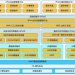
The rapid advancement of big data technologies has underscored the need for robust and efficient data processing solutions. Traditional Spark-based Platform-as-a-Service (PaaS) solutions, such as Databricks and Amazon Web Services Elastic MapReduce, provide powerful analytics capabilities but often result in high operational costs and vendor lock-in issues. These platforms, while user-friendly, can lead to significant inefficiencies due to their cost structures and lack of transparent pricing. This paper introduces a cost-effective and flexible orchestration framework using Dagster. Our solution aims to reduce dependency on any single PaaS provider by integrating various Spark execution environments. We demonstrate how Dagster's orchestration capabilities can enhance data processing efficiency, enforce best coding practices, and significantly reduce operational costs. In our implementation, we achieved a 12% performance improvement over EMR and a 40% cost reduction compared to DBR, translating to over 300 euros saved per pipeline run. Our goal is to provide a flexible, developer-controlled computing environment that maintains or improves performance and scalability while mitigating the risks associated with vendor lock-in. The proposed framework supports rapid prototyping and testing, which is essential for continuous development and operational efficiency, contributing to a more sustainable model of large data processing.
翻译:暂无翻译