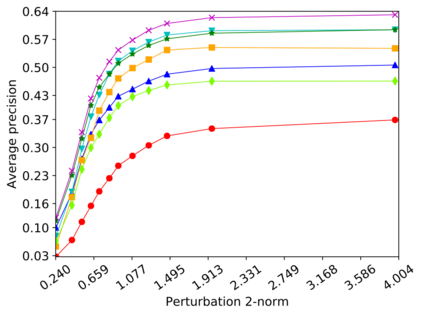
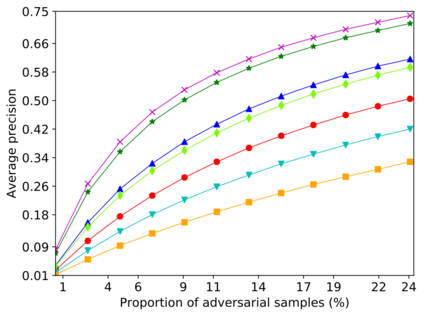
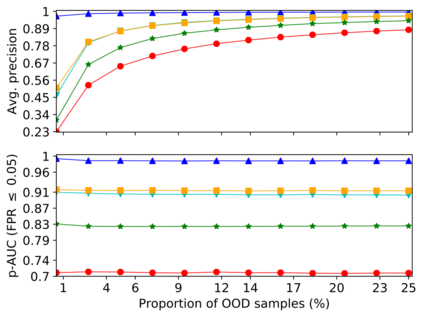
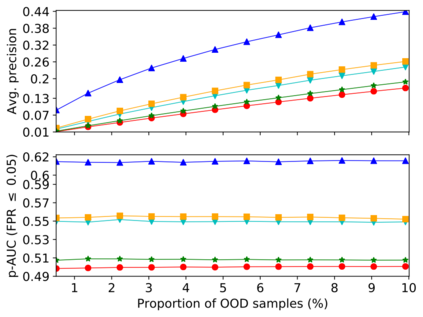
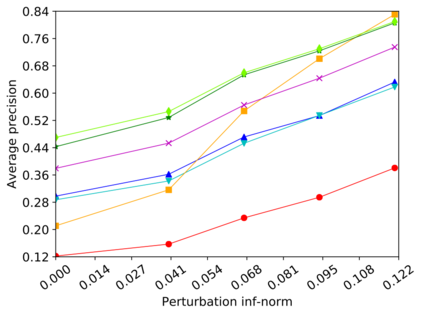
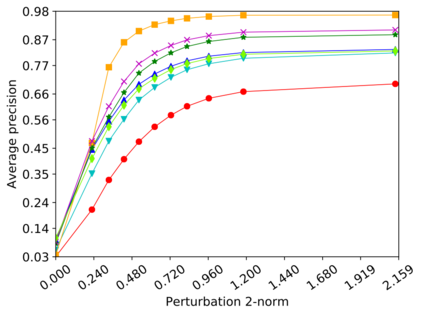
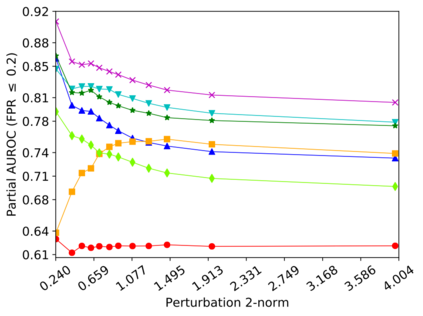
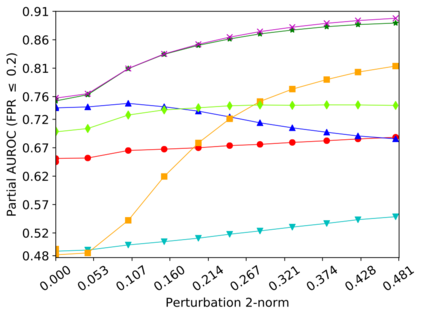
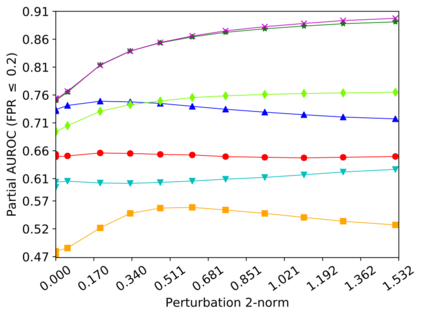
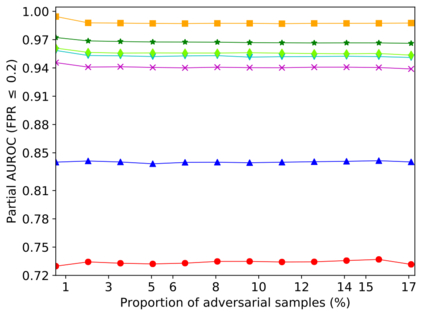
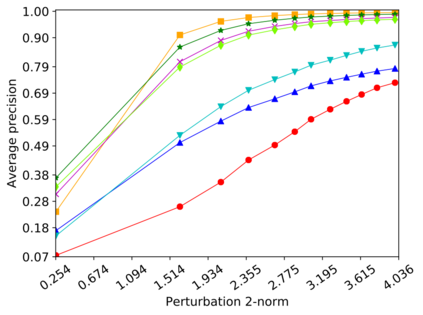
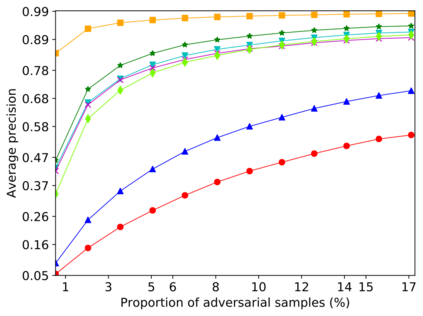
Detecting anomalous inputs, such as adversarial and out-of-distribution (OOD) inputs, is critical for classifiers (including deep neural networks or DNNs) deployed in real-world applications. While prior works have proposed various methods to detect such anomalous samples using information from the internal layer representations of a DNN, there is a lack of consensus on a principled approach for the different components of such a detection method. As a result, often heuristic and one-off methods are applied for different aspects of this problem. We propose an unsupervised anomaly detection framework based on the internal DNN layer representations in the form of a meta-algorithm with configurable components. We proceed to propose specific instantiations for each component of the meta-algorithm based on ideas grounded in statistical testing and anomaly detection. We evaluate the proposed methods on well-known image classification datasets with strong adversarial attacks and OOD inputs, including an adaptive attack that uses the internal layer representations of the DNN (often not considered in prior work). Comparisons with five recently-proposed competing detection methods demonstrates the effectiveness of our method in detecting adversarial and OOD inputs.
翻译:在现实世界应用中部署的分类器(包括深神经网络或DNNs),关键是检测反常投入,如对抗性和分配(OOOD)投入等反常投入,虽然先前的工作提出了利用DNN内部结构中的信息,利用DNN内部结构中的信息检测此类反常样本的各种方法,但对这种检测方法不同组成部分的原则方法缺乏共识,因此,对该问题的不同方面往往采用惯用和一次性的方法。我们提议以DNND内部结构表象为形式,以可配置组件的元水平为形式,建立不受监督的异常检测框架。我们着手根据基于统计测试和异常检测的想法,为元水平的每个组成部分提出具体的直截率。我们评估了关于具有强烈对抗性攻击和OOOD投入的众所周知的图像分类数据集的拟议方法,包括使用DNN的内部结构图象的适应性攻击(以前的工作通常不考虑)。我们与最近提出的五种竞合检测方法进行比较,以表明我们在检测方法中的对抗性研究方式的有效性。