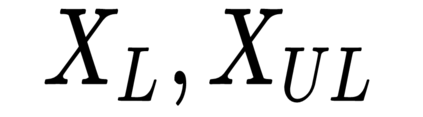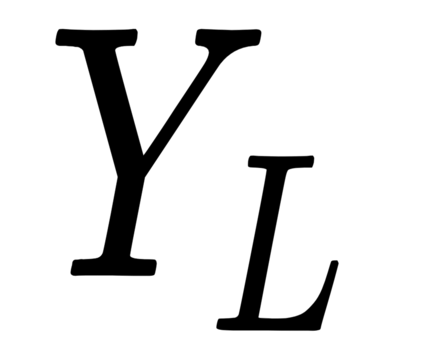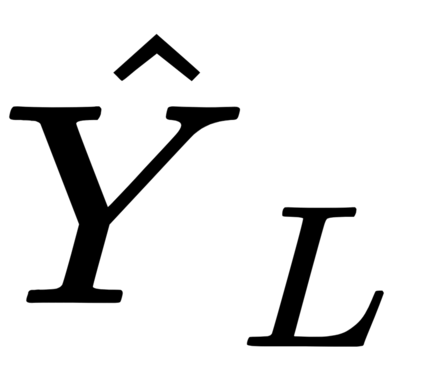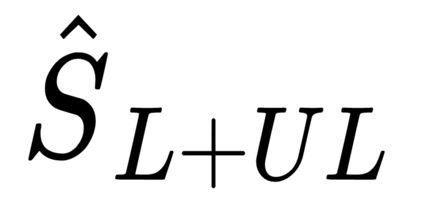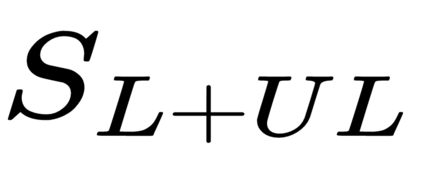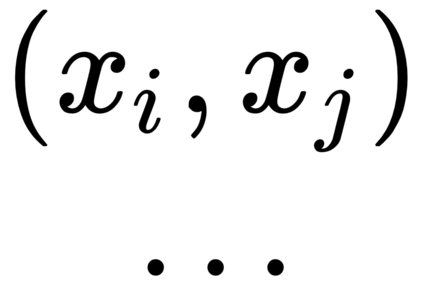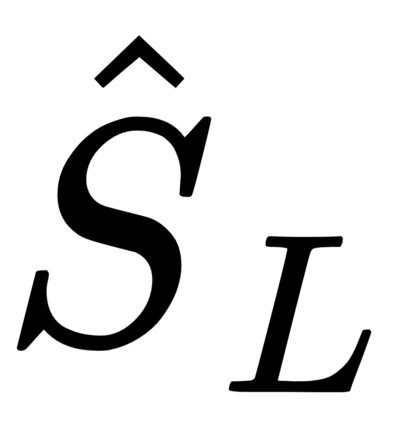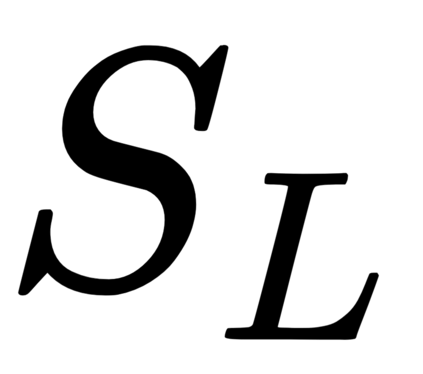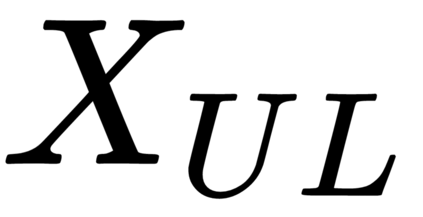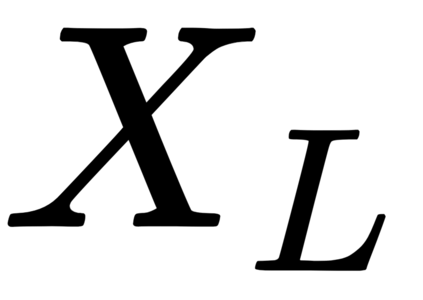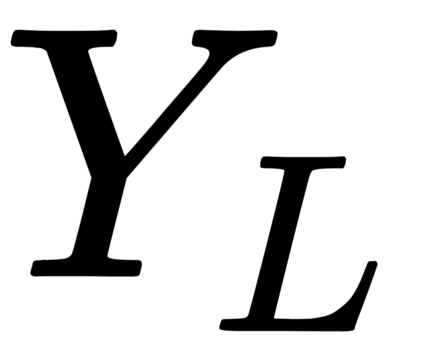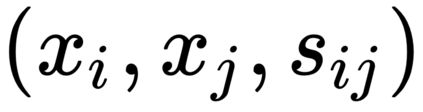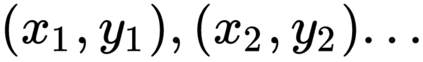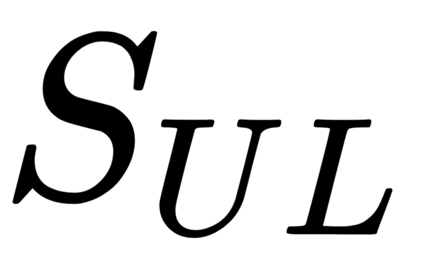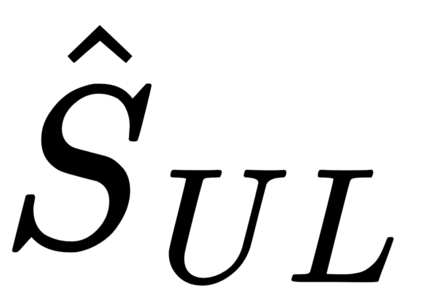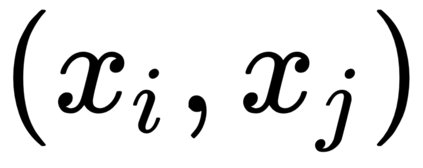This work presents a new strategy for multi-class classification that requires no class-specific labels, but instead leverages pairwise similarity between examples, which is a weaker form of annotation. The proposed method, meta classification learning, optimizes a binary classifier for pairwise similarity prediction and through this process learns a multi-class classifier as a submodule. We formulate this approach, present a probabilistic graphical model for it, and derive a surprisingly simple loss function that can be used to learn neural network-based models. We then demonstrate that this same framework generalizes to the supervised, unsupervised cross-task, and semi-supervised settings. Our method is evaluated against state of the art in all three learning paradigms and shows a superior or comparable accuracy, providing evidence that learning multi-class classification without multi-class labels is a viable learning option.
翻译:这项工作为多级分类提出了一个新的战略, 不需要特定类别标签, 而是要利用不同实例之间的对称相似性, 这是一种较弱的注解形式。 拟议的方法, 元分类学习, 优化双级分类器, 以进行双级相似性预测, 并通过这一过程学习多级分类器作为子模块。 我们制定这个方法, 为它提供一个概率化的图形模型, 并得出一个惊人的简单损失函数, 可用于学习神经网络模型。 我们然后证明这个框架将常规化为受监督、 不受监督的跨任务和半监督的设置。 我们的方法在所有三种学习模式中都根据最新技术来评估, 并显示优劣或可比的准确性, 提供证据证明学习没有多级标签的多级分类是一种可行的学习选项 。