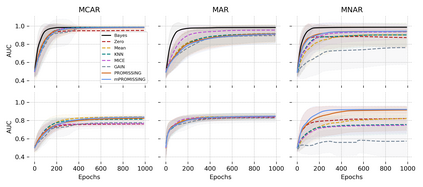
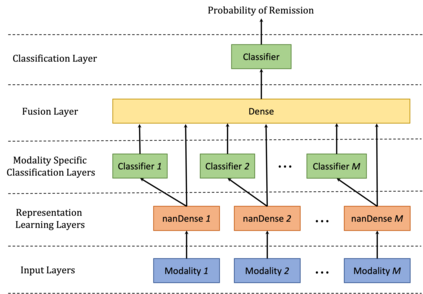
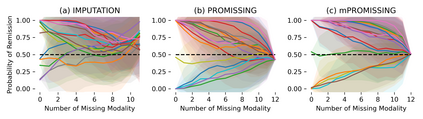
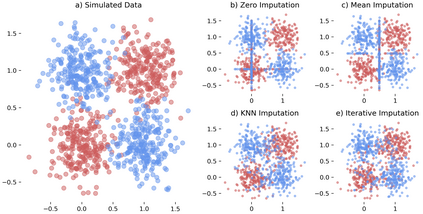
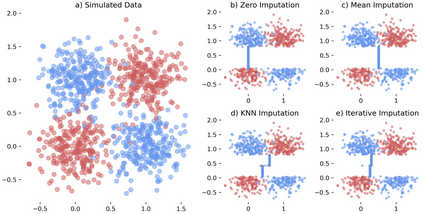
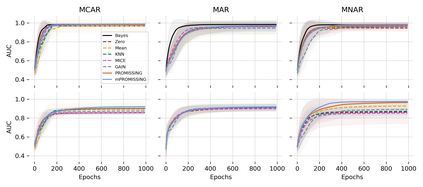
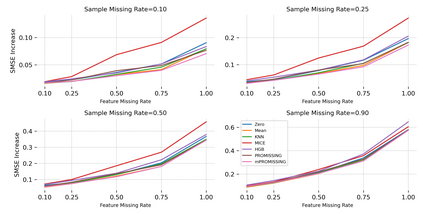
While data are the primary fuel for machine learning models, they often suffer from missing values, especially when collected in real-world scenarios. However, many off-the-shelf machine learning models, including artificial neural network models, are unable to handle these missing values directly. Therefore, extra data preprocessing and curation steps, such as data imputation, are inevitable before learning and prediction processes. In this study, we propose a simple and intuitive yet effective method for pruning missing values (PROMISSING) during learning and inference steps in neural networks. In this method, there is no need to remove or impute the missing values; instead, the missing values are treated as a new source of information (representing what we do not know). Our experiments on simulated data, several classification and regression benchmarks, and a multi-modal clinical dataset show that PROMISSING results in similar prediction performance compared to various imputation techniques. In addition, our experiments show models trained using PROMISSING techniques are becoming less decisive in their predictions when facing incomplete samples with many unknowns. This finding hopefully advances machine learning models from being pure predicting machines to more realistic thinkers that can also say "I do not know" when facing incomplete sources of information.
翻译:虽然数据是机器学习模型的主要燃料,但数据往往缺乏价值,特别是在现实世界情景中收集的数据;然而,许多现成的机器学习模型,包括人工神经网络模型,无法直接处理这些缺失的值。因此,在学习和预测过程之前,额外的数据处理前和曲线步骤,如数据估算等,是不可避免的。在本研究中,我们提出了一个简单和直观的、有效的方法,用于在神经网络的学习和推断步骤中计算缺失值(Promissing)。在这种方法中,没有必要删除或浸透缺失的数值;相反,缺失的数值被当作新的信息来源(代表我们不知道的)。我们在模拟数据、若干分类和回归基准以及多模式临床数据集方面的实验表明,与各种浸透技术相比,Promissing在类似的预测性能(Promissing ) 显示,在面对许多未知的不完整样本时,经过培训的模型在预测中变得不那么具有决定性。这一方法是希望的先进机器学习模型,在面临精密的机器时,“更现实的预测源时,”会说,“在面对纯粹的机器时会发现”不完全地预测时,“不完全的机器的源”会说,这样说: