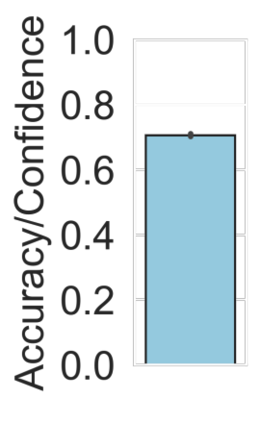
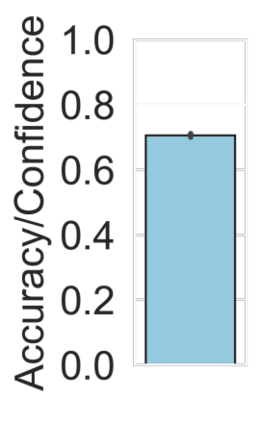
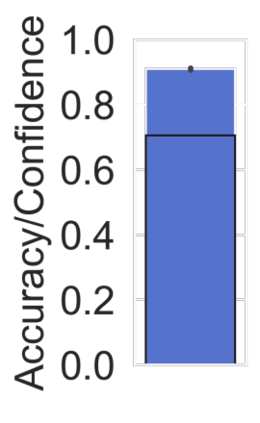
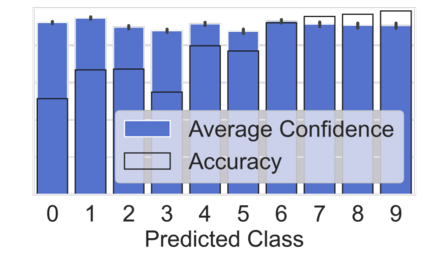
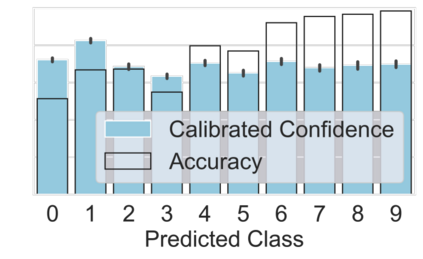
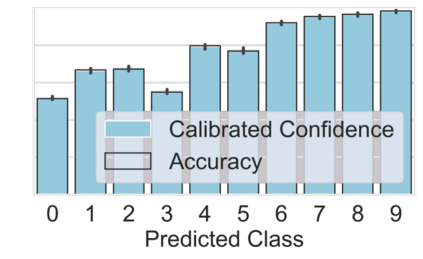
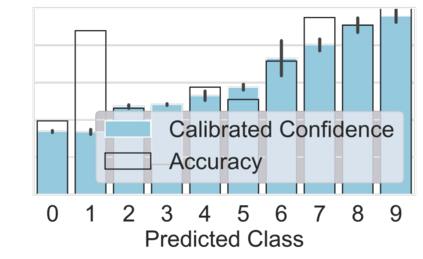
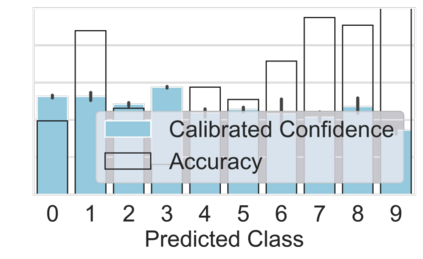
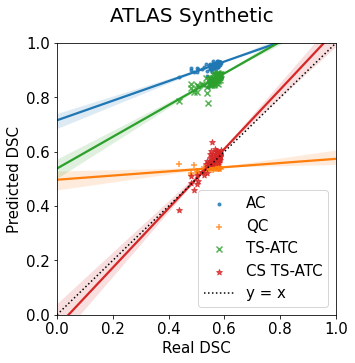
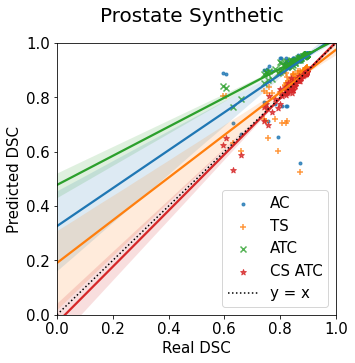
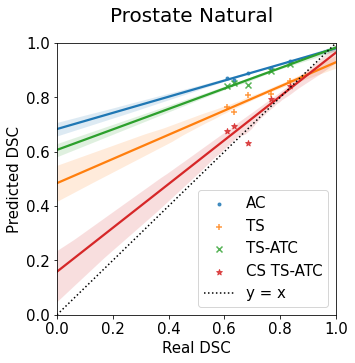
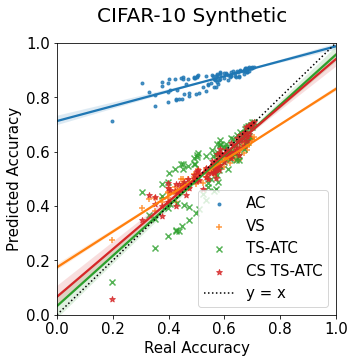
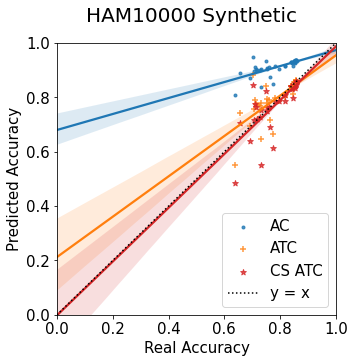
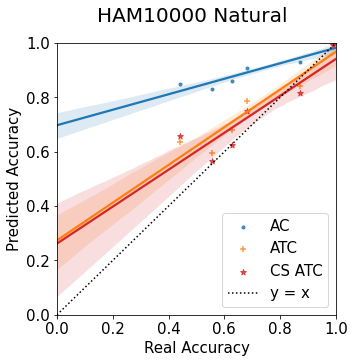
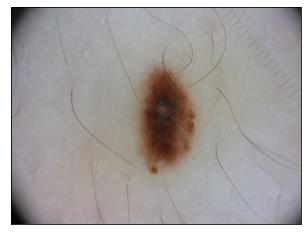
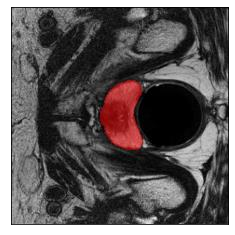
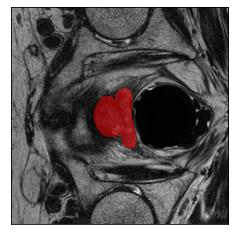
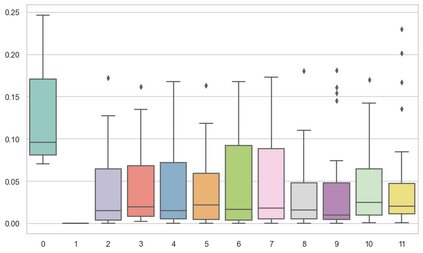
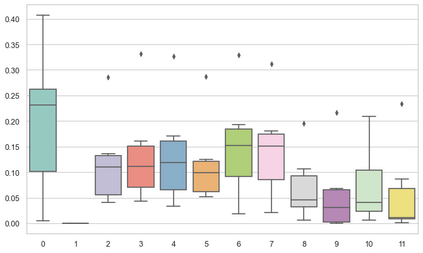
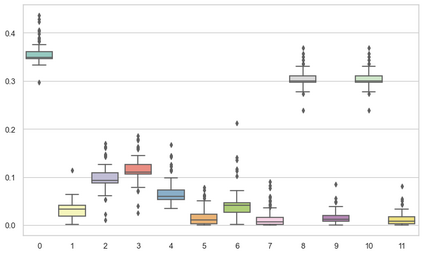
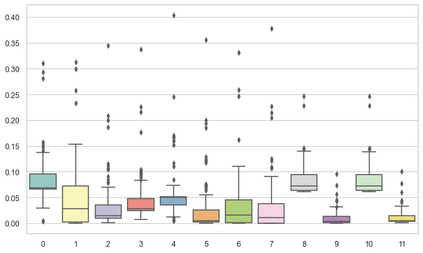
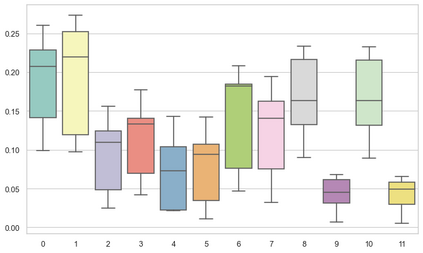
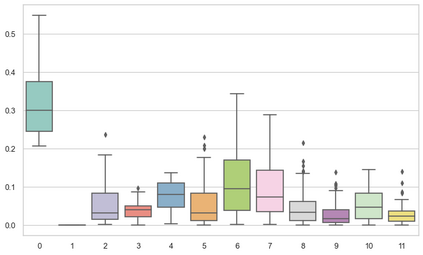
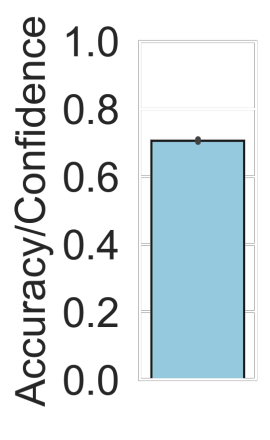
Machine learning models are typically deployed in a test setting that differs from the training setting, potentially leading to decreased model performance because of domain shift. If we could estimate the performance that a pre-trained model would achieve on data from a specific deployment setting, for example a certain clinic, we could judge whether the model could safely be deployed or if its performance degrades unacceptably on the specific data. Existing approaches estimate this based on the confidence of predictions made on unlabeled test data from the deployment's domain. We find existing methods struggle with data that present class imbalance, because the methods used to calibrate confidence do not account for bias induced by class imbalance, consequently failing to estimate class-wise accuracy. Here, we introduce class-wise calibration within the framework of performance estimation for imbalanced datasets. Specifically, we derive class-specific modifications of state-of-the-art confidence-based model evaluation methods including temperature scaling (TS), difference of confidences (DoC), and average thresholded confidence (ATC). We also extend the methods to estimate Dice similarity coefficient (DSC) in image segmentation. We conduct experiments on four tasks and find the proposed modifications consistently improve the estimation accuracy for imbalanced datasets. Our methods improve accuracy estimation by 18\% in classification under natural domain shifts, and double the estimation accuracy on segmentation tasks, when compared with prior methods.
翻译:机械学习模型通常在不同于培训设置的测试环境中部署,可能会导致因域变换而降低模型性能。如果我们能够估计一个经过预先训练的模型在特定部署环境(例如某个诊所)的数据上能够实现的性能,我们可以判断该模型能否安全部署,或者该模型的性能在具体数据上降低令人无法接受。现有办法根据对未贴标签的测试数据与部署领域相比的预测的可信度来估计。我们发现,现有方法与目前类别不平衡的数据存在矛盾,因为用于校准信心的方法没有考虑到因阶级不平衡造成的偏差,因此无法估计等级准确性。在这里,我们在对不平衡数据集的性能估计框架内引入了等级性校准。具体地说,我们对基于信任的状态模型评价方法,包括温度缩放(TS)、信任差异(DoC)和平均临界信任(ATC)等,进行了估算。我们还扩大了在图像分割中估算Dice相似性系数(DSC)时所使用的方法。我们在四个任务上进行实验,并发现在对不平衡的数据集进行持续调整时,在18项之前的精确性估算方法下,在改进了我们的自然域的精确性估算。