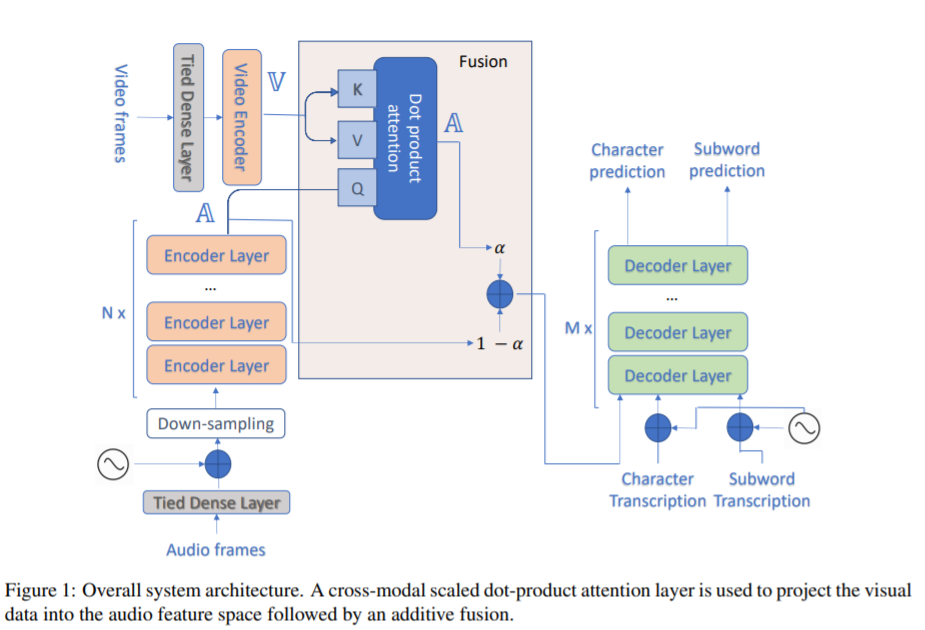
本文提出了一种基于transformers的语音自动识别系统。我们特别关注场景上下文所提供的视觉信息,以集成ASR。我们在transformers的编码器层提取音频特征的表示,并使用一个额外的跨模态多头注意层融合视频特征。此外,我们为多分辨率ASR合并了一个多任务训练标准,在那里我们训练模型来生成字符和子单词级别的转录。
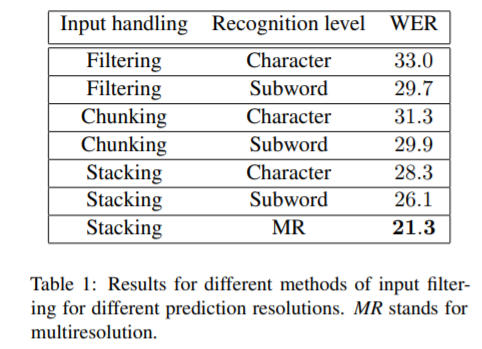
在How2数据集上的实验结果表明,与子单词预测模型相比,多分辨率训练可以加快约50%的收敛速度,并相对提高高达18%的单词错误率(WER)性能。此外,与纯音频模型相比,集成视觉信息可以提高性能,相对提高3.76%。其成果可与最先进的聆听、聆听和基于拼写的体系结构相媲美。
成为VIP会员查看完整内容
相关内容
专知会员服务
43+阅读 · 2020年1月28日
专知会员服务
33+阅读 · 2020年1月5日
专知会员服务
23+阅读 · 2019年11月26日
Arxiv
7+阅读 · 2019年4月18日


相关VIP内容
专知会员服务
43+阅读 · 2020年1月28日
专知会员服务
33+阅读 · 2020年1月5日
专知会员服务
23+阅读 · 2019年11月26日
相关资讯
相关论文
Arxiv
7+阅读 · 2019年4月18日