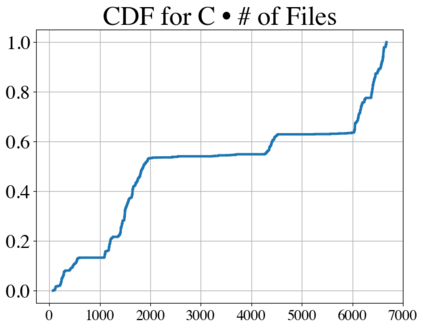
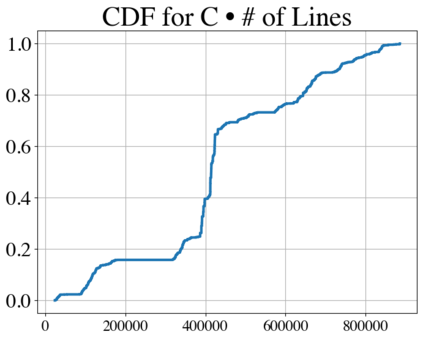
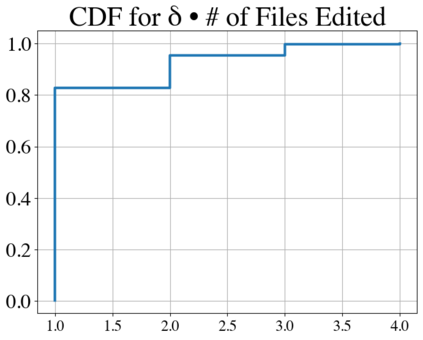
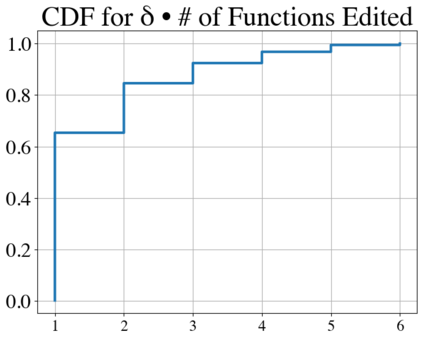
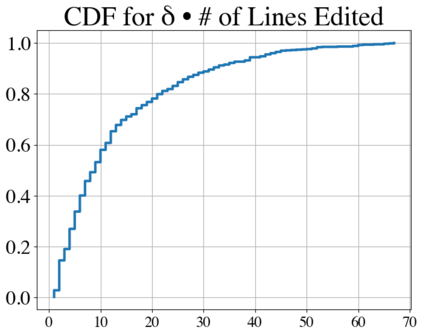
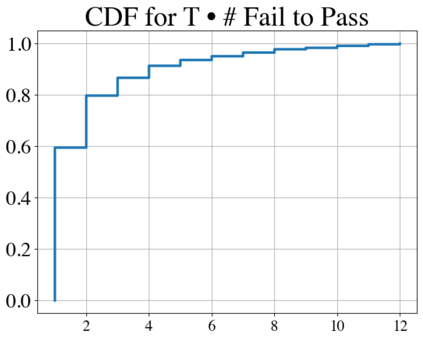
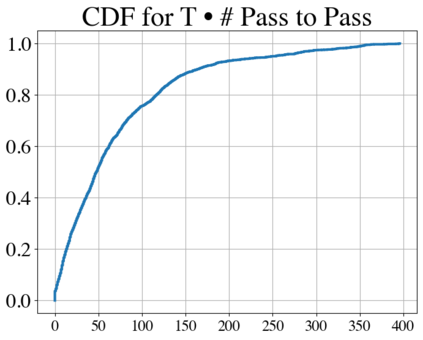
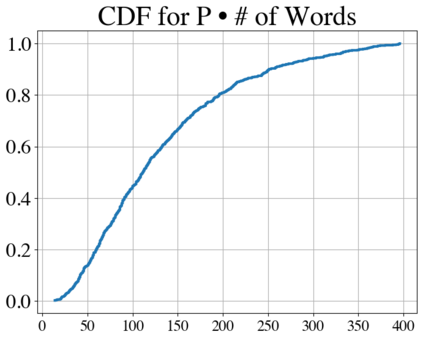
Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We consider real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. We therefore introduce SWE-bench, an evaluation framework including $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. Claude 2 and GPT-4 solve a mere $4.8$% and $1.7$% of instances respectively, even when provided with an oracle retriever. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
翻译:暂无翻译