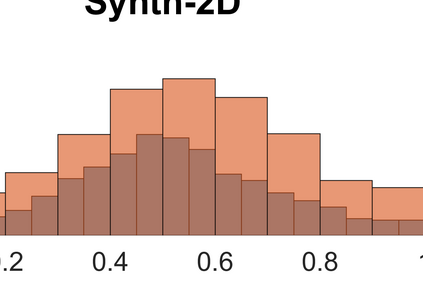
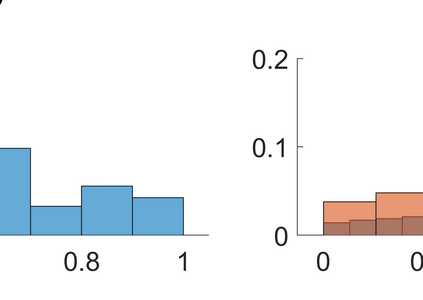
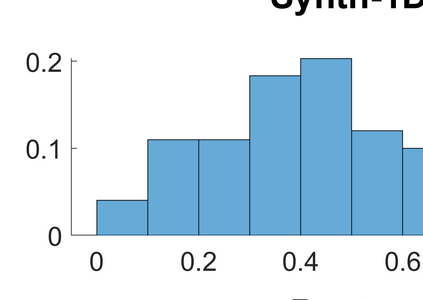
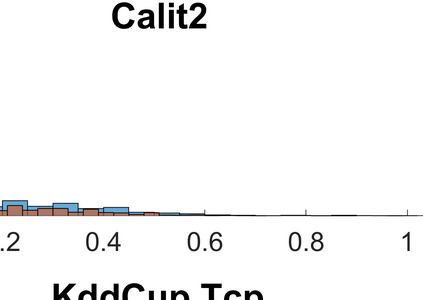
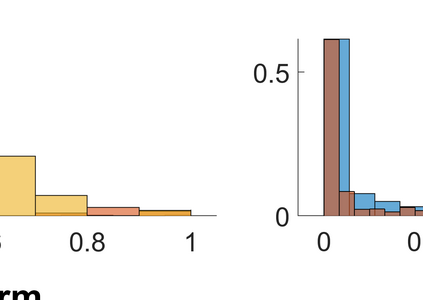
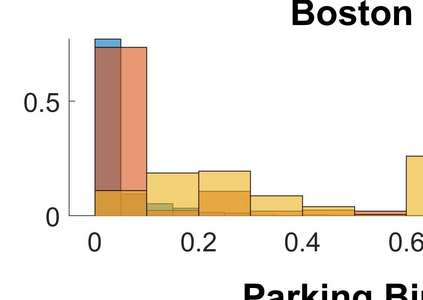
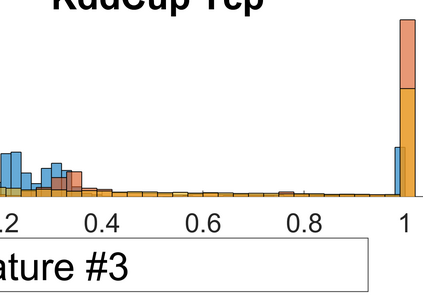
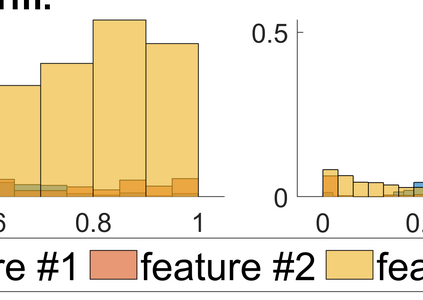
Both classification and regression tasks are susceptible to the biased distribution of training data. However, existing approaches are focused on the class-imbalanced learning and cannot be applied to the problems of numerical regression where the learning targets are continuous values rather than discrete labels. In this paper, we aim to improve the accuracy of the regression analysis by addressing the data skewness/bias during model training. We first introduce two metrics, uniqueness and abnormality, to reflect the localized data distribution from the perspectives of their feature (i.e., input) space and target (i.e., output) space. Combining these two metrics we propose a Variation-Incentive Loss re-weighting method (VILoss) to optimize the gradient descent-based model training for regression analysis. We have conducted comprehensive experiments on both synthetic and real-world data sets. The results show significant improvement in the model quality (reduction in error by up to 11.9%) when using VILoss as the loss criterion in training.
翻译:分类和回归任务都容易出现培训数据分布偏差的情况,但是,现有方法侧重于班级平衡学习,不能适用于数值回归问题,因为学习目标为连续值而不是离散标签。在本文件中,我们的目标是通过在模型培训期间处理数据偏差/偏差来提高回归分析的准确性。我们首先引入两个尺度,即独特性和异常性,从特征(即输入)空间和目标(即产出)空间的角度反映本地数据分布。我们建议采用这两种衡量尺度,以优化基于梯度的梯度下降模型培训,用于回归分析。我们在合成和真实世界数据集上进行了全面实验。结果显示,在使用VILos作为培训损失标准时,模型质量(误差减少至11.9%)有显著改善。