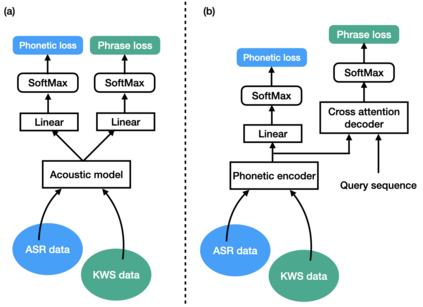
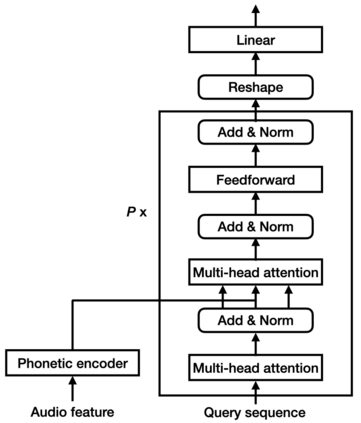
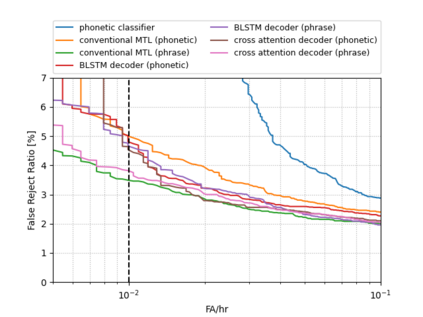
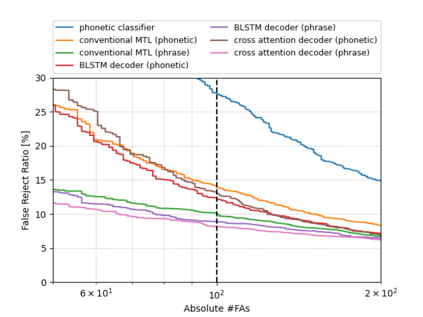
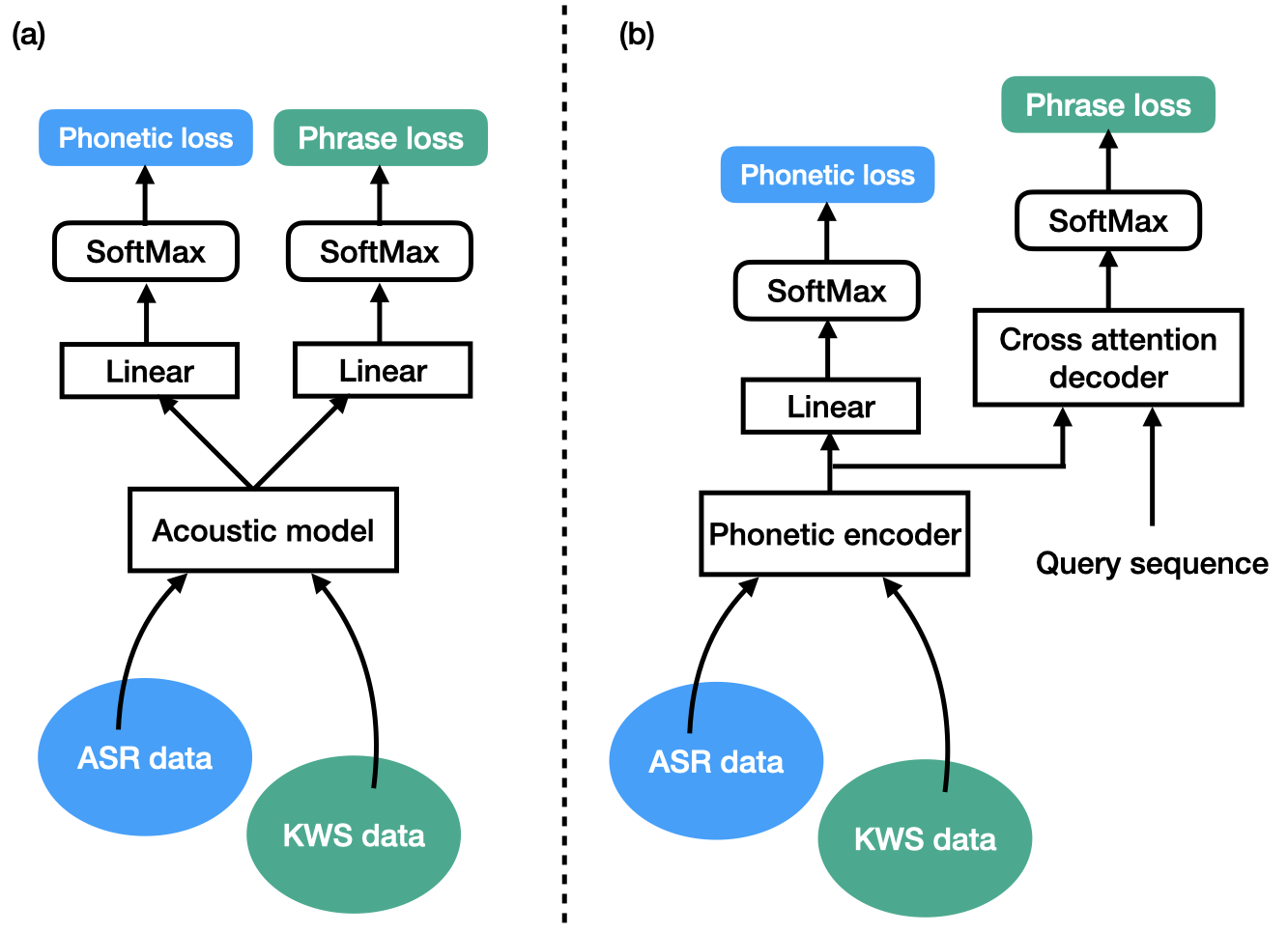
Keyword spotting (KWS) is an important technique for speech applications, which enables users to activate devices by speaking a keyword phrase. Although a phoneme classifier can be used for KWS, exploiting a large amount of transcribed data for automatic speech recognition (ASR), there is a mismatch between the training criterion (phoneme recognition) and the target task (KWS). Recently, multi-task learning has been applied to KWS to exploit both ASR and KWS training data. In this approach, an output of an acoustic model is split into two branches for the two tasks, one for phoneme transcription trained with the ASR data and one for keyword classification trained with the KWS data. In this paper, we introduce a cross attention decoder in the multi-task learning framework. Unlike the conventional multi-task learning approach with the simple split of the output layer, the cross attention decoder summarizes information from a phonetic encoder by performing cross attention between the encoder outputs and a trainable query sequence to predict a confidence score for the KWS task. Experimental results on KWS tasks show that the proposed approach achieves a 12% relative reduction in the false reject ratios compared to the conventional multi-task learning with split branches and a bi-directional long short-team memory decoder.
翻译:关键字定位( KWS) 是语言应用的一个重要技术, 使用户能够通过使用关键词句激活设备。 虽然可以使用电话网分类器来使用电话网分类器, 将大量转录数据用于自动语音识别( ASR), 但培训标准( 电话识别) 与目标任务( KWS) 之间存在不匹配。 最近, 多任务学习被应用到 KWS, 以利用 ASR 和 KWS 培训数据。 在这种方法中, 音频模型的输出被分为两个分支, 一个是用ASR 数据培训的电话转录, 一个是用 KWS 数据培训的关键词分类。 在本文中, 我们引入了多任务学习框架中的交叉注意解码器。 与传统的多任务学习方法( 电话识别) 和目标任务任务( KWS) 之间的简单分割不同, 多任务解析器通过在编码输出和可训练的查询序列中进行交叉关注, 以预测 KWS 任务的信任分数。 KWS 短任务上的实验结果显示, 短程任务中的拟议方法在多任务中, 将实现长期的常规学习比例为12 。