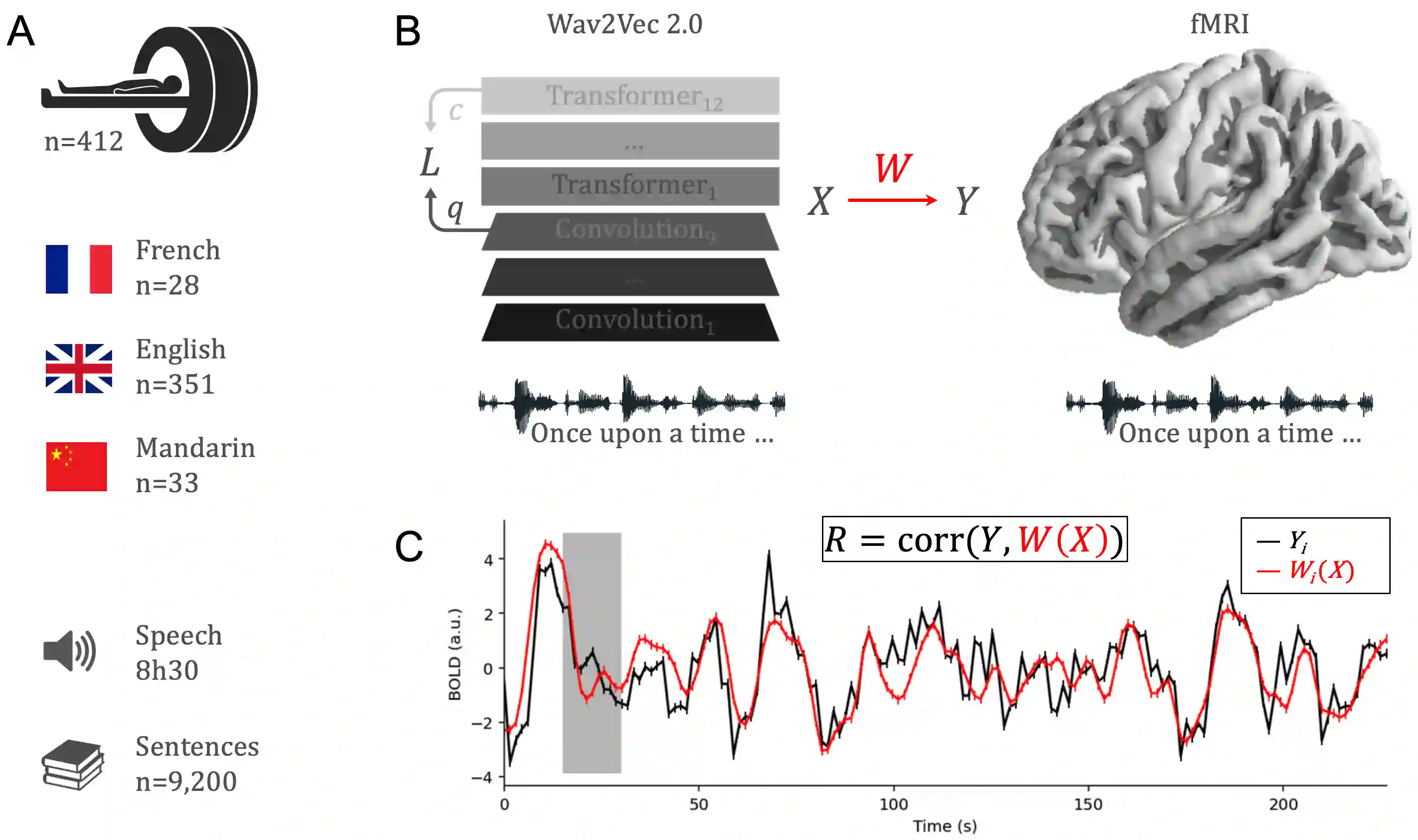
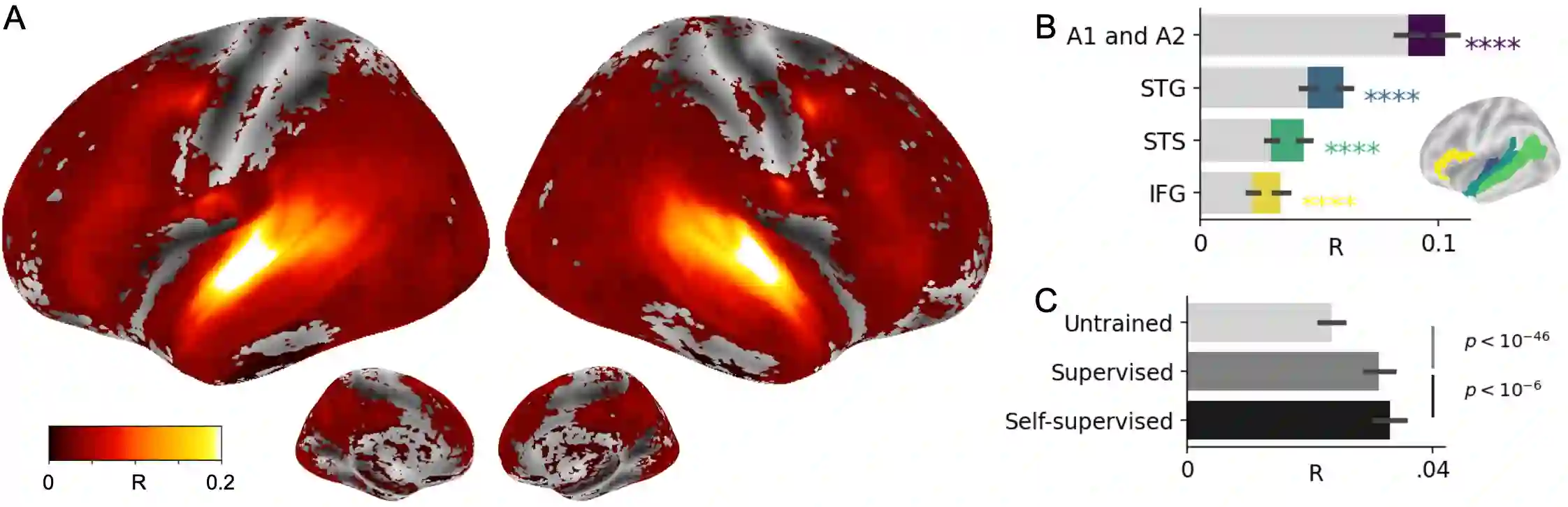
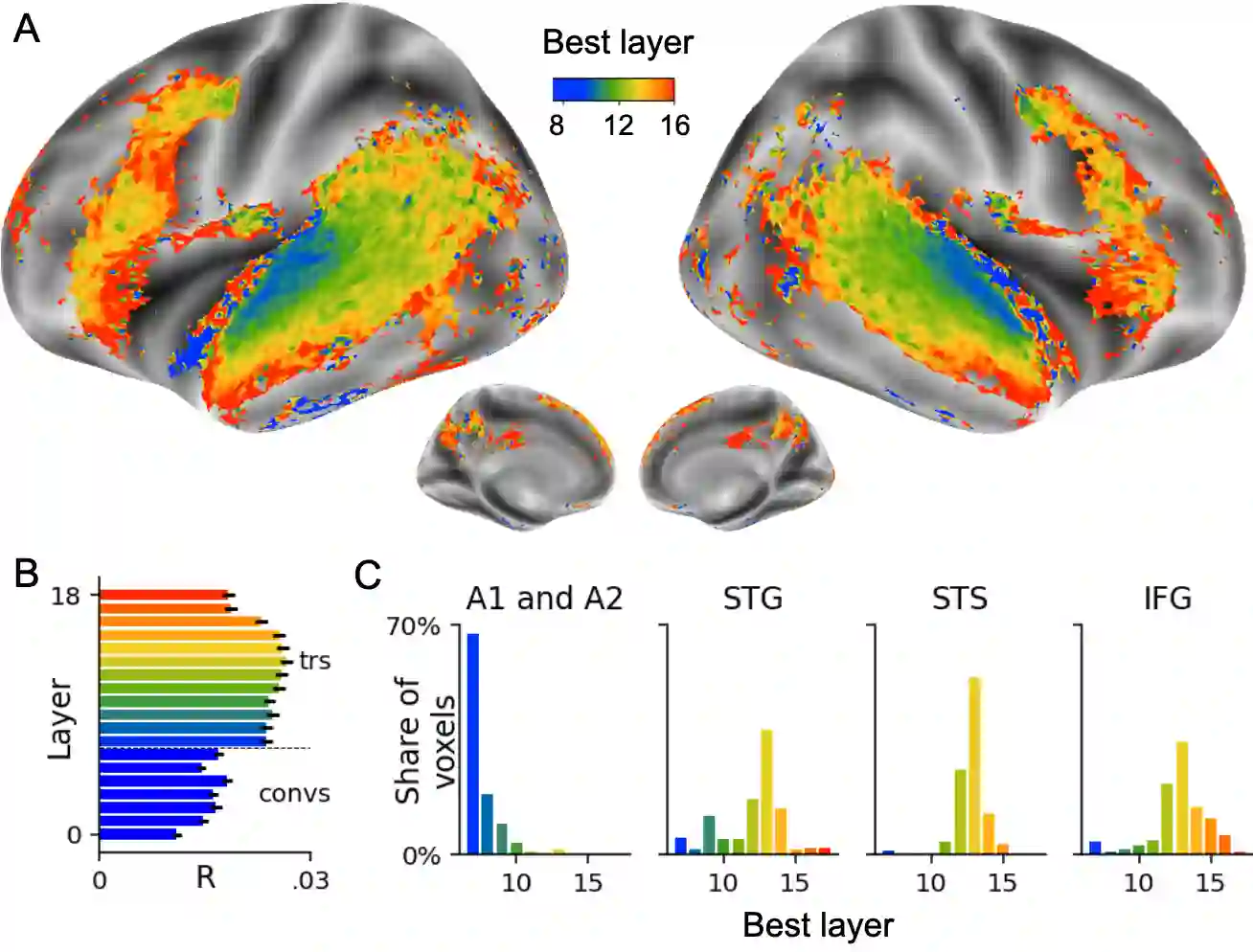
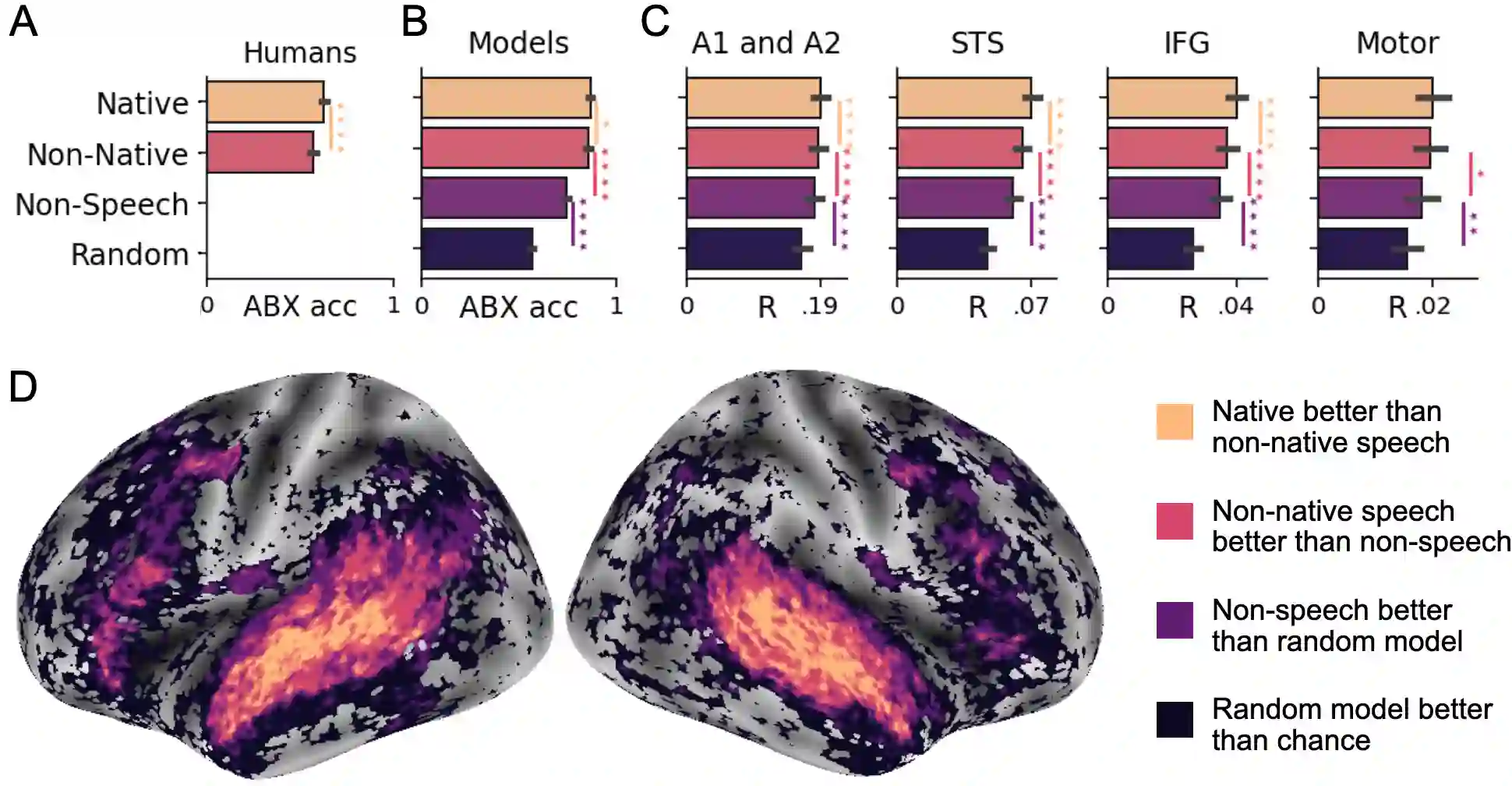
Several deep neural networks have recently been shown to generate activations similar to those of the brain in response to the same input. These algorithms, however, remain largely implausible: they require (1) extraordinarily large amounts of data, (2) unobtainable supervised labels, (3) textual rather than raw sensory input, and / or (4) implausibly large memory (e.g. thousands of contextual words). These elements highlight the need to identify algorithms that, under these limitations, would suffice to account for both behavioral and brain responses. Focusing on the issue of speech processing, we here hypothesize that self-supervised algorithms trained on the raw waveform constitute a promising candidate. Specifically, we compare a recent self-supervised architecture, Wav2Vec 2.0, to the brain activity of 412 English, French, and Mandarin individuals recorded with functional Magnetic Resonance Imaging (fMRI), while they listened to ~1h of audio books. Our results are four-fold. First, we show that this algorithm learns brain-like representations with as little as 600 hours of unlabelled speech -- a quantity comparable to what infants can be exposed to during language acquisition. Second, its functional hierarchy aligns with the cortical hierarchy of speech processing. Third, different training regimes reveal a functional specialization akin to the cortex: Wav2Vec 2.0 learns sound-generic, speech-specific and language-specific representations similar to those of the prefrontal and temporal cortices. Fourth, we confirm the similarity of this specialization with the behavior of 386 additional participants. These elements, resulting from the largest neuroimaging benchmark to date, show how self-supervised learning can account for a rich organization of speech processing in the brain, and thus delineate a path to identify the laws of language acquisition which shape the human brain.
翻译:最近一些深心神经网络被显示产生类似于大脑的激活,以回应同样的输入。然而,这些算法在很大程度上仍然难以令人信服:它们需要 (1) 超乎寻常的大量数据, (2) 无法获取的监管标签, (3) 文本而非原始感官输入, 以及 / 或 (4) 令人难以置信的大记忆( 例如, 上千个背景字) 。 这些元素突出表明, 需要找出算法, 在这些限制下, 足以同时说明行为和大脑反应。 侧重于语言处理问题, 我们在这里假设, 在原始波形上训练的自我监督的算法构成一个充满希望的候选者。 具体而言, 我们比较了最近的自我监督结构结构, 2 文本, 而不是原始感官感知的感官输入, 312 个英语、 法语和曼达林的个人脑活动, 记录了磁力振荡感应前( fMRI), 同时他们听了 my1hh 语音书, 我们的成绩是4倍。 首先, 我们显示这个算法学会了大脑的表达方式, 其获取日期, 以近600小时的大脑表达方式, 直观, 直观的直观, 和直观的大脑表达式结构结构结构结构结构结构 。