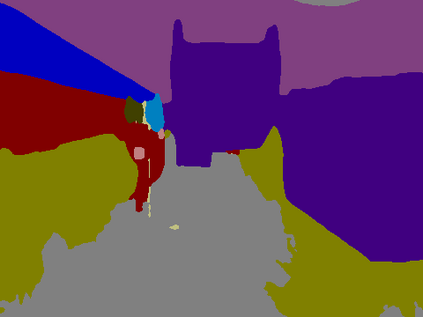
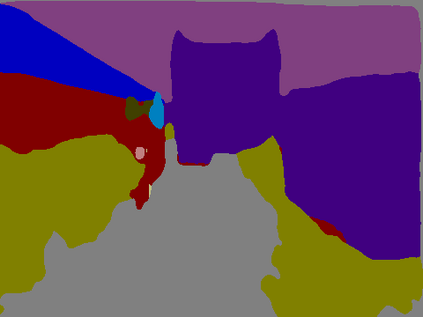
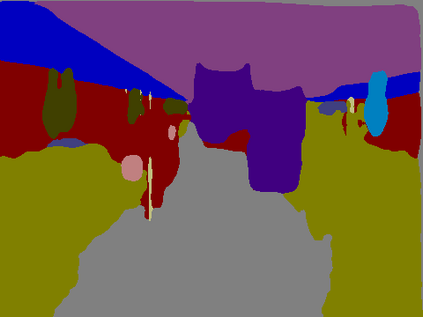
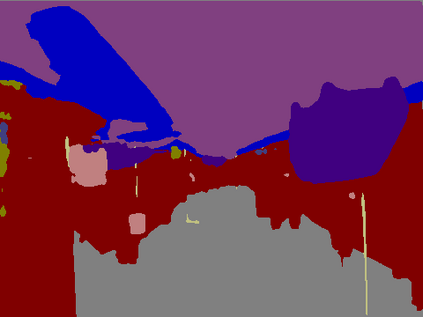
Recent breakthroughs in semantic segmentation methods based on Fully Convolutional Networks (FCNs) have aroused great research interest. One of the critical issues is how to aggregate multi-scale contextual information effectively to obtain reliable results. To address this problem, we propose a novel paradigm called the Chained Context Aggregation Module (CAM). CAM gains features of various spatial scales through chain-connected ladder-style information flows. The features are then guided by Flow Guidance Connections to interact and fuse in a two-stage process, which we refer to as pre-fusion and re-fusion. We further adopt attention models in CAM to productively recombine and select those fused features to refine performance. Based on these developments, we construct the Chained Context Aggregation Network (CANet), which employs a two-step decoder to recover precise spatial details of prediction maps. We conduct extensive experiments on three challenging datasets, including Pascal VOC 2012, CamVid and SUN-RGBD. Results evidence that our CANet achieves state-of-the-art performance. Codes will be available on the publication of this paper.
翻译:最近基于全面革命网络(FCNs)的语义分割方法的突破引起了极大的研究兴趣。一个关键问题是如何有效地汇总多尺度背景信息,以获得可靠的结果。为了解决这一问题,我们提出了一个叫“链环环境聚合模块”(CAM)的新模式。CAM通过连锁的阶梯式信息流动获得各种空间尺度的特征。这些特征随后以流程指导连接为指南,在两阶段进程中互动和融合,我们称之为融合前和再融合。我们进一步在CAM中采用关注模式,以便有效地整合多尺度背景信息,从而获得可靠的结果。我们根据这些发展,建立了链环环环境聚合网络(CANet),使用两步分解码来恢复准确的预测地图空间细节。我们就三个挑战性数据集进行了广泛的实验,包括Pascal VOC 2012、CamVid和SUN-RGBD。结果证据表明,我们的CANet取得了最新业绩。将在本文件的出版中提供代码。