读书报告 | Deep Learning for Extreme Multi-label Text Classification

SIGIR 2017 FULL
链接:https://dl.acm.org/citation.cfm?id=3080834
一、背景介绍
1、研究背景:Multi-label和二分类、多分类研究的内容本身就不太一样,并且Multi-label的数据稀疏问题比单一分类更严重,因此很难学习label之间的依赖关系。
2、研究问题:Extreme Multi-label Text Classification(XMTC)研究的是在一个非常大的标签空间中,为每一个文档找到最相关的若干标签(例如Wikipedia)
3、相关工作:之前较为成熟的方法主要分为两大类(Target-Embedding和Tree-based Ensemble,如:SLEEC、FastXML、FastText、CNN-Kim、Bow-CNN、PD-Sparse),Deep Learning在文本分类上有一些工作,但没有考虑过XMTC问题
4、主要贡献:1)在6个数据集上实验对比了7个baseline;2)提出了XML-CNN,利用multi-label的共现性,对loss和网络结构进行优化;3)实验证明了模型在XMTC任务上的有效性
二、算法模型
1、基本框架:本文提出的模型其实是在CNN-Kim的基础上做的改进,从multi-class延伸到multi-label
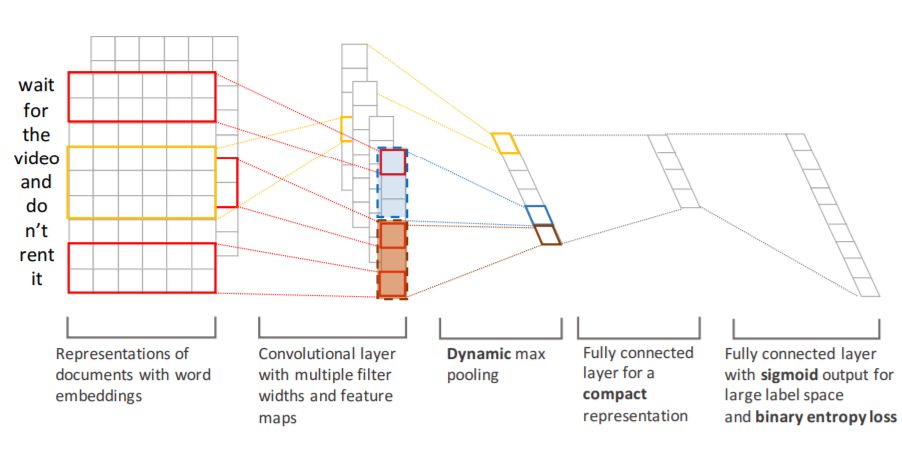
2、模型细节:Pooling用的chunk-max pooling,Loss Function用的是cross entropy对于多标签的扩展,pooling layer和output layer之间加了一层全连接的隐层(文章中称之为Hidden Bottleneck Layer)
三、实验结果
1、数据集:6个benchmark,有不同的样本大小、标签数、文本长度
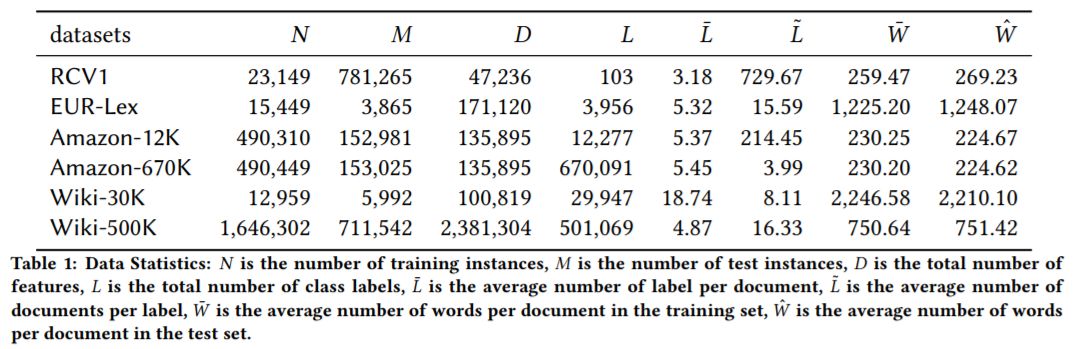
2、综合实验结果来看:XML-CNN能解决标签很多的时候产生的数据稀疏问题;特别设计的pooling、网络结构、loss设计起到了正向作用;训练时间也不算太慢
作者:朱纪乐,北京大学在读硕士,研究方向为教育数据挖掘、推荐系统





