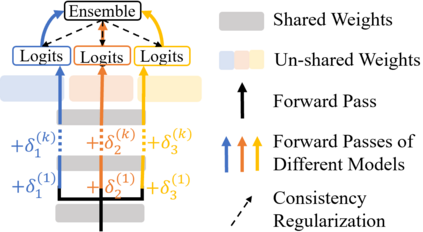
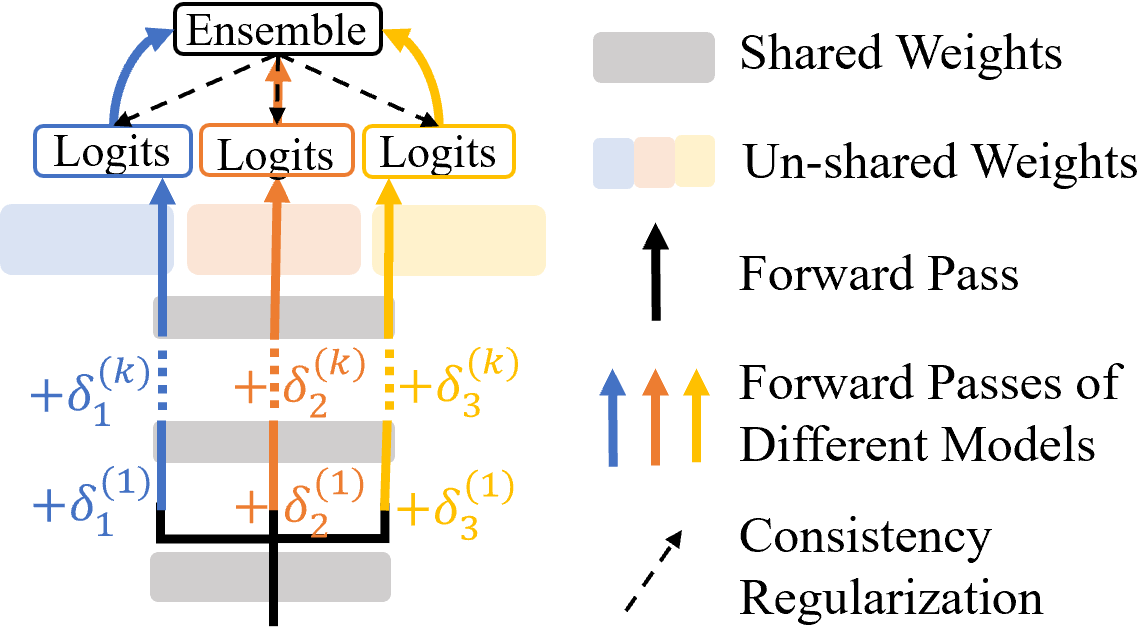
Model ensemble is a popular approach to produce a low-variance and well-generalized model. However, it induces large memory and inference costs, which are often not affordable for real-world deployment. Existing work has resorted to sharing weights among models. However, when increasing the proportion of the shared weights, the resulting models tend to be similar, and the benefits of using model ensemble diminish. To retain ensemble benefits while maintaining a low memory cost, we propose a consistency-regularized ensemble learning approach based on perturbed models, named CAMERO. Specifically, we share the weights of bottom layers across all models and apply different perturbations to the hidden representations for different models, which can effectively promote the model diversity. Meanwhile, we apply a prediction consistency regularizer across the perturbed models to control the variance due to the model diversity. Our experiments using large language models demonstrate that CAMERO significantly improves the generalization performance of the ensemble model. Specifically, CAMERO outperforms the standard ensemble of 8 BERT-base models on the GLUE benchmark by 0.7 with a significantly smaller model size (114.2M vs. 880.6M).
翻译:模型组合是一种流行的方法,可以产生一种低差异和广度的模型,然而,它却引起大量的记忆和推断成本,而这种成本往往无法为现实世界的部署所负担得起。现有的工作已经采用在模型之间分享权重的办法。但是,当提高共享权重的比例时,所产生的模型往往相似,使用模型组合减少的好处也相似。为了保留共同效益,同时保持低记忆成本,我们提议一种一致性和常规化的混合学习方法。具体地说,我们在所有模型中分享底层的重量,对不同模型的隐藏表示采用不同的扰动,这可以有效地促进模型的多样性。与此同时,我们采用一个预测一致性的固定化器,在受扰动的模型中控制因模型多样性而产生的差异。我们使用大语言模型的实验表明,CAMRO在保持低记忆成本的同时,大大改进了混合模型的通用性表现。具体地说,CAMERO在所有模型中比8个BER-80基准模型的标准型号要高得多。(GLUE,以0.7为基准,比GER-80M,比GLU。