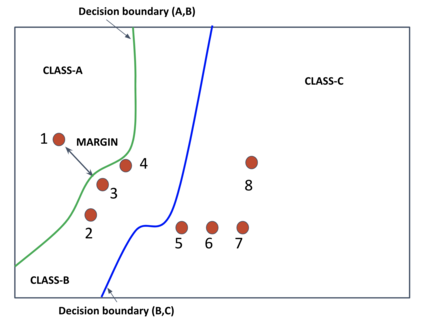
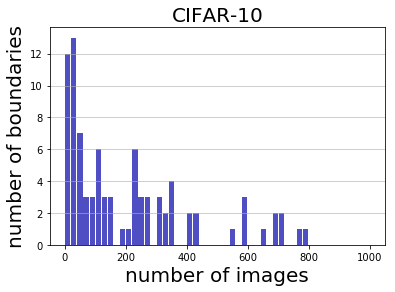
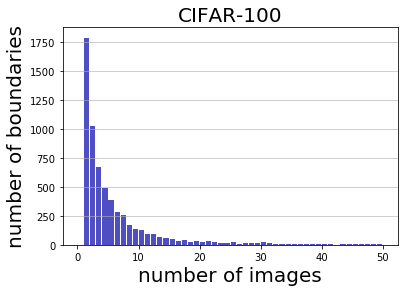
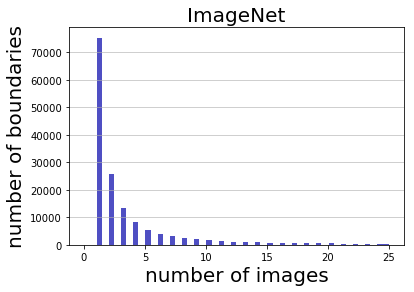
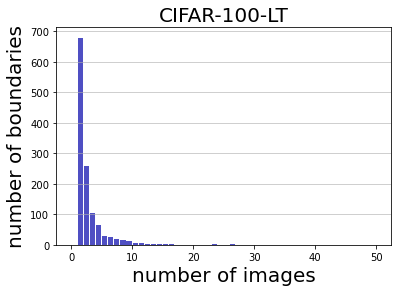
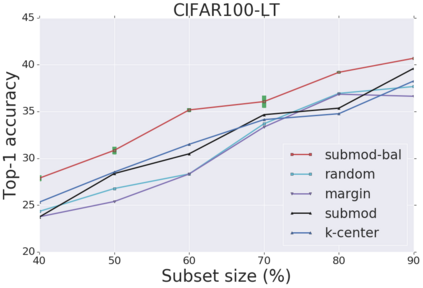
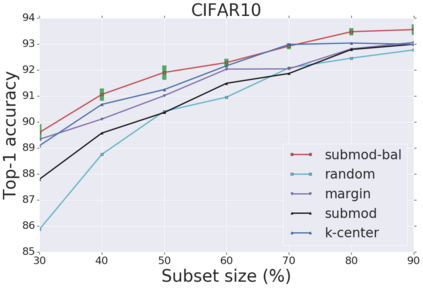
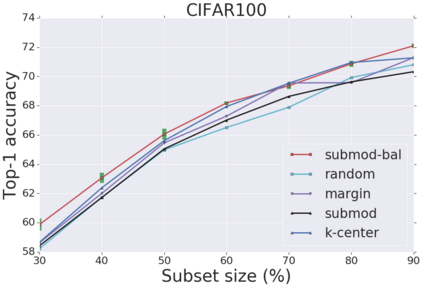
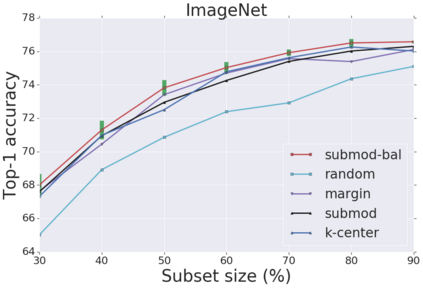
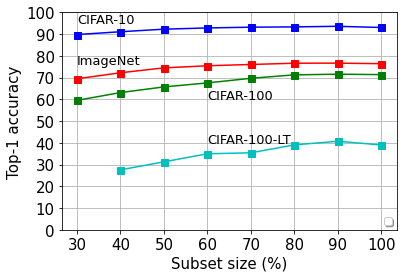
Deep learning has yielded extraordinary results in vision and natural language processing, but this achievement comes at a cost. Most models require enormous resources during training, both in terms of computation and in human labeling effort. We show that we can identify informative and diverse subsets of data that lead to deep learning models with similar performance as the ones trained with the original dataset. Prior methods have exploited diversity and uncertainty in submodular objective functions for choosing subsets. In addition to these measures, we show that balancing constraints on predicted class labels and decision boundaries are beneficial. We propose a novel formulation of these constraints using matroids, an algebraic structure that generalizes linear independence in vector spaces, and present an efficient greedy algorithm with constant approximation guarantees. We outperform competing baselines on standard classification datasets such as CIFAR-10, CIFAR-100, ImageNet, as well as long-tailed datasets such as CIFAR-100-LT.
翻译:深层次的学习在视觉和自然语言处理方面产生了不同寻常的结果,但这一成绩是有代价的。大多数模型在培训期间都需要大量资源,包括计算和人类标签工作。我们表明,我们可以确定信息丰富和多样的数据子集,从而导致深层次的学习模型,其性能与接受原始数据集培训的模型相似。以前的方法利用亚模式目标功能的多样性和不确定性来选择子集。除了这些措施外,我们还表明平衡预测类标签和决定界限的限制是有好处的。我们提议用类固醇这一代谢结构对这些限制因素进行新颖的表述,这种代谢结构将矢量空间的线性独立概括化,并提出一种高效的贪婪算法,并不断提供近距离保证。我们在标准分类数据集(如CIFAR-10、CIFAR-100、图像网)和长尾数据集(如CIFAR-100-LT)上建立了相互竞争的基线。