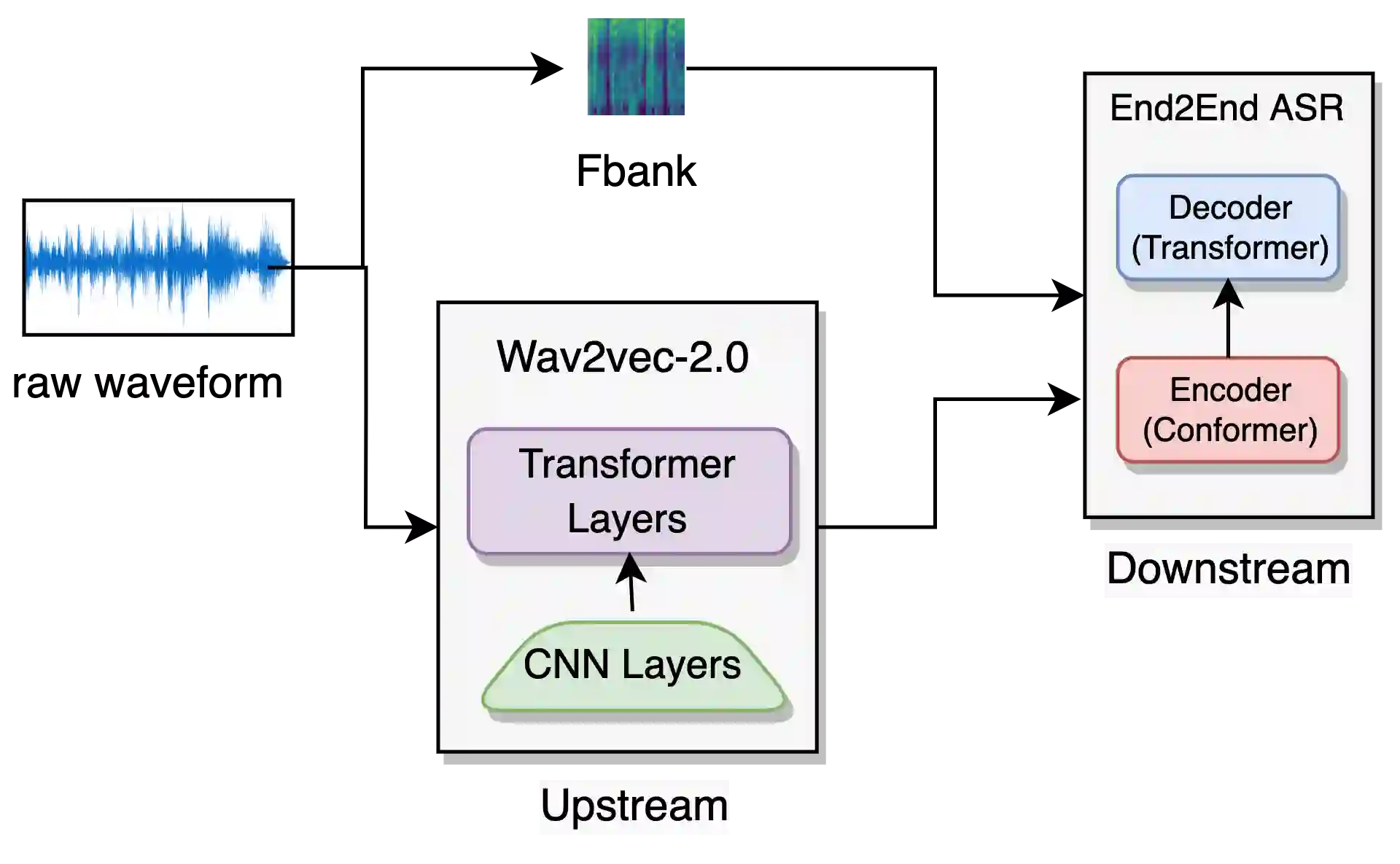
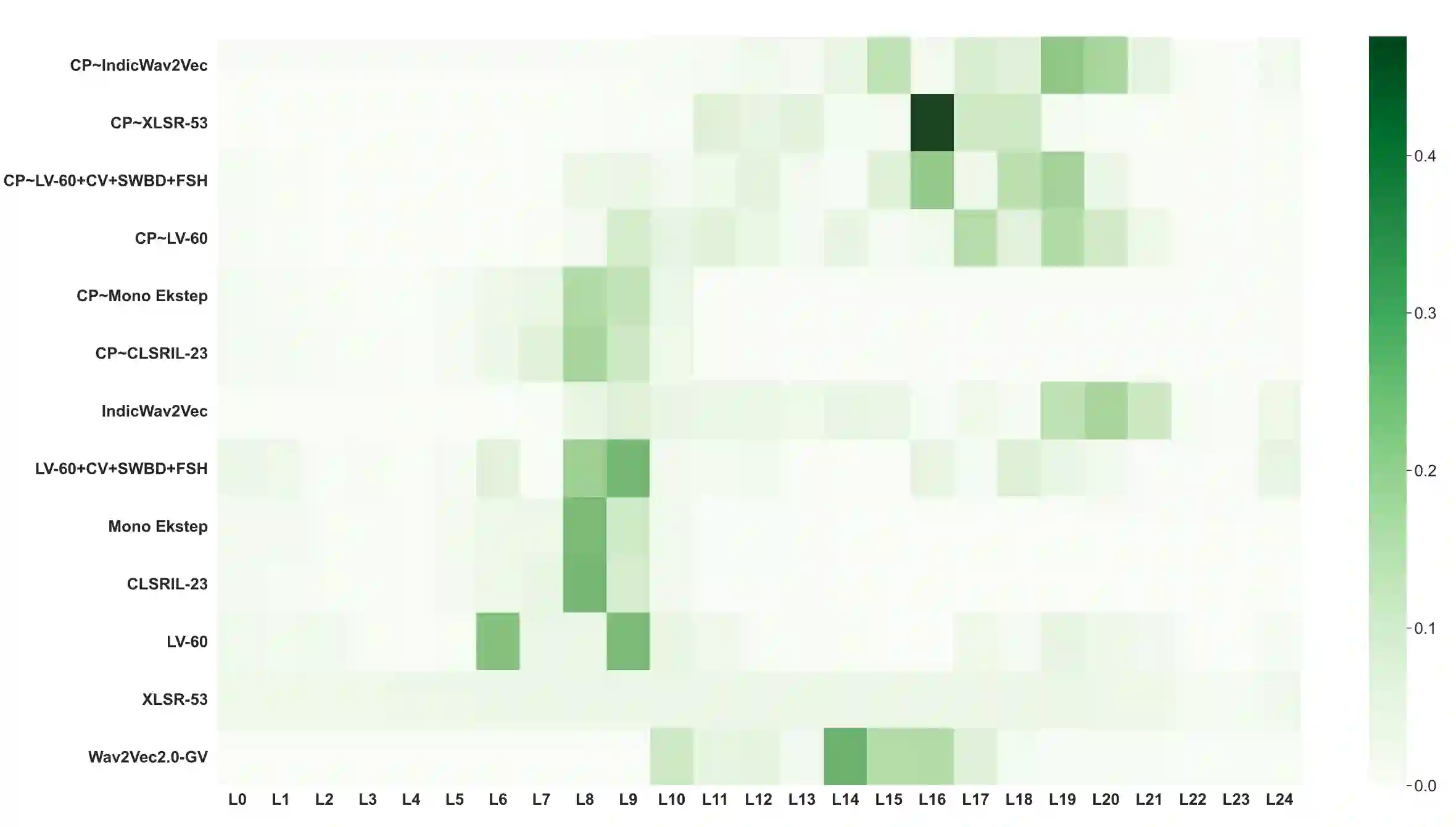
Self-supervised learning (SSL) to learn high-level speech representations has been a popular approach to building Automatic Speech Recognition (ASR) systems in low-resource settings. However, the common assumption made in literature is that a considerable amount of unlabeled data is available for the same domain or language that can be leveraged for SSL pre-training, which we acknowledge is not feasible in a real-world setting. In this paper, as part of the Interspeech Gram Vaani ASR challenge, we try to study the effect of domain, language, dataset size, and other aspects of our upstream pre-training SSL data on the final performance low-resource downstream ASR task. We also build on the continued pre-training paradigm to study the effect of prior knowledge possessed by models trained using SSL. Extensive experiments and studies reveal that the performance of ASR systems is susceptible to the data used for SSL pre-training. Their performance improves with an increase in similarity and volume of pre-training data. We believe our work will be helpful to the speech community in building better ASR systems in low-resource settings and steer research towards improving generalization in SSL-based pre-training for speech systems.
翻译:在低资源环境下建立自动语音识别系统(ASR)的流行做法是学习高层次演讲代表的自监督学习(SSL),但是,文献中的共同假设是,在同一个领域或可用于SSL培训前培训的语文中,有大量未贴标签的数据可用,我们承认,在现实环境中,这些数据不可行。在本文中,作为Interspeech Gram Vaani ASR挑战的一部分,我们试图研究我们上游SLS培训前数据对最后的低资源下游性能任务的影响、语言、数据集大小和其他方面。我们还利用持续的培训前模式,研究使用SSL培训前培训模型所具备的先前知识的影响。广泛的实验和研究显示,ASR系统的性能很容易受到SSL培训前培训所用数据的影响。这些系统的性能随着培训前数据的相似性和数量增加而得到改善。我们认为,我们的工作将有助于语言界在低资源环境中建立更好的ASL系统,并指导研究改进基于SSL的语音系统的一般化。