
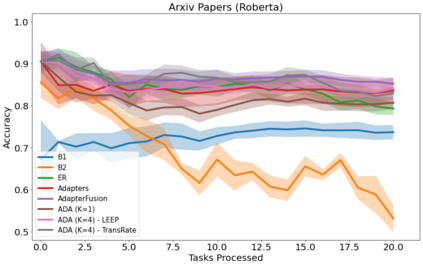
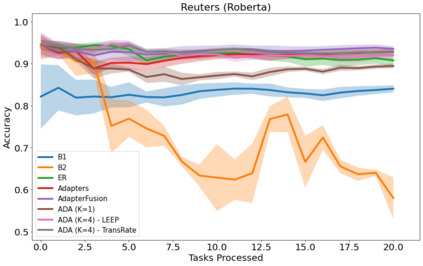
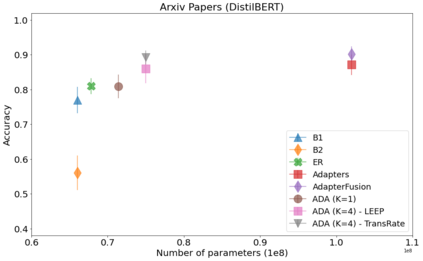
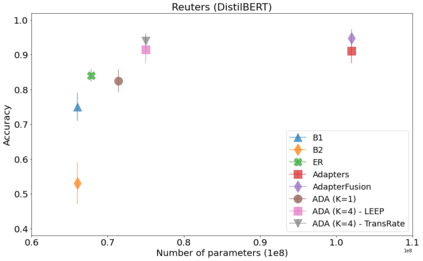
In many real-world scenarios, data to train machine learning models becomes available over time. Unfortunately, these models struggle to continually learn new concepts without forgetting what has been learnt in the past. This phenomenon is known as catastrophic forgetting and it is difficult to prevent due to practical constraints. For instance, the amount of data that can be stored or the computational resources that can be used might be limited. Moreover, applications increasingly rely on large pre-trained neural networks, such as pre-trained Transformers, since the resources or data might not be available in sufficiently large quantities to practitioners to train the model from scratch. In this paper, we devise a method to incrementally train a model on a sequence of tasks using pre-trained Transformers and extending them with Adapters. Different than the existing approaches, our method is able to scale to a large number of tasks without significant overhead and allows sharing information across tasks. On both image and text classification tasks, we empirically demonstrate that our method maintains a good predictive performance without retraining the model or increasing the number of model parameters over time. The resulting model is also significantly faster at inference time compared to Adapter-based state-of-the-art methods.
翻译:在许多现实世界的情景中,培训机器学习模型的数据随时间推移而出现。 不幸的是,这些模型在不断学习新概念的同时却不忘过去所学过的东西。 这种现象被称为灾难性的遗忘,由于实际限制,难以预防。 例如,可以储存的数据数量或可以使用的计算资源可能有限。 此外,应用日益依赖大型的训练前神经网络,如预先培训的变异器,因为从零开始培训模型的从业人员可能得不到足够大的数量的资源或数据。 在本文中,我们设计了一种方法,逐步培训一个使用预先培训的变异器的任务序列模型,并将这些模型与适应器加以扩展。与现有方法不同,我们的方法能够在没有重大间接费用的情况下将大量任务推广到可以共享任务。 在图像和文本分类任务方面,我们从经验上证明,我们的方法保持良好的预测性性能,而没有再培训模型或随着时间的推移增加模型参数的数量。 所产生的模型在推论时间上比以适应者为基础的状态方法要快得多。






相关内容

Source: Apple - iOS 8


