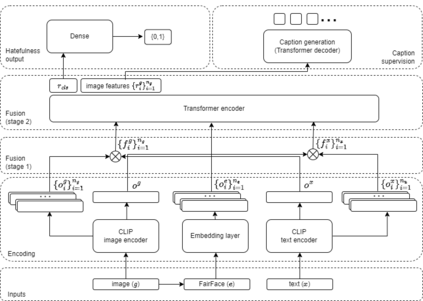
Hate speech is a societal problem that has significantly grown through the Internet. New forms of digital content such as image memes have given rise to spread of hate using multimodal means, being far more difficult to analyse and detect compared to the unimodal case. Accurate automatic processing, analysis and understanding of this kind of content will facilitate the endeavor of hindering hate speech proliferation through the digital world. To this end, we propose MemeFier, a deep learning-based architecture for fine-grained classification of Internet image memes, utilizing a dual-stage modality fusion module. The first fusion stage produces feature vectors containing modality alignment information that captures non-trivial connections between the text and image of a meme. The second fusion stage leverages the power of a Transformer encoder to learn inter-modality correlations at the token level and yield an informative representation. Additionally, we consider external knowledge as an additional input, and background image caption supervision as a regularizing component. Extensive experiments on three widely adopted benchmarks, i.e., Facebook Hateful Memes, Memotion7k and MultiOFF, indicate that our approach competes and in some cases surpasses state-of-the-art. Our code is available on https://github.com/ckoutlis/memefier.
翻译:仇恨言论是通过互联网显著增长的社会问题。新的数字内容形式,例如图像Meme,通过多模态手段传播仇恨,与单模态情况相比更难分析和检测。准确的自动处理,分析和理解这种内容将有助于通过数字世界阻止仇恨言论的传播。为此,我们提出了MemeFier,这是一种基于深度学习的架构,用于对互联网图像Meme进行精细分类,利用双阶段模态融合模块。第一个融合阶段产生包含模态对齐信息的特征向量,捕捉Meme的文本和图像之间的非平凡联系。第二个融合阶段利用Transformer编码器的威力在标记级别上学习模态间相关性,并产生一个信息丰富的表示。此外,我们考虑外部知识作为附加输入,并将背景图像标题监督作为正则化组件。在Facebook仇恨Memes,Memotion7k和MultiOFF等三个广泛采用的基准测试上的广泛实验表明,我们的方法与现有技术相竞争,在某些情况下超过了现有技术水平。我们的代码可在https://github.com/ckoutlis/memefier上获得。