
题目: PolyGen: An Autoregressive Generative Model of 3D Meshes
摘要:
多边形网格是三维几何的一种有效表现形式,在计算机图形学、机器人技术和游戏开发中具有重要意义。现有的基于学习的方法避免了使用3D网格的挑战,而是使用与神经结构和训练方法更兼容的替代对象表示。提出了一种直接对网格建模的方法,利用基于变换的结构对网格顶点和面进行顺序预测。我们的模型可以对一系列输入进行条件设置,包括类对象、体素和图像,因为模型是概率性的,所以它可以生成在模糊场景中捕获不确定性的样本。我们证明了该模型能够产生高质量、可用的网格,并为网格建模任务建立了对数似然基准。我们还根据不同的方法评估了表面重建的条件模型,并在没有直接训练的情况下展示了竞争性的表现。
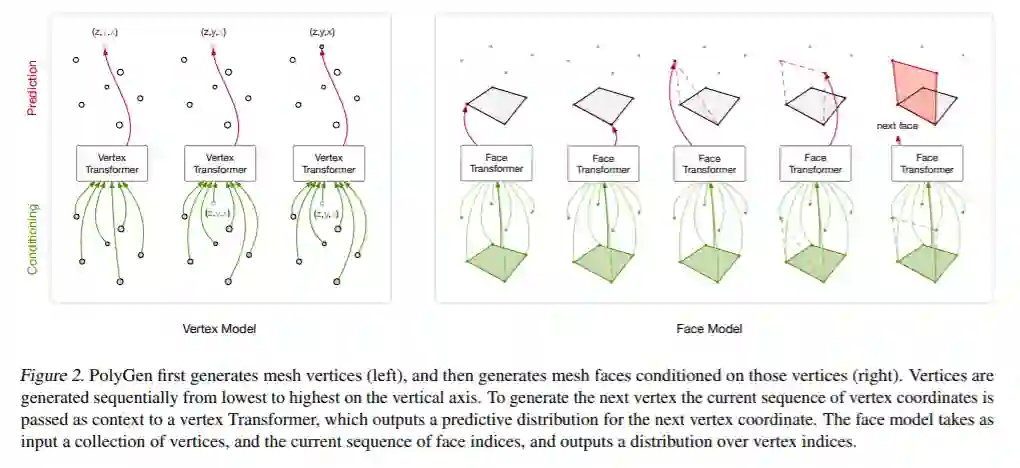
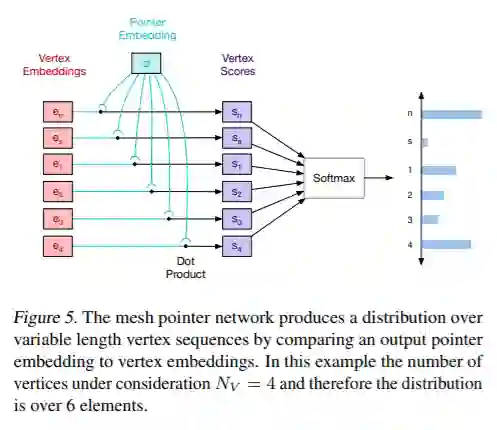
成为VIP会员查看完整内容
相关内容

专知会员服务
28+阅读 · 2020年2月20日
专知会员服务
11+阅读 · 2019年12月28日
相关主题


相关VIP内容
专知会员服务
28+阅读 · 2020年2月20日
专知会员服务
11+阅读 · 2019年12月28日
相关资讯
相关论文