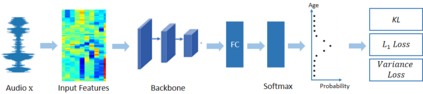
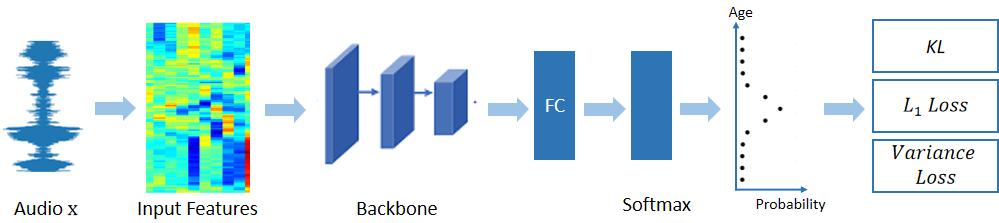
Existing methods for speaker age estimation usually treat it as a multi-class classification or a regression problem. However, precise age identification remains a challenge due to label ambiguity, \emph{i.e.}, utterances from adjacent age of the same person are often indistinguishable. To address this, we utilize the ambiguous information among the age labels, convert each age label into a discrete label distribution and leverage the label distribution learning (LDL) method to fit the data. For each audio data sample, our method produces a age distribution of its speaker, and on top of the distribution we also perform two other tasks: age prediction and age uncertainty minimization. Therefore, our method naturally combines the age classification and regression approaches, which enhances the robustness of our method. We conduct experiments on the public NIST SRE08-10 dataset and a real-world dataset, which exhibit that our method outperforms baseline methods by a relatively large margin, yielding a 10\% reduction in terms of mean absolute error (MAE) on a real-world dataset.
翻译:语言年龄估计的现有方法通常将它视为多级分类或回归问题。然而,精确年龄识别仍是一个挑战,因为标签含糊不清, \ emph{i.e.}, 同一人的相邻年龄的发音往往无法区分。 为了解决这个问题, 我们使用年龄标签之间的模糊信息, 将每个年龄标签转换为离散标签分布, 并利用标签分配学习方法来适应数据。 对于每个音频数据样本, 我们的方法产生其语言的年龄分布, 在分布之外, 我们还执行另外两项任务: 年龄预测和年龄不确定性最小化。 因此, 我们的方法自然将年龄分类和回归方法结合起来, 增强我们方法的稳健性。 我们在公共的 NIST SRE08- 10 数据集和真实世界数据集上进行实验, 这表明我们的方法比基线方法大一个边距, 使真实世界数据集中的平均绝对误差减少 10 ⁇ 。