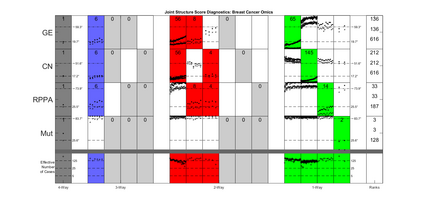
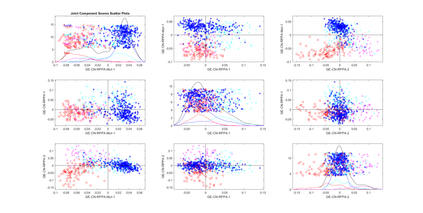
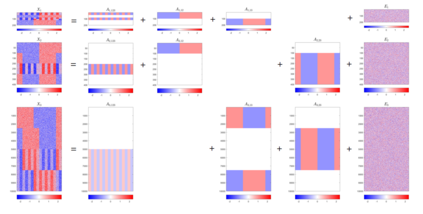
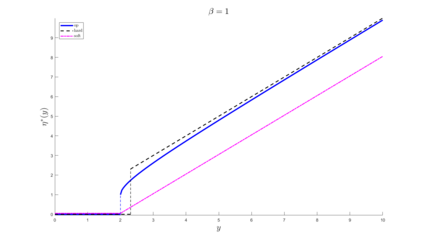
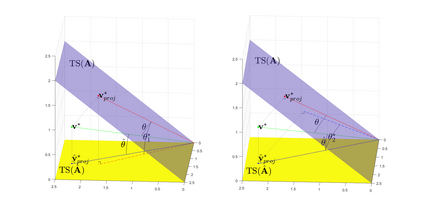
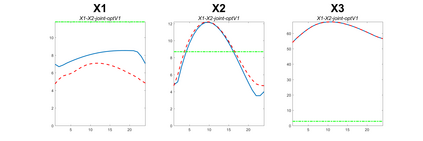
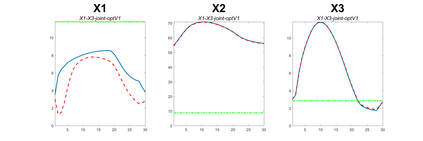
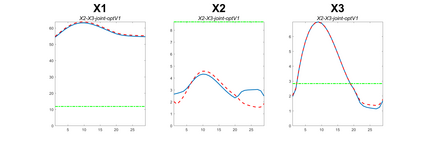
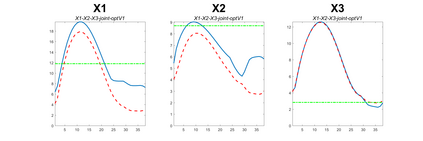
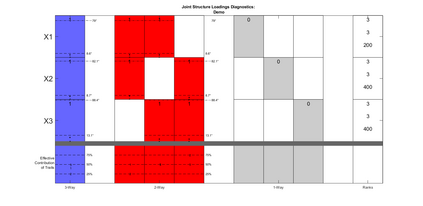
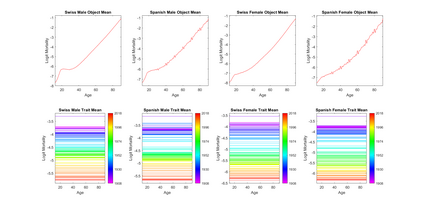
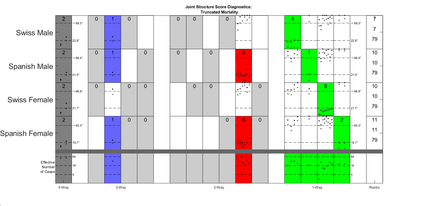
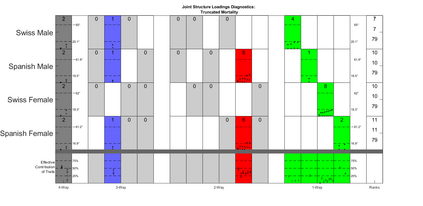
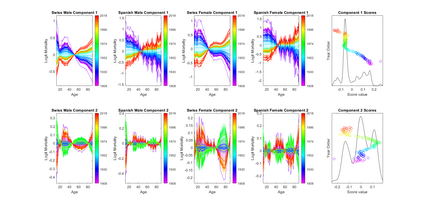
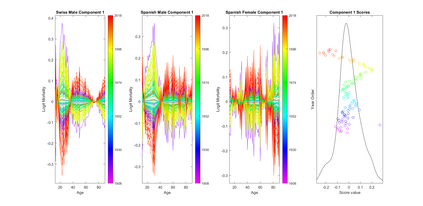
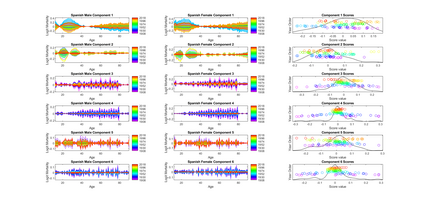
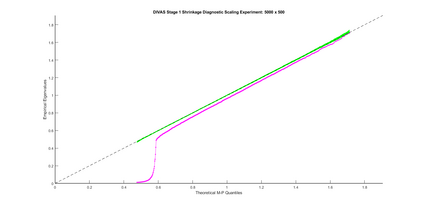
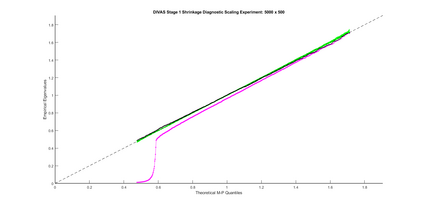
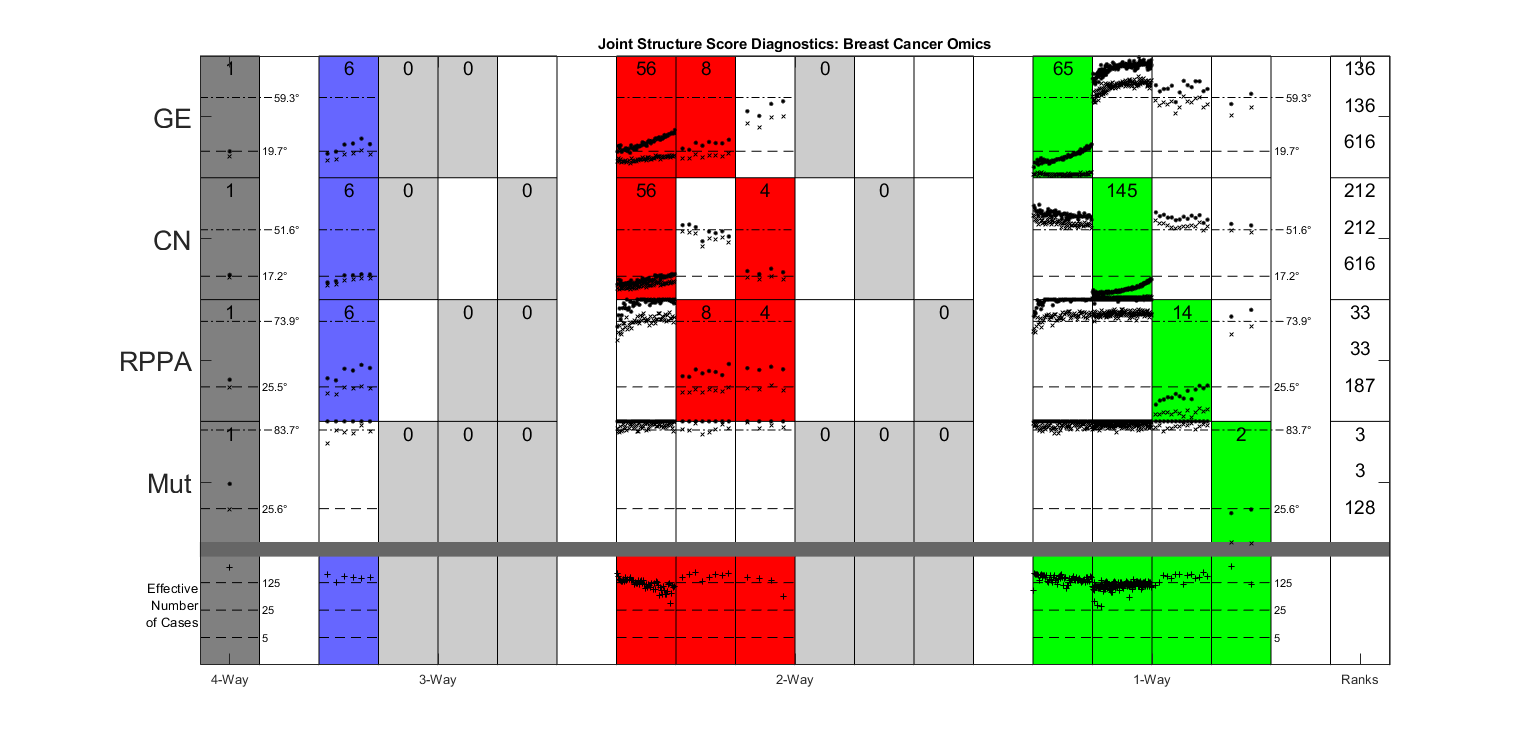
Modern data collection in many data paradigms, including bioinformatics, often incorporates multiple traits derived from different data types (i.e. platforms). We call this data multi-block, multi-view, or multi-omics data. The emergent field of data integration develops and applies new methods for studying multi-block data and identifying how different data types relate and differ. One major frontier in contemporary data integration research is methodology that can identify partially-shared structure between sub-collections of data types. This work presents a new approach: Data Integration Via Analysis of Subspaces (DIVAS). DIVAS combines new insights in angular subspace perturbation theory with recent developments in matrix signal processing and convex-concave optimization into one algorithm for exploring partially-shared structure. Based on principal angles between subspaces, DIVAS provides built-in inference on the results of the analysis, and is effective even in high-dimension-low-sample-size (HDLSS) situations.
翻译:现代数据收集在许多数据模式中,包括生物信息学,往往包含不同数据类型(即平台)产生的多重特征。我们称这些数据为多块数据、多视图数据或多组数据。数据整合的新兴领域开发并应用新方法研究多块数据并确定不同数据类型之间的关联和差异。当代数据整合研究的一个主要前沿是能够确定数据类型分集之间部分共享结构的方法。这项工作提出了一种新的方法:对子空间进行数据集成分析。DIVAS将三角次空间扰动理论中的新洞察力与矩阵信号处理和 convex凝聚优化的最新发展合并成一种算法,用于探索部分共享的结构。根据子空间之间的主要角度,DIVAS提供了分析结果的内在推论,甚至在高二成层低成像(HLSS)情况下也是有效的。